
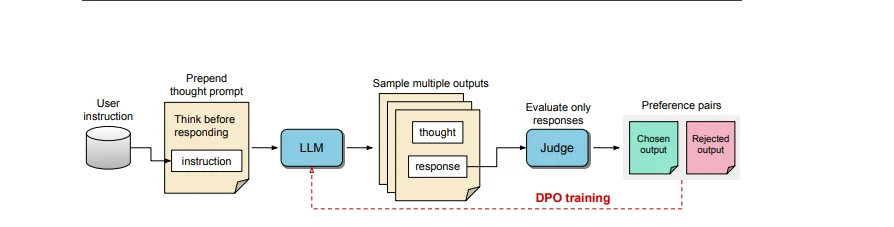
Meta ha appena svelato un innovativo metodo di addestramento per l’intelligenza artificiale (AI), chiamato Thought Preference Optimization (TPO), che potrebbe migliorare significativamente il modo in cui le macchine elaborano informazioni e rispondono alle domande. Questo approccio insegna ai modelli linguistici a riflettere internamente prima di fornire risposte, come se “pensassero” prima di parlare.
Se l’approccio di Meta si dimostrerà efficace, potrebbe aprire la strada a un rivale open-source del modello o1 di OpenAI. Un’alternativa open-source potrebbe democratizzare l’accesso a questo tipo di pensiero avanzato sull’IA.
Ora, i suoi sviluppatori si stanno accusando in diverse analisi pubbliche, scioccando la comunità AI. Matt Schumer, il creatore, sta addestrando una nuova versione con il suo hardware e dati.