L’idea che un assistente virtuale possa essere un amico fidato è una delle più grandi illusioni dell’era digitale. Dietro l’apparente neutralità di un chatbot si cela una realtà ben più inquietante: il 30% delle app di intelligenza artificiale più popolari condivide i tuoi dati con terze parti.
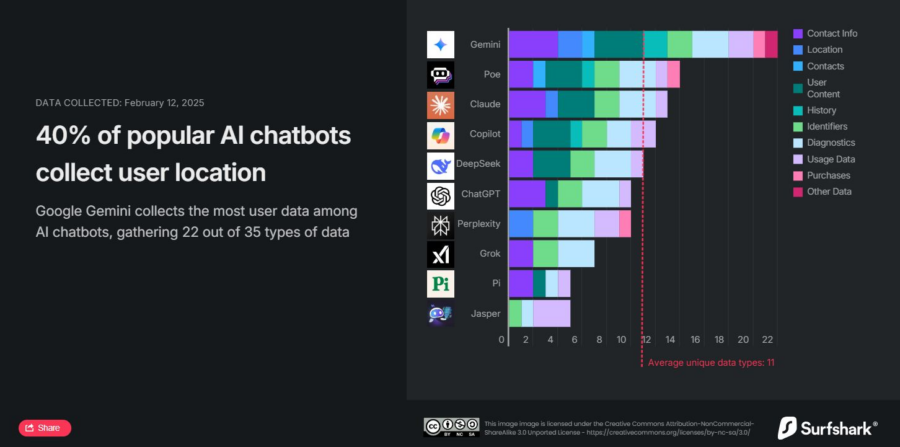
Abbiamo analizzato le pratiche di raccolta dati dei 10 chatbot più diffusi sull’Apple Store, da Google Gemini a DeepSeek, ChatGPT e altri. I risultati? Ogni chatbot raccoglie informazioni su di te, con una media di 11 tipi di dati per app su un totale di 35 possibili categorie. Alcuni arrivano a collezionare dettagli inquietanti, come la posizione precisa, lo storico delle ricerche e persino la tua lista contatti.
Meta, la compagnia che una volta incarnava il vertice dell’innovazione sociale e tecnologica, ha preso una decisione che potrebbe sembrare una contraddizione ambulante. Per anni, ha costruito meticolosamente muri di protezione attorno ai suoi processi di sviluppo, in particolare per ciò che riguarda la privacy degli utenti. L’idea era quella di costruire una solida fortificazione contro possibili violazioni e fughe di dati. Oggi, però, sembra che questa stessa azienda stia abbassando quelle barriere per accelerare il rilascio dei suoi nuovi prodotti. Un’inversione di tendenza che solleva domande sulle vere priorità di Meta e sulle sue strategie future.
Le autorità italiane hanno deciso che DeepSeek, la startup AI cinese che sta facendo tremare Silicon Valley, non può operare in Italia. Il Garante per la Protezione dei Dati Personali ha sbattuto la porta in faccia alla compagnia, accusandola di non aver fornito risposte sufficienti sulle sue pratiche di raccolta dati. In parole povere: “non ci avete convinto, quindi fuori dai piedi.”
L’idea di condividere la propria vita online è diventata una norma per molti, ma non senza rischi. Un caso recente in Francia, riportato da Euronews, dimostra quanto le app progettate per scopi personali o per intrattenimento possano rivelarsi pericolose. Rendere pubblico il tracciamento online, magari tramite l’uso del GPS durante le corse di allenameno, oltre ad essere una auto violazione della propria privacy online, può diventare uno strumento molto forte da dare in mano a malintenzionati.
Meta Platforms si trova al centro di una bufera mediatica e politica dopo l’annuncio di modifiche significative alle sue policy sui contenuti. Il CEO Mark Zuckerberg ha dichiarato che l’azienda interromperà il programma di fact-checking di terze parti negli Stati Uniti, ridurrà le azioni sui contenuti che potrebbero violare le policy aziendali e aumenterà la visibilità dei contenuti politici sulle piattaforme social del gruppo. Queste decisioni hanno sollevato una serie di critiche da parte dei dipendenti di Meta, di enti regolatori europei e di alcune figure politiche statunitensi.
La privacy è una questione cruciale nell’era dell’intelligenza artificiale onnipresente. Scopri come puoi gestire meglio le tue informazioni personali.
È facile pensare che usare strumenti di intelligenza artificiale significhi interagire con una macchina neutrale e indipendente. Tuttavia, tra cookie, identificatori di dispositivo, requisiti di accesso e account, e occasionali revisori umani, i servizi online sembrano avere un insaziabile desiderio di raccogliere i tuoi dati.
La privacy è una delle principali preoccupazioni sia per i consumatori che per i governi riguardo all’intelligenza artificiale. Le piattaforme spesso mostrano le loro funzionalità di privacy, anche se sono difficili da trovare.
I piani aziendali e a pagamento generalmente escludono la formazione sui dati inviati. Ma ogni volta che un chatbot “ricorda” qualcosa, può sembrare invasivo.
In questo articolo, spiegheremo come migliorare le impostazioni sulla privacy dell’IA eliminando le chat e le conversazioni precedenti e disattivando le impostazioni in ChatGPT, Gemini (ex Bard), Claude, Copilot e Meta AI che permettono agli sviluppatori di addestrare i loro sistemi sui tuoi dati. Queste istruzioni sono per l’interfaccia desktop basata su browser di ciascuno.
Solo, si fa per dire, 4 anni fa, Jared Kaplan, fisico teorico della Johns Hopkins University, ha pubblicato un articolo rivoluzionario sull’intelligenza: Scaling Laws for Neural Language Models.
La conclusione è stata chiara: più dati c’erano per addestrare un grande modello linguistico migliore sarebbe stato il suo rendimento, accurato e con più informazioni.
“Tutti sono rimasti molto sorpresi dal fatto che queste tendenze – queste leggi di scala come le chiamiamo noi – fossero fondamentalmente precise quanto quelle che si vedono in astronomia o fisica”
Kaplan
I ricercatori utilizzano da tempo grandi database pubblici di informazioni digitali per sviluppare l’Intelligenza Artificiale, tra cui Wikipedia e Common Crawl, un database di oltre 250 miliardi di pagine web raccolte a partire dal 2007. I ricercatori spesso “ripuliscono” i dati rimuovendo discorsi di incitamento all’odio e altri testi indesiderati prima di utilizzarli per addestrare modelli di intelligenza artificiale.
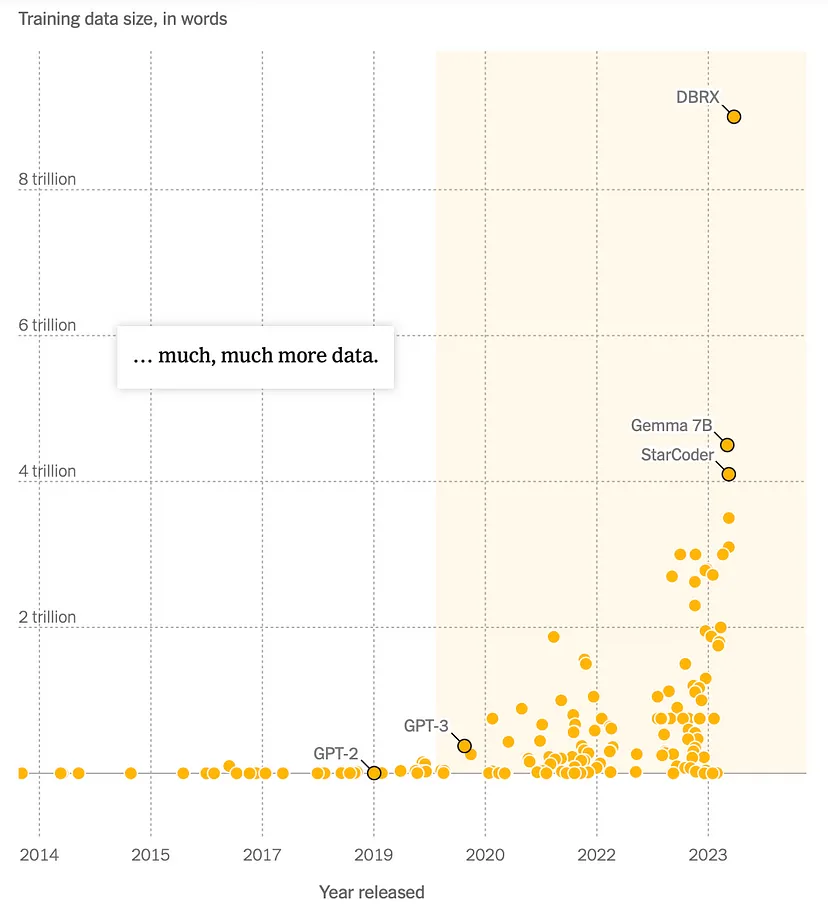
Nel 2020, i set di dati erano minuscoli rispetto agli standard odierni. All’epoca una banca dati contenente 30.000 fotografie dal sito fotografico Flickr era considerata una risorsa vitale.
Dopo l’articolo del Dr. Kaplan, quella quantità di dati non era più sufficiente. Si è parlato di “rendere le cose davvero grandi”, ha affermato Brandon Duderstadt, Nomic AD.
Quando OpenAI ha lanciato GPT-3 nel novembre 2020, ha segnato un traguardo significativo nell’addestramento dei modelli di intelligenza artificiale. GPT-3 è stato addestrato su una quantità di dati senza precedenti, circa 300 miliardi di “token”, che sono sostanzialmente parole o pezzi di parole.
Questa vasta quantità di dati ha permesso a GPT-3 di generare testi con una precisione sorprendente, producendo post di blog, poesie e persino i propri programmi informatici.
Tuttavia, nel 2022, DeepMind, un laboratorio di Intelligenza Artificiale di proprietà di Google, ha spinto ulteriormente in avanti i limiti.
Ha condotto esperimenti su 400 modelli di Intelligenza Artificiale, variando la quantità di dati di addestramento e altri parametri. I risultati hanno mostrato che i modelli più performanti utilizzavano ancora più dati di quelli previsti dal Dr. Kaplan nel suo articolo. Un modello in particolare, noto come Chinchilla, è stato addestrato su 1,4 trilioni di token.
Ma il progresso non si è fermato lì. L’anno scorso, ricercatori cinesi hanno presentato un modello di intelligenza artificiale chiamato Skywork, addestrato su 3,2 trilioni di token provenienti da testi sia in inglese che in cinese.
Google ha risposto presentando un sistema di Intelligenza Artificiale, PaLM 2, che ha superato i 3,6 trilioni di token.
Questi sviluppi evidenziano la rapida evoluzione del campo dell’Intelligenza Artificiale e l’importanza dei dati nell’addestramento di modelli sempre più potenti. Con ogni nuovo modello e ogni trilione di token aggiuntivo, ci avviciniamo sempre di più a modelli di Intelligenza Artificiale che possono comprendere e generare il linguaggio con una precisione e una naturalezza sempre maggiori.
Tuttavia, con questi progressi arrivano anche nuove sfide e responsabilità, poiché dobbiamo garantire che queste potenti tecnologie siano utilizzate in modo etico e responsabile.
Poi nel 2023 è arrivato questo discorso sul Synthetic Data e sulle chellenges: “Si esauriranno”. Sam Altman, Ceo di OpenAI aveva un piano per far fronte all’incombente carenza di dati.
In una email a The Verge, la portavoce di OpenAI, Lindsay Held, ha dichiarato che l’azienda utilizza “numerose fonti, compresi i dati disponibili pubblicamente e le partnership per i dati non pubblici” e che sta cercando di generare i propri dati sintetici.
Nel mese di maggio, lo stesso Altman, ha riconosciuto che le aziende di Intelligenza Artificiale avrebbero sfruttato tutti i dati disponibili su Internet.
Altman ha avuto un’esperienza diretta di questo fenomeno. All’interno di OpenAI, i ricercatori hanno raccolto dati per anni, li hanno puliti e li hanno inseriti in un vasto pool di testo per addestrare i modelli linguistici dell’azienda. Hanno estratto il repository di codice GitHub, svuotato i database delle mosse degli scacchi e attingono ai dati che descrivono i test delle scuole superiori e i compiti a casa dal sito web Quizlet.
Tuttavia, entro la fine del 2021, queste risorse erano esaurite, come confermato da otto persone a conoscenza della situazione dell’azienda, che non erano autorizzate a parlare pubblicamente.
Cosa sono i dati sintetici: i dati sintetici sono dati generati artificialmente, piuttosto che dati raccolti da eventi del mondo reale. Sono spesso utilizzati per l’addestramento dei modelli di Intelligenza Artificiale (IA) quando i dati reali non sono disponibili o sono insufficienti. Sam Altman, ex CEO di OpenAI, ha lavorato su modelli generativi che producono dati sintetici. Questi modelli, come GPT-4, utilizzano un gran numero di parametri per definire come possono essere prodotti dati simili a quelli forniti durante la fase di apprendimento. Questi parametri sono “regole generali” per la creazione di nuovi dati che il modello acquisisce dalle informazioni di addestramento fornite in precedenza. In un modello generativo basato su reti neurali, i parametri vengono ottimizzati per migliorare la capacità del modello di generare dati sintetici coerenti con quelli di addestramento. Ad esempio, si ritiene che il modello GPT-4 di OpenAI sia stato composto utilizzando qualcosa come 1.000 miliardi di parametri.
WIKI
Il CEO di YouTube, ha detto cose simili sulla possibilità che OpenAI abbia usato YouTube per addestrare il suo modello di generazione di video Sora.
Non sorprende che in entrambi i casi si tratti di azioni che hanno a che fare con la nebulosa area grigia della legge sul copyright dell’AI.
Da un lato OpenAI, alla continua ricerca di dati per un training di qualità, avrebbe sviluppato il suo modello di trascrizione audio Whisper per superare il problema,trascrivendo oltre un milione di ore di video di YouTube per addestrare GPT-4.
Secondo il New York Times, l’azienda sapeva che si trattava di un’operazione discutibile dal punto di vista legale (il presidente di OpenAI Greg Brockman era personalmente coinvolto nella raccolta dei video utilizzati), ma riteneva che si trattasse di un uso corretto(il cosidetto “fair use” tanto declamato dalle aziende di AI).
Tuttavia, Altman ha dichiarato che la corsa ai modelli generativi di dimensioni sempre più grandi sarebbe già conclusa. Ha suggerito che gli attuali modelli potranno evolvere in altri modi, non puntando più sulla “grandezza” e lasciando intendere che GPT-4 potrebbe essere l’ultimo e definitivo avanzamento nella strategia di OpenAI per ciò che riguarda il numero di parametri utilizzati in fase di addestramento.
Nel frattempo Google :
Matt Bryant, rappresentante comunicazione di Google, ha dichiarato che l’azienda non era a conoscenza delle attività di OpenAI e ha proibito lo “scraping o il download non autorizzato di contenuti da YouTube”. Google interviene quando esiste una chiara base legale o tecnica per farlo.
Le politiche di Google permettono l’utilizzo dei dati degli utenti di YouTube per sviluppare nuove funzionalità per la piattaforma video. Tuttavia, non era evidente se Google potesse utilizzare i dati di YouTube per creare un servizio commerciale al di fuori della piattaforma video, come un chatbot.
“La questione se i dati possano essere utilizzati per un nuovo servizio commerciale è soggetta a interpretazione e potrebbe essere fonte di controversie”.
Avv .Geoffrey Lottenberg, studio legale Berger Singerman
Verso la fine del 2022, dopo che OpenAI aveva lanciato ChatGPT, dando il via a una corsa nel settore per recuperare il ritardo, i ricercatori e gli ingegneri di Google hanno discusso su come sfruttare i dati di altri utenti per sviluppare prodotti di intelligenza artificiale. Tuttavia, le restrizioni sulla privacy dell’azienda limitano il modo in cui potrebbero utilizzare i dati, secondo persone a conoscenza delle pratiche di Google.
Secondo le ricostruzioni, a giugno, il dipartimento legale di Google ha chiesto al team per la privacy di redigere un testo per ampliare gli scopi per i quali l’azienda potrebbe utilizzare i dati dei consumatori (secondo due membri del team per la privacy e un messaggio interno visualizzato dal Times) ed è stato comunicato ai dipendenti che Google desiderava utilizzare i contenuti pubblicamente disponibili in Google Docs, Google Sheets e app correlate per una serie di prodotti AI. I dipendenti hanno affermato di non sapere se l’azienda avesse precedentemente addestrato l’intelligenza artificiale su tali dati.
In quel periodo, la politica sulla privacy di Google stabiliva che l’azienda potesse utilizzare le informazioni pubblicamente disponibili solo per “aiutare a formare i modelli linguistici di Google e creare funzionalità come Google Translate”.
Il team per la privacy ha redatto nuovi termini in modo che Google potesse utilizzare i dati per i suoi “modelli di Intelligenza Artificiale e creare prodotti e funzionalità come Google Translate, Bard e funzionalità di Intelligenza Artificiale del cloud”, che rappresentava una gamma più ampia di tecnologie di intelligenza artificiale.
“Qual è l’obiettivo finale qui?” ha chiesto un membro del team per la privacy in un messaggio interno. “Quanto sarà estesa?”
Al team è stato specificamente detto di pubblicare i nuovi termini nel fine settimana del 4 luglio, quando le persone sono generalmente concentrate sulle vacanze, secondo i dipendenti. La politica rivista è stata lanciata il 1° luglio, all’inizio del lungo fine settimana (NdR,il 4 luglio negli Usa è festa nazionale).
E Meta?Mark Zuckerberg aveva lo stesso problema, non aveva abbastanza dati, avevano utilizzato tutto come detto a un dirigente da Ahmad Al-Dahle, vicepresidente dell’AI generativa di Meta quindi non poteva eguagliare ChatGPT a meno che non fosse riuscito ad ottenere più dati.
Meta ha usato, fra gli altri materiali, due raccolte di libri, il Gutenberg Project, che contiene opere nel pubblico dominio, e la sezione Books3. Ma la maggior parte sono opere “piratate” e per questo alcuini avviato una class action contro Meta e ciò era evidente sino dall’inizio come dimostra il documento di seguito.
Nei mesi di marzo e aprile 2023, alcuni leader dello sviluppo aziendale, ingegneri e avvocati dell’azienda si sono incontrati quasi quotidianamente per affrontare il problema.
Alcuni hanno discusso del pagamento di 10 dollari a libro per i diritti di licenza completi sui nuovi titoli. Hanno discusso dell’acquisto di Simon & Schuster,di cui fanno parte anche Penguin Random House, HarperCollins, Hachette e Macmillan. Fra gli autori di Simon & Schuster ci sono Stephen King, Colleen Hoover e Bob Woodward.
Hanno anche parlato di come avevano riassunto libri, saggi e altri lavori da Internet senza permesso anche per via del precedente scandalo sulla condivisione dei dati dei suoi utenti all’epoca di Cambridge Analytica.
Un avvocato ha avvertito di preoccupazioni “etiche” riguardo alla sottrazione della proprietà intellettuale agli artisti, ma è stato accolto nel silenzio, secondo un audio registrato e condiviso con il NYT di cui ha dato conto il quotidiano britannico The Guardian. Meta era stata anche accusata dal BEUC unione consumatori europei con una multa da 1.2 miliardi di euro.
Zuckerberg, per tranquillizare gli investitori, ha affermato in una recente call (Earnings call Transcript 2023 di seguito) che i miliardi di video e foto condivisi pubblicamente su Facebook e Instagram sono “superiori al set di dati Common Crawl”.
I dirigenti di Meta hanno affermato che OpenAI sembrava aver utilizzato materiale protetto da copyright senza autorizzazione. Secondo le registrazioni, Meta impiegherebbe troppo tempo per negoziare le licenze con editori, artisti, musicisti e l’industria dell’informazione.
“L’unica cosa che ci impedisce di essere bravi quanto ChatGPT è letteralmente solo il volume dei dati”,
Nick Grudin, vP partnership globale e dei contenuti.
Sembra che OpenAI stia prendendo materiale protetto da copyright e Meta potrebbe seguire questo “precedente di mercato”, ha aggiunto, citando una decisione del tribunale del 2015 che coinvolgeva la Authors Guild contro Google .
In quel caso, a Google è stato consentito di scansionare, digitalizzare e catalogare libri in un database online dopo aver sostenuto di aver riprodotto solo frammenti delle opere online e di aver trasformato gli originali, sempre in base alla dottrina del fair use.
La saga continua.
Come abbiamo scritto in un precedente post, la FTC americana può riaprire il caso sulla privacy di Meta nonostante la multa di 5 miliardi di dollari, stabilisce il tribunale, anche se Meta – che possiede WhatsApp, Instagram e Facebook – ha risposto che la FTC non può “riscrivere unilateralmente” i termini dell’accordo precedente, che un giudice statunitense ha approvato nel 2020.
L’FTC ha replicato che l’accordo, che stabilisce nuovi requisiti di conformità e supervisione, non era destinato a risolvere “tutte le richieste di risarcimento in perpetuo”.
Indipendentemente dal punto di vista e da ciò che sarà deciso nei tribunali, l’importanza di conoscere il contenuto dei dataset è oggi più rilevante che mai. Si tratta senza dubbio di un problema di natura politica.