Nel panorama in rapida evoluzione dell’intelligenza artificiale (AI), l’efficienza e la velocità di elaborazione sono fondamentali. Groq, azienda leader nel settore, ha sviluppato l’Unità di Elaborazione del Linguaggio (LPU), una tecnologia rivoluzionaria progettata per accelerare i carichi di lavoro di AI e machine learning (ML). Rentemente, Groq ha collaborato con Aramco Digital per costruire il più grande data center di inferenza AI al mondo in Arabia Saudita, con l’obiettivo di raggiungere una capacità di elaborazione di 25 milioni di token al secondo entro la fine del primo trimestre del 2025.
La partnership tra Groq e Aramco Digital rappresenta un passo decisivo verso l’espansione delle capacità AI a livello globale.Il nuovo data center in Arabia Saudita non solo rafforzerà l’infrastruttura digitale del Regno, ma posizionerà anche il paese come hub centrale per l’innovazione AI nella regione. Con il supporto di Aramco Digital, Groq prevede di scalare rapidamente le sue operazioni, offrendo servizi a clienti in Europa, Medio Oriente, Africa e oltre.
La startup di intelligenza artificiale Groq ha annunciato di aver raccolto 640 milioni di dollari in un round di finanziamento di serie D, con l’obiettivo di competere con Nvidia nel settore dei semiconduttori.
In questi giorni, soprattutto sui social, si parla molto di nuovo sistema di intelligenza artificiale in grado di garantire prestazioni e velocità impareggiabili. Si tratta di Groq (che non c’entra nulla con il Grok che ha annunciato Elon Musk), un’azienda fondata nel 2016 da Jonathan Ross, un ex ingegnere di Google, che ha sviluppato un processore di intelligenza artificiale progettato specificamente per accelerare l’elaborazione delle reti neurali profonde a una velocità incredibile.
Si tratta di un motore di inferenza LPU (Language Processing Unit), un tipo di hardware progettato specificamente per elaborare e analizzare il linguaggio naturale. È un tipo di modello di Intelligenza Artificiale in grado di comprendere, interpretare e generare il linguaggio umano. Le LPU sono comunemente utilizzate in applicazioni quali assistenti virtuali, chatbot e servizi di traduzione linguistica.
Le GPU, invece, che sono utilizzate anche per l’elaborazione generale, comprese le attività di AI e di apprendimento automatico, sono un tipo di hardware progettato specificamente per eseguire il rendering di grafica e immagini da visualizzare su uno schermo. Le GPU sono comunemente utilizzate nei computer e nelle console di gioco per gestire l’elevato numero di calcoli necessari a visualizzare grafica di alta qualità in tempo reale.
La differenza principale tra un LPU e una GPU è quindi il tipo di dati che i due sistemi sono ottimizzati per elaborare. Una LPU è ottimizzata per l’elaborazione e l’analisi del linguaggio naturale, mentre una GPU è ottimizzata per il rendering di grafica e immagini.
Tradotto il tutto e parlando in termini di modelli di Intelligenza Artificiale, un LPU è più adatto per le attività di elaborazione del linguaggio naturale, come l’analisi del testo, l’analisi del sentiment e la traduzione linguistica. Una GPU, invece, è più adatta per compiti che richiedono molta potenza di calcolo, come il riconoscimento delle immagini, l’analisi video e il deep learning.
Potete provare il motore di inferenza LPU dell’azienda tramite l’interfaccia GroqChat, sebbene il chatbot non abbia accesso a Internet, e mettere alla prova il sistema scegliendo tra i due motori Mixtral 8x7B-32k e Llama2 70B-4k.
Alla fine dell’anno scorso, i test interni hanno fissato un nuovo livello di prestazione raggiungendo più di 300 token al secondo per utente attraverso Llama-2 (70B) LLM di Meta AI. Nel gennaio 2024, l’azienda ha preso parte al suo primo benchmarking pubblico, lasciandosi alle spalle tutti gli altri fornitori di inferenza basati su cloud. Ora è emerso vittorioso contro gli otto principali fornitori di cloud in test indipendenti.
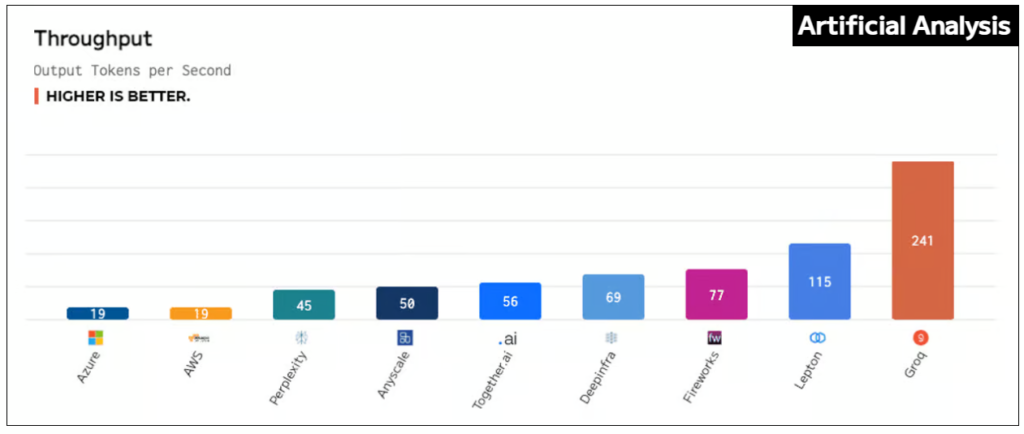
“ArtificialAnalysis.ai ha valutato in modo indipendente Groq e la sua API Llama 2 Chat (70B) ottenendo un throughput di 241 token al secondo, più del doppio della velocità di altri provider di hosting“, ha affermato Micah Hill-Smith, co-creatore di ArtificialAnalysis.ai . “Groq rappresenta un cambiamento radicale nella velocità disponibile, consentendo nuovi casi d’uso per modelli linguistici di grandi dimensioni“.
Il Groq LPU Inference Engine è risultato il migliore per aspetti quali tempo di risposta totale, throughput nel tempo, varianza del throughput e latenza rispetto al throughput, con il grafico per l’ultima categoria che necessitava di estendere i suoi assi per accogliere i risultati.
Fonte: Artificial Analysis [Throughput: Tokens per second received while the model is generating tokens (ie. after first chunk has been received from the API)].
“Groq esiste per eliminare ‘chi ha e chi non ha’ e per aiutare tutti nella comunità dell’intelligenza artificiale a prosperare“, ha affermato Jonathan Ross, CEO e fondatore di Groq. “L’inferenza è fondamentale per raggiungere questo obiettivo perché la velocità è ciò che trasforma le idee degli sviluppatori in soluzioni aziendali e applicazioni che cambiano la vita. È incredibilmente gratificante avere una terza parte che convalidi che il motore di inferenza LPU è l’opzione più veloce per eseguire modelli linguistici di grandi dimensioni e siamo grati ai ragazzi di ArtificialAnalysis.ai per aver riconosciuto Groq come un vero contendente tra gli acceleratori di intelligenza artificiale“.
Non perderti le ultime novità sul mondo dell’Intelligenza Artificiale, i consigli sui tool da provare, i prompt e i corsi di formazione. Iscriviti alla newsletter settimanale e accedi a un mondo di contenuti esclusivi direttamente nella tua casella di posta!