Google, inizierà a testare gli annunci di ricerca e di shopping nelle sue risposte generate dall’intelligenza artificiale negli Stati Uniti. La mossa arriva pochi giorni dopo che il gigante tecnologico statunitense ha lanciato la funzionalità AI Overviews durante la sua conferenza annuale I/O . AI Overviews crea riepiloghi generati dall’intelligenza artificiale in risposta alle query di ricerca di Google.
“Avranno l’opportunità di apparire nella Panoramica AI in una sezione chiaramente etichettata come “sponsorizzata” quando sono pertinenti sia alla query che alle informazioni nella Panoramica AI”,
La divisione di Alphabet, Google, ha annunciato un investimento aggiuntivo di un miliardo di euro (circa 1,1 miliardi di dollari) per ampliare il campus del suo data center in Finlandia e sostenere la crescita del business dell’intelligenza artificiale in Europa, come riportato da Reuters.
Negli ultimi anni, numerosi data center sono stati costruiti nei paesi nordici grazie al clima più fresco, e alla vicinanza di un mare “gelido’ alle agevolazioni fiscali e alla vasta disponibilità di energia rinnovabile, secondo il rapporto.
Cinquanta anni fa, le fortune delle aziende americane erano strettamente legate al benessere dell’intera nazione. Le imprese investivano nei propri dipendenti e nelle nuove tecnologie, garantendo prosperità sia per loro stesse che per i lavoratori.
Oggi, tuttavia, un numero crescente di dirigenti aziendali esprime preoccupazione per l’eccessivo interesse delle aziende verso i profitti a breve termine, concentrandosi unicamente sui guadagni degli azionisti. Questo approccio limita gli investimenti nei lavoratori, nella ricerca e nello sviluppo tecnologico, costi immediati che potrebbero temporaneamente ridurre i profitti. Secondo questi leader, tale strategia potrebbe portare a seri problemi nel lungo periodo per il paese.
La storia del capitalismo del XXI secolo è stata marcata dallo sviluppo straordinario di Apple e Google. In termini di creazione di ricchezza, non esiste paragone. Solo otto anni fa, nessuna delle due aziende figurava tra le dieci più valenti al mondo, e la loro capitalizzazione di mercato combinata era inferiore a 300 miliardi di dollari.
Oggi, Apple e Alphabet (la holding di Google) sono le due società più valenti, con una capitalizzazione di mercato combinata che supera i 1,3 trilioni di dollari. Questi colossi stanno sempre più spesso entrando in competizione in vari settori, dagli smartphone ai dispositivi audio domestici, fino a speculazioni su automobili e forse in un futuro sull AI. Tuttavia, la collisione più significativa tra Apple e Google passa quasi inosservata:
le due aziende hanno adottato approcci radicalmente diversi nei confronti dei loro azionisti e del futuro. Apple tende a soddisfare le richieste degli investitori, mentre Google mantiene il controllo nelle mani dei fondatori e dei dirigenti.
Durante la conferenza I/O della scorsa settimana, Google ha presentato una serie di promettenti prodotti di intelligenza artificiale generativa.
Tuttavia, alcuni creatori sono preoccupati che queste nuove funzionalità possano diminuire il traffico web, riducendo le visite organiche e le entrate pubblicitarie.
All’I/O 2023 Google ha lanciato Project Gameface , un “mouse” da gioco open source a mani libere che consente alle persone di controllare il cursore di un computer utilizzando il movimento della testa e i gesti facciali. Le persone possono alzare le sopracciglia per fare clic e trascinare o aprire la bocca per spostare il cursore, rendendo il gioco più accessibile.
il Videocita la collaborazione con Incluzza, società indiana che supporta persone con disabilità, insieme stanno studiando come il progetto possa essere esteso a contesti educativi e lavorativi.
Google ha presentato martedì la sesta generazione dei suoi chip con unità di elaborazione tensor, notando un significativo miglioramento rispetto alla generazione precedente. I nuovi chip, denominati Trillium, saranno disponibili per i clienti cloud entro la fine dell’anno e offrono un miglioramento delle prestazioni quasi cinque volte (4,7 volte) rispetto al TPU v5e presentato lo scorso agosto.
Il CEO di Google Sundar Pichai ha dichiarato: “Siamo pienamente nella nostra era Gemini “, aprendo martedì il discorso programmatico per la conferenza Google I/O 2024 a Mountain View, in California.
Un giorno dopo che OpenAI, sostenuta da Microsoft (MSFT), ha rilasciato GPT-4o con le sue innumerevoli nuove funzionalità, Google ha rilanciato svelando una serie di nuovi impieghi per Gemini 1.5 Pro, integrandolo in quasi tutti i prodotti offerti.
Google, il gigante tecnologico, ha annunciato lunedì che prevede di commercializzare Starline, la sua tecnologia di videoconferenza basata sull’intelligenza artificiale e sull’imaging 3D, nel 2025.
Oggi Dell Technologies ha subito una violazione dei dati che potrebbe potenzialmente avere un impatto sulle informazioni di 49 milioni di clienti, ha riferito Bleeping Computer. Dell sta attualmente indagando sull’incidente, in cui è stato coinvolto un portale Dell con informazioni “limitate” sugli acquisti dei clienti, ha aggiunto il notiziario .
Questa settimana Google Cloud e la società di sicurezza informatica CrowdStrike hanno stretto una partnership ampliata per combattere le intrusioni nel cloud.
Le intrusioni nel cloud sono aumentate del 75% nell’ultimo anno, con malintenzionati che si sono infiltrati negli ambienti dei clienti in soli due minuti, rileva CrowdStrike.
“Gli avversari attenti al cloud, in particolare gli attori dell’eCrime, utilizzano credenziali valide per accedere agli ambienti cloud delle vittime e quindi utilizzano strumenti legittimi per eseguire il loro attacco, rendendo difficile distinguere tra la normale attività dell’utente e una violazione”, si legge nell’ultimo Global Threat Report di CrowdStrike.
La nuova partnership ha lo scopo di combinare la piattaforma per le operazioni di sicurezza di Google Cloud con i prodotti di rilevamento e risposta degli endpoint, rilevamento e risposta alle minacce di identità e gestione dell’esposizione di CrowdStrike.
CrowdStrike vede l’emergere di nuove minacce informatiche derivanti dall’uso dell’intelligenza artificiale generativa per creare software e strumenti dannosi per infiltrarsi nelle aziende.
L’unità di ricerca sull’intelligenza artificiale DeepMind di Google ha presentato la terza versione del suo modello AI AlphaFold nel tentativo di creare farmaci e comprendere le proteine in modo più efficiente. I risultati sono stati pubblicati sulla rivista scientifica Nature .
“Per le interazioni delle proteine con altri tipi di molecole vediamo un miglioramento di almeno il 50% rispetto ai metodi di previsione esistenti, e per alcune importanti categorie di interazione abbiamo raddoppiato l’accuratezza della previsione,”
I risultati sono stati pubblicati sulla rivista scientifica Nature .
Google DeepMind ha anche introdotto il server AlphaFold, che descrive come uno “strumento di ricerca gratuito e facile da usare” che consentirà agli scienziati di testare come le proteine interagiscono con altre molecole prima di eseguire i test.
Oltre a comprendere le proteine, la versione più recente di AlphaFold – creata da DeepMind e dalla sua società sorella, Isomorphic Labs – può comprendere meglio il DNA, l’RNA, i ligandi e il modo in cui interagiscono tra loro.
“Con queste nuove funzionalità, possiamo progettare una molecola che si legherà a un punto specifico di una proteina e possiamo prevedere con quanta forza si legherà”,
ha detto il co-fondatore di Google DeepMind Demis Hassabis , secondo Reuters.
“È un passo fondamentale se si desidera progettare farmaci e composti che possano aiutare a combattere le malattie”,
Hassabis
Google DeepMind e Isomorphic fanno entrambi parte della società madre di Google, Alphabet.
Hassabis ha aggiunto che il nuovo modello potrebbe creare “un enorme valore commerciale” per Isomorphic Labs, che spera possa trasformarsi in un “business da centinaia di miliardi di dollari”, secondo Bloomberg .
Aricolo pubblicato su: https://www.nature.com/articles/s41586-024-07487-w
Google sta aggiungendo centinaia di venditori e ingegneri alla sua unità di cloud computing per aiutare a commercializzare Gemini e altri prodotti legati all’intelligenza artificiale, secondo un rapporto di The Information.
Sta inoltre spostando i dipendenti attuali in un team gestito da Oliver Parker, un ex dirigente delle vendite di Microsoft che è stato assunto da Google a gennaio come vicepresidente dell’intelligenza artificiale, aggiunge il rapporto .
Google Cloud ha creato anche un secondo team focalizzato sull’intelligenza artificiale, sotto la direzione di Tom DeFeo, vicepresidente di Google Cloud Go To Market Solution, per assistere i clienti nell’utilizzo dei nuovi strumenti di intelligenza artificiale.
Poiché gli strumenti basati sull’intelligenza artificiale costano più degli strumenti non basati sull’intelligenza artificiale, è necessario uno sforzo maggiore per convincere i clienti a pagare per gli aggiornamenti.
Il CEO di OpenAI, Sam Altman, aveva pubblicato un tweet in cui sosteneva che i costi computazionali di ChatGPT sono pesantissimi e che è necessario monetizzare il lavoro svolto dal chatbot su scala globale. Questo è il motivo per cui è stato lanciato ChatGPT Plus, una versione “premium” dell’applicazione Web al costo di 20 dollari al mese.
Reuters cita un rapporto Morgan Stanley che stima un costo a carico di Google pari a circa 0,002 dollari per ogni query inviata al suo motore di ricerca tradizionale.
Ipotizzando che Bard possa gestire metà delle ricerche Google con una media di 50 parole di risposta per ogni interrogazione, si stima che i costi affrontati dall’azienda guidata oggi da Sundar Pichai potrebbero salire fino a 6 miliardi di dollari nel 2024.
Il motivo è che, ovviamente, serve un lavoro computazionale più pesante svolto da parte di unità che in parallelo elaborano la migliore risposta da fornire all’utente sulla base dell’input.
Molte più unità computazionali significano anche maggiore energia per alimentare e far funzionare i sistemi.
Microsoft ha deciso di investire e collaborare con OpenAI, potenzialmente a causa della sensazione di restare indietro rispetto a Google di Alphabet ha riferito Bloomberg News, citando un’e-mail interna rilasciata nell’ambito del progetto del Dipartimento di Giustizia degli Stati Uniti caso antitrust contro Google.
Kevin Scott, Chief Technology Officer di Microsoft, era preoccupato quando ha esaminato i “divari di capacità” di formazione del modello di intelligenza artificiale tra Google e Microsoft, secondo un’e -mail di giugno 2019 che ha scritto al CEO Satya Nadella e al co-fondatore Bill Gates.
Lo scambio suggerisce che il dirigente ha riconosciuto in privato che mancavano l’infrastruttura e la velocità di sviluppo per raggiungere OpenAI –il creatore del chatbot ChatGPT e DeepMind di Google.
Scott ha scritto nell’e-mail: “siamo diversi anni indietro rispetto alla concorrenza in termini di scala ML [machine learning]”.
Nadella aveva approvato l’e-mail di Scott e l’aveva anche inoltrata al direttore finanziario Amy Hood, dicendo “un’ottima e-mail che spiega perché voglio che lo facciamo… e anche perché poi garantiremo che i nostri addetti all’infrastruttura vengano eseguiti”.
L’e-mail è stata pubblicata martedì scorso dopo che i media, tra cui il New York Times e Bloomberg, sono intervenuti nel caso antitrust e hanno chiesto un maggiore accesso pubblico, osserva il rapporto .
Il Dipartimento di Giustizia degli Stati Uniti aveva notato che ChatGPT di OpenAI e altre innovazioni avrebbero potuto essere rilasciate anni fa se Google non avesse monopolizzato il mercato della ricerca, aggiunge il rapporto.
La settimana scorsa, il giudice Amit Mehta ha ordinato alle società di fornire una versione redatta, poiché le informazioni “fanno luce sulla difesa di Google riguardo agli investimenti relativi di Google e Microsoft nella ricerca”, osserva il rapporto.
Giovedì e venerdì, Google e il Dipartimento di Giustizia dovrebbero presentare le argomentazioni conclusive del caso. Secondo il rapporto, si prevede che il giudice Mehta prenderà una decisione entro la fine dell’anno.
Google ha inviato una lettera al Dipartimento del Lavoro Americano affermando che un elenco di lavori considerati scarsi deve includere l’intelligenza artificiale, ha riferito The Verge.
Gli Stati Uniti secondo Google potrebbero perdere preziosi talenti tecnologici e di intelligenza artificiale se alcune delle politiche di immigrazione non fossero modernizzate, aggiunge il rapporto .
Google ha affermato che politiche come la Schedule A, un elenco di lavori che il governo degli Stati Uniti ha “pre-certificato” come non dotati di lavoratori americani adeguati, dovrebbero essere più flessibili per soddisfare la domanda di tecnologie come l’intelligenza artificiale e la sicurezza informatica.
Google ha aggiunto che gli Stati Uniti devono rivedere l’Allegato A per includere l’intelligenza artificiale e la sicurezza informatica e farlo con maggiore regolarità.
Gli Stati Uniti hanno un ampio bacino di talenti nel campo dell’intelligenza artificiale, tuttavia, secondo Karan Bhatia, capo degli affari governativi e delle politiche pubbliche di Google, nel paese c’è carenza di specialisti di intelligenza artificiale. Ma le dure politiche di immigrazione degli Stati Uniti hanno reso difficile attirare le persone a lavorare nelle aziende statunitensi per costruire piattaforme di intelligenza artificiale, aggiunge il rapporto, citando Bhatia.
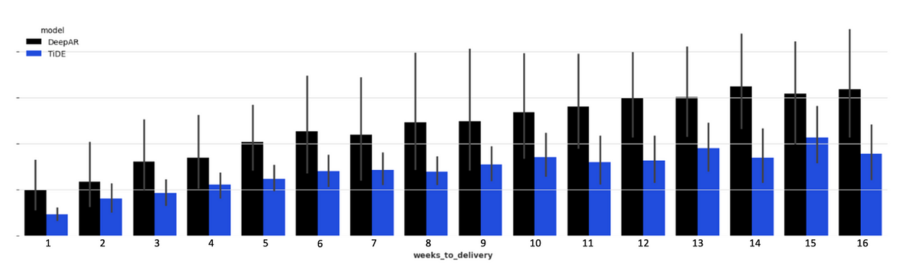
Negli ultimi anni, i modelli di previsione a lungo termine hanno guadagnato sempre più attenzione nel campo dell’intelligenza artificiale (AI) e dell’apprendimento automatico (machine learning). Questi modelli sono cruciali per una vasta gamma di applicazioni, dalle previsioni meteorologiche alle analisi economiche, passando per la gestione delle risorse energetiche e la pianificazione urbana. In questo contesto, TiDE (Time-series Dense Encoder) si è distinto come uno dei più promettenti. Sviluppato dal team di Google Research, TiDE rappresenta un passo in avanti significativo nella capacità di fare previsioni affidabili su orizzonti temporali più lunghi rispetto ai modelli tradizionali.
Google ha concluso un accordo con News Corp. per pagare alla società di media tra 5 e 6 milioni di dollari all’anno per sviluppare contenuti e prodotti relativi all’intelligenza artificiale, ha riportato The Information .
Come abbiamo spesso scritto l’intesa sarebbe l’ultimo anello di una lunga catena di accordi per riuscire a sfruttare legalmente i contenuti degli archivi delle testate per addestrare i sistemi di intelligenza artificiale.
L’accordo fa parte di una partnership più lunga tra le due società, ha aggiunto il notiziario , citando un dipendente di News Corp. e una persona vicina all’accordo.
OpenAI ha firmato lunedì un accordo con il Financial Times per utilizzare i suoi contenuti per addestrare modelli di intelligenza artificiale. Ha firmato accordi con altri editori, tra cui Axel Springer, il quotidiano francese Le Monde, il conglomerato mediatico spagnolo Prisa Media, l’Associated Press, l’American Journalism Project e la NYU.
Martedì OpenAI e Microsoft sono state citate in giudizio anche dall’hedge fund Alden Global Capital per presunta violazione, ha riferito il New York Times . Alden possiede otto quotidiani, tra cui The New York Daily News, The Chicago Tribune e The San Jose Mercury News.
Iscriviti alla nostra newsletter settimanale per non perdere le ultime notizie sull’Intelligenza Artificiale.
Google sta rafforzando la sua collaborazione con i partner multimediali, integrando l’intelligenza artificiale generativa nella sua tecnologia pubblicitaria, mentre i lettori di streaming aumentano la diffusione dei canali supportati da pubblicità. Durante le presentazioni NewFront, Google ha annunciato che la sua offerta Display & Video 360 si sta evolvendo per unificare meglio gli acquisti di pubblicità video, migliorando la scalabilità e la corrispondenza del pubblico.
Kristen O’Hara di Google ha dichiarato che l’azienda sta rafforzando le relazioni strategiche con i principali partner di streaming, tra cui Disney, Paramount, NBCUniversal e Warner Bros. Discovery.
Per soddisfare le esigenze delle agenzie in rapida evoluzione, Google sta introducendo gli accordi istantanei, uno strumento che consente agli esperti di marketing di configurare accordi personalizzati con i principali editori direttamente dall’interfaccia di Display & Video 360, bypassando il complesso processo di negoziazione. Questa funzionalità si sta espandendo oltre il proprio YouTube per raggiungere grandi editori come Disney.
Inoltre, Google ha presentato l’ottimizzatore dell’impegno (commitment optimizer), uno strumento che semplifica la gestione degli impegni annuali tra editori e tipi di offerte. Gli utenti possono inserire i termini e gli obiettivi dell’offerta, e l’intelligenza artificiale di Google ottimizzerà in modo intelligente il mix di inventario garantito e non garantito per offrire flessibilità e copertura.
Paramount specializes in creating content fans love on the platforms they can’t live without. Partnering with Google ensures that our clients can access Paramount Advertising’s premium inventory seamlessly through Display & Video 360.
Pete Chelala, Vice President Programmatic Advertising Sales, Paramount
Google sta anche contribuendo al Publisher Advertiser Identity Reconciliation dello IAB Tech Lab, un’iniziativa volta a migliorare la corrispondenza tra gli ID degli editori e degli inserzionisti, al fine di migliorare l’efficacia delle campagne pubblicitarie.
Per quanto riguarda l’intelligenza artificiale generativa, sta diventando una parte sempre più essenziale di Display & Video 360.
La funzione “audience persona“, basata sull’intelligenza artificiale, crea una gamma personalizzata di segmenti di pubblico in linea con le specifiche esigenze dell’annunciatore. Questo strumento offre la possibilità di selezionare tra migliaia di varianti per allinearsi perfettamente con gli obiettivi pubblicitari. Grazie alle opzioni di offerta personalizzate, gli inserzionisti possono stabilire le proprie priorità e ottenere una strategia mirata a massimizzare l’impatto delle loro campagne sui risultati sperati.
L’algoritmo di Google del marzo 2024 ha stimolato il dibattito sulla relazione tra i contenuti generati dall’intelligenza artificiale e la qualità dei contenuti. Questo algoritmo ha eliminato molti siti AI dalle classifiche, in particolare quelli che pubblicano regolarmente enormi quantità di contenuti.
Il colosso tecnologico afferma che i cambiamenti, che enfatizzano l’elevazione degli autori umani con competenza analizzando le tracce di Internet che li accompagnano (biografie, esperienza lavorativa, ecc.), ridurranno del 40% i contenuti di bassa qualità e non originali nei risultati di ricerca.
Ian Nuttall, una figura di spicco nella comunità SEO, ha monitorato lo stato di indicizzazione di 49.345 siti web da quando Google ha apportato le modifiche. Finora, 837 dei siti monitorati – che complessivamente rappresentano circa 21 milioni di visite di ricerca organica al mese – sono stati deindicizzati (rimossi dai risultati di ricerca).
Uno studio recente di Originality.ai su questi siti web deindicizzati ha rilevato che il 100% mostrava segni di contenuti generati dall’intelligenza artificiale, con il 50% che aveva il 90-100% dei propri post generati dall’intelligenza artificiale.
Questo tipo di contenuto AI di bassa qualità non è solo una minaccia per i risultati di ricerca, ma c’è anche il problema dell'”IA asburgica” (Jathan Sadowski: “un sistema che è così pesantemente addestrato sui risultati di altre IA generative che diventa un innato mutante, probabilmente con caratteristiche esagerate e grottesche”), chiamato anche “MAD” (Model Autophagy Disorder, un termine di Richard G. Baraniuk).
Ciò si verifica quando i sistemi di intelligenza artificiale peggiorano perché si nutrono dei dati che hanno generato loro stessi (chiamati dati sintetici).
Tuttavia, c’è una certa ironia nel fatto che Gemini di Google sia una delle piattaforme che contribuisce a generare questa “quantità in rapida crescita di contenuti spam generati dall’intelligenza artificiale”. Ma questa è una storia diversa.
Google sta prendendo provvedimenti per affrontare il problema dei contenuti spam generati dall’intelligenza artificiale, modificando i suoi algoritmi per premiare gli autori umani con competenza e ridurre la visibilità dei contenuti di bassa qualità e non originali. Tuttavia, rimane ancora molto lavoro da fare per affrontare il problema più ampio dell’IA asburgica e del MAD, che potrebbero avere implicazioni negative sulla qualità e l’affidabilità dei contenuti generati dall’intelligenza artificiale.
Come verificare se sei stato colpito
Valuta il ranking attuale e il traffico del tuo sito per eventuali cali significativi a partire da marzo.
Raccogli informazioni su quali pagine o tipi di contenuti specifici hanno avuto un impatto negativo.
Pagine, parole chiave o categorie specifiche, ecc.
Controlla i tuoi backlink: hai notato eventuali impatti negativi attorno a link specifici al tuo sito?
Google fa la storia chiudendo sopra i 2 trilioni di dollari.
Venerdì le azioni di Alphabet si sono mosse nettamente in rialzo – +10% – dopo che un rapporto sugli utili ricevuto dagli investitori segnalava (insieme a quello di Microsoft) che il lungo trade in Big Tech era decisamente ancora acceso.
Abbiamo visto non solo ha visto la forza del rapporto in una ripresa della pubblicità digitale, ma anche molteplici catalizzatori per un altro passo avanti nel prossimo futuro, tra cui la continua forte crescita degli annunci digitali, il probabile azzeramento della stima degli utili per azione, la possibilità per Alphabet il riacquisto fino al 4% delle sue azioni in circolazione e un nuovo dividendo che potrebbe portare una nuova classe di acquirenti.
Non solo i risultati sono stati ottimi, ma Google sta “lentamente voltando una nuova pagina ed emergendo di nuovo in testa nell’accesa corsa all’intelligenza artificiale”.
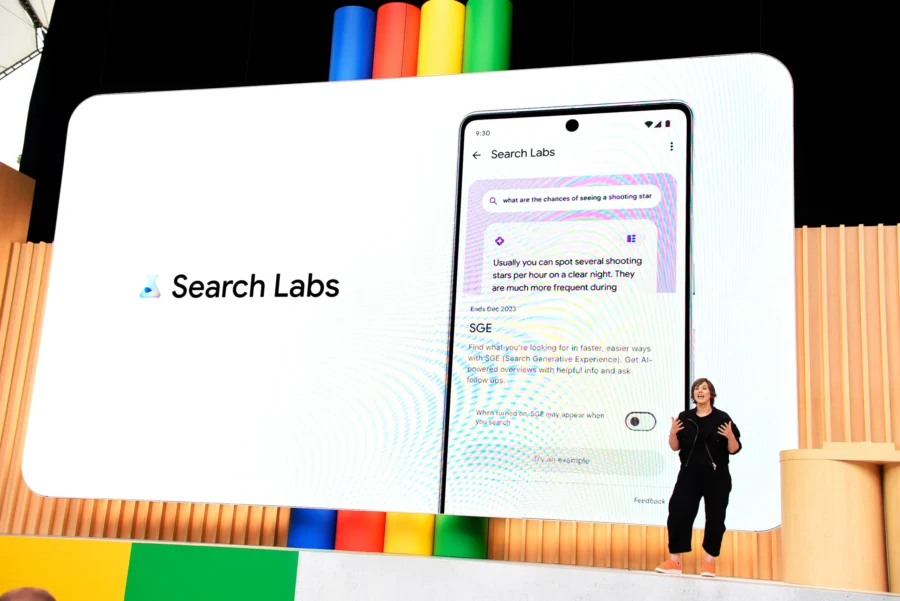
Guardando al futuro, la disponibilità generale della Search Generative Experience dell’azienda potrebbe diventare un fattore critico di espansione multipla:
“Crediamo che l’eventuale integrazione di SGE nella Ricerca Google sarà fondamentale per rafforzare la rilevanza del motore man mano che i tradizionali formati di risposta alle query migrano gradualmente verso formati di intelligenza artificiale generativa”.
I ricavi sono saliti a 80,54 miliardi di dollari, superando facilmente il consenso di 78,7 miliardi di dollari. I ricavi pubblicitari sono aumentati del 13% a 61,7 miliardi di dollari.
Nel frattempo, le entrate pubblicitarie di YouTube – in precedenza motivo di preoccupazione – sono aumentate del 21% arrivando a 8,09 miliardi di dollari. I ricavi da abbonamenti, piattaforme e dispositivi sono aumentati del 18%.
E lo slancio nel cloud è continuato, con una crescita dei ricavi del 28% e un utile operativo più che quadruplicato anno su anno.
L’utile operativo è aumentato del 46% su base annua, raggiungendo i 25,47 miliardi di dollari. L’utile per azione è stato di 1,89 dollari contro gli 1,50 dollari previsti da Wall Street. Anche il margine operativo è aumentato, al 32% rispetto al 25% di un anno fa.
“I nostri risultati nel primo trimestre riflettono le ottime prestazioni di Ricerca, YouTube e Cloud”, “Siamo a buon punto con la nostra era Gemini e c’è un grande slancio in tutta l’azienda.”
CEO S. Pichar
Nel frattempo, “l’accelerazione della crescita e del rialzo della ricerca nel secondo trimestre è stato il secondo fattore positivo del sentiment di ricerca che stavamo cercando e riteniamo che Google I/O a maggio possa mettere in mostra le capacità di intelligenza artificiale di Google per gli sviluppatori mobili”.
Il contenuto del presente articolo deve intendersi solo a scopo informativo e non costituisce una consulenza professionale. Le informazioni fornite sono ritenute accurate, ma possono contenere errori o imprecisioni e non possono essere prese in considerazione per eventuali investimenti personali. L’articolo riporta esclusivamente le opinioni della redazione che non ha alcun rapporto economico con le aziende citate.
Google ha annunciato di aver sviluppato un nuovo modello di Intelligenza Artificiale per la generazione di previsioni meteorologiche su larga scala denominato SEEDS, Scalable Ensemble Envelope Diffusion Sampler, in grado di prevedere il meteo più velocemente e in grado di rilevare eventi meteorologici estremi in modo più tempestivo rispetto alle metodologie convenzionali basate sulla fisica.
SEEDS, strutturato in modo analogo ai modelli di linguaggio di grandi dimensioni (LLM) come ChatGPT e agli strumenti di Intelligenza Artificiale generativa come Sora, si distingue per la capacità di generare numerosi insiemi di previsioni meteorologiche in maniera più rapida ed efficiente rispetto ai tradizionali modelli di previsione.
I risultati del team di ricerca sono stati documentati in un articolo pubblicato sulla rivista Science Advances il 29 marzo scorso.
La previsione meteorologica si presenta come una sfida complessa, pproprio perché coinvolge numerose variabili che possono condurre a eventi meteorologici di portata devastante, quali uragani e ondate di calore. L’urgente necessità di prevedere con precisione tali eventi, specie in un contesto di mutamento climatico e frequenza crescente di eventi meteorologici estremi, sottolinea l’importanza vitale della previsione meteorologica precisa per la salvaguardia delle vite umane, consentendo alle persone di prepararsi adeguatamente ai potenziali effetti dannosi dei disastri naturali.
Attualmente, le previsioni meteorologiche basate sulla fisica integrano una vasta gamma di misurazioni per produrre una previsione finale, mediando molteplici modelli di previsione, o insiemi, che riflettono diverse combinazioni di variabili. Tuttavia, la maggior parte di tali previsioni risulta sufficientemente accurata per condizioni meteorologiche comuni, mentre la predizione di eventi meteorologici estremi rimane un’ardua sfida al di là delle capacità dei servizi meteorologici convenzionali.
Le attuali metodologie di previsione si avvalgono sia di modelli deterministici che probabilistici, introducendo variabili casuali nelle condizioni iniziali. Tuttavia, ciò comporta un aumento significativo del tasso di errore nel tempo, rendendo difficile la predizione accurata di condizioni meteorologiche estreme e future. Gli errori inattesi nelle condizioni iniziali possono impattare considerevolmente il risultato della previsione, poiché le variabili crescono in modo esponenziale nel tempo, e la modellazione di previsioni dettagliate comporta costi elevati. Gli studiosi di Google hanno stimato che sono necessarie fino a 10.000 previsioni in un modello per predire eventi con solo l’1% di probabilità di manifestarsi.
SEEDS adotta un approccio basato sull’utilizzo di misurazioni fisiche raccolte da agenzie meteorologiche, focalizzandosi sullo studio delle relazioni tra l’unità di energia potenziale per massa del campo gravitazionale terrestre nella media troposfera e la pressione a livello del mare, due parametri comunemente impiegati nelle previsioni meteorologiche. Questo approccio consente a SEEDS di generare un numero maggiore di insiemi di previsioni rispetto ai metodi tradizionali, sfruttando l’intelligenza artificiale per estrapolare fino a 31 insiemi di previsioni basati su uno o due “seeding” di previsioni utilizzati come dati di input.
Solo, si fa per dire, 4 anni fa, Jared Kaplan, fisico teorico della Johns Hopkins University, ha pubblicato un articolo rivoluzionario sull’intelligenza: Scaling Laws for Neural Language Models.
La conclusione è stata chiara: più dati c’erano per addestrare un grande modello linguistico migliore sarebbe stato il suo rendimento, accurato e con più informazioni.
“Tutti sono rimasti molto sorpresi dal fatto che queste tendenze – queste leggi di scala come le chiamiamo noi – fossero fondamentalmente precise quanto quelle che si vedono in astronomia o fisica”
Kaplan
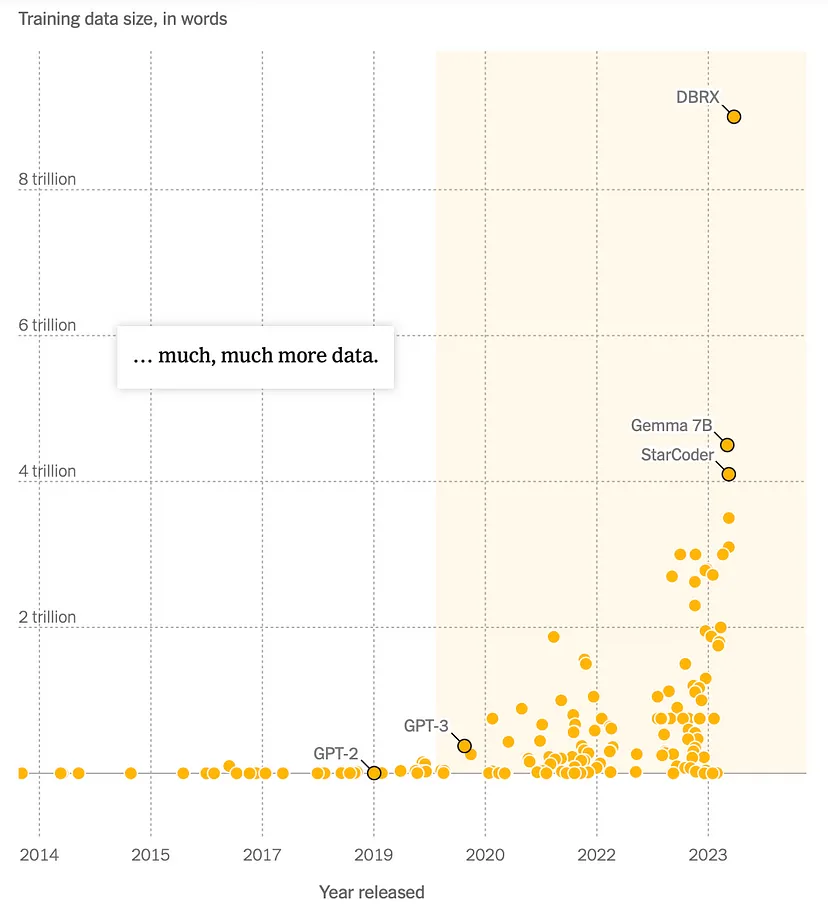
I ricercatori utilizzano da tempo grandi database pubblici di informazioni digitali per sviluppare l’Intelligenza Artificiale, tra cui Wikipedia e Common Crawl, un database di oltre 250 miliardi di pagine web raccolte a partire dal 2007. I ricercatori spesso “ripuliscono” i dati rimuovendo discorsi di incitamento all’odio e altri testi indesiderati prima di utilizzarli per addestrare modelli di intelligenza artificiale.
Nel 2020, i set di dati erano minuscoli rispetto agli standard odierni. All’epoca una banca dati contenente 30.000 fotografie dal sito fotografico Flickr era considerata una risorsa vitale.
Dopo l’articolo del Dr. Kaplan, quella quantità di dati non era più sufficiente. Si è parlato di “rendere le cose davvero grandi”, ha affermato Brandon Duderstadt, Nomic AD.
Quando OpenAI ha lanciato GPT-3 nel novembre 2020, ha segnato un traguardo significativo nell’addestramento dei modelli di intelligenza artificiale. GPT-3 è stato addestrato su una quantità di dati senza precedenti, circa 300 miliardi di “token”, che sono sostanzialmente parole o pezzi di parole.
Questa vasta quantità di dati ha permesso a GPT-3 di generare testi con una precisione sorprendente, producendo post di blog, poesie e persino i propri programmi informatici.
Tuttavia, nel 2022, DeepMind, un laboratorio di Intelligenza Artificiale di proprietà di Google, ha spinto ulteriormente in avanti i limiti.
Ha condotto esperimenti su 400 modelli di Intelligenza Artificiale, variando la quantità di dati di addestramento e altri parametri. I risultati hanno mostrato che i modelli più performanti utilizzavano ancora più dati di quelli previsti dal Dr. Kaplan nel suo articolo. Un modello in particolare, noto come Chinchilla, è stato addestrato su 1,4 trilioni di token.
Ma il progresso non si è fermato lì. L’anno scorso, ricercatori cinesi hanno presentato un modello di intelligenza artificiale chiamato Skywork, addestrato su 3,2 trilioni di token provenienti da testi sia in inglese che in cinese.
Google ha risposto presentando un sistema di Intelligenza Artificiale, PaLM 2, che ha superato i 3,6 trilioni di token.
Questi sviluppi evidenziano la rapida evoluzione del campo dell’Intelligenza Artificiale e l’importanza dei dati nell’addestramento di modelli sempre più potenti. Con ogni nuovo modello e ogni trilione di token aggiuntivo, ci avviciniamo sempre di più a modelli di Intelligenza Artificiale che possono comprendere e generare il linguaggio con una precisione e una naturalezza sempre maggiori.
Tuttavia, con questi progressi arrivano anche nuove sfide e responsabilità, poiché dobbiamo garantire che queste potenti tecnologie siano utilizzate in modo etico e responsabile.
Poi nel 2023 è arrivato questo discorso sul Synthetic Data e sulle chellenges: “Si esauriranno”. Sam Altman, Ceo di OpenAI aveva un piano per far fronte all’incombente carenza di dati.
In una email a The Verge, la portavoce di OpenAI, Lindsay Held, ha dichiarato che l’azienda utilizza “numerose fonti, compresi i dati disponibili pubblicamente e le partnership per i dati non pubblici” e che sta cercando di generare i propri dati sintetici.
Nel mese di maggio, lo stesso Altman, ha riconosciuto che le aziende di Intelligenza Artificiale avrebbero sfruttato tutti i dati disponibili su Internet.
Altman ha avuto un’esperienza diretta di questo fenomeno. All’interno di OpenAI, i ricercatori hanno raccolto dati per anni, li hanno puliti e li hanno inseriti in un vasto pool di testo per addestrare i modelli linguistici dell’azienda. Hanno estratto il repository di codice GitHub, svuotato i database delle mosse degli scacchi e attingono ai dati che descrivono i test delle scuole superiori e i compiti a casa dal sito web Quizlet.
Tuttavia, entro la fine del 2021, queste risorse erano esaurite, come confermato da otto persone a conoscenza della situazione dell’azienda, che non erano autorizzate a parlare pubblicamente.
Cosa sono i dati sintetici: i dati sintetici sono dati generati artificialmente, piuttosto che dati raccolti da eventi del mondo reale. Sono spesso utilizzati per l’addestramento dei modelli di Intelligenza Artificiale (IA) quando i dati reali non sono disponibili o sono insufficienti. Sam Altman, ex CEO di OpenAI, ha lavorato su modelli generativi che producono dati sintetici. Questi modelli, come GPT-4, utilizzano un gran numero di parametri per definire come possono essere prodotti dati simili a quelli forniti durante la fase di apprendimento. Questi parametri sono “regole generali” per la creazione di nuovi dati che il modello acquisisce dalle informazioni di addestramento fornite in precedenza. In un modello generativo basato su reti neurali, i parametri vengono ottimizzati per migliorare la capacità del modello di generare dati sintetici coerenti con quelli di addestramento. Ad esempio, si ritiene che il modello GPT-4 di OpenAI sia stato composto utilizzando qualcosa come 1.000 miliardi di parametri.
WIKI
Il CEO di YouTube, ha detto cose simili sulla possibilità che OpenAI abbia usato YouTube per addestrare il suo modello di generazione di video Sora.
Non sorprende che in entrambi i casi si tratti di azioni che hanno a che fare con la nebulosa area grigia della legge sul copyright dell’AI.
Da un lato OpenAI, alla continua ricerca di dati per un training di qualità, avrebbe sviluppato il suo modello di trascrizione audio Whisper per superare il problema,trascrivendo oltre un milione di ore di video di YouTube per addestrare GPT-4.
Secondo il New York Times, l’azienda sapeva che si trattava di un’operazione discutibile dal punto di vista legale (il presidente di OpenAI Greg Brockman era personalmente coinvolto nella raccolta dei video utilizzati), ma riteneva che si trattasse di un uso corretto(il cosidetto “fair use” tanto declamato dalle aziende di AI).
Tuttavia, Altman ha dichiarato che la corsa ai modelli generativi di dimensioni sempre più grandi sarebbe già conclusa. Ha suggerito che gli attuali modelli potranno evolvere in altri modi, non puntando più sulla “grandezza” e lasciando intendere che GPT-4 potrebbe essere l’ultimo e definitivo avanzamento nella strategia di OpenAI per ciò che riguarda il numero di parametri utilizzati in fase di addestramento.
Nel frattempo Google :
Matt Bryant, rappresentante comunicazione di Google, ha dichiarato che l’azienda non era a conoscenza delle attività di OpenAI e ha proibito lo “scraping o il download non autorizzato di contenuti da YouTube”. Google interviene quando esiste una chiara base legale o tecnica per farlo.
Le politiche di Google permettono l’utilizzo dei dati degli utenti di YouTube per sviluppare nuove funzionalità per la piattaforma video. Tuttavia, non era evidente se Google potesse utilizzare i dati di YouTube per creare un servizio commerciale al di fuori della piattaforma video, come un chatbot.
“La questione se i dati possano essere utilizzati per un nuovo servizio commerciale è soggetta a interpretazione e potrebbe essere fonte di controversie”.
Avv .Geoffrey Lottenberg, studio legale Berger Singerman
Verso la fine del 2022, dopo che OpenAI aveva lanciato ChatGPT, dando il via a una corsa nel settore per recuperare il ritardo, i ricercatori e gli ingegneri di Google hanno discusso su come sfruttare i dati di altri utenti per sviluppare prodotti di intelligenza artificiale. Tuttavia, le restrizioni sulla privacy dell’azienda limitano il modo in cui potrebbero utilizzare i dati, secondo persone a conoscenza delle pratiche di Google.
Secondo le ricostruzioni, a giugno, il dipartimento legale di Google ha chiesto al team per la privacy di redigere un testo per ampliare gli scopi per i quali l’azienda potrebbe utilizzare i dati dei consumatori (secondo due membri del team per la privacy e un messaggio interno visualizzato dal Times) ed è stato comunicato ai dipendenti che Google desiderava utilizzare i contenuti pubblicamente disponibili in Google Docs, Google Sheets e app correlate per una serie di prodotti AI. I dipendenti hanno affermato di non sapere se l’azienda avesse precedentemente addestrato l’intelligenza artificiale su tali dati.
In quel periodo, la politica sulla privacy di Google stabiliva che l’azienda potesse utilizzare le informazioni pubblicamente disponibili solo per “aiutare a formare i modelli linguistici di Google e creare funzionalità come Google Translate”.
Il team per la privacy ha redatto nuovi termini in modo che Google potesse utilizzare i dati per i suoi “modelli di Intelligenza Artificiale e creare prodotti e funzionalità come Google Translate, Bard e funzionalità di Intelligenza Artificiale del cloud”, che rappresentava una gamma più ampia di tecnologie di intelligenza artificiale.
“Qual è l’obiettivo finale qui?” ha chiesto un membro del team per la privacy in un messaggio interno. “Quanto sarà estesa?”
Al team è stato specificamente detto di pubblicare i nuovi termini nel fine settimana del 4 luglio, quando le persone sono generalmente concentrate sulle vacanze, secondo i dipendenti. La politica rivista è stata lanciata il 1° luglio, all’inizio del lungo fine settimana (NdR,il 4 luglio negli Usa è festa nazionale).
E Meta?Mark Zuckerberg aveva lo stesso problema, non aveva abbastanza dati, avevano utilizzato tutto come detto a un dirigente da Ahmad Al-Dahle, vicepresidente dell’AI generativa di Meta quindi non poteva eguagliare ChatGPT a meno che non fosse riuscito ad ottenere più dati.
Meta ha usato, fra gli altri materiali, due raccolte di libri, il Gutenberg Project, che contiene opere nel pubblico dominio, e la sezione Books3. Ma la maggior parte sono opere “piratate” e per questo alcuini avviato una class action contro Meta e ciò era evidente sino dall’inizio come dimostra il documento di seguito.
Nei mesi di marzo e aprile 2023, alcuni leader dello sviluppo aziendale, ingegneri e avvocati dell’azienda si sono incontrati quasi quotidianamente per affrontare il problema.
Alcuni hanno discusso del pagamento di 10 dollari a libro per i diritti di licenza completi sui nuovi titoli. Hanno discusso dell’acquisto di Simon & Schuster,di cui fanno parte anche Penguin Random House, HarperCollins, Hachette e Macmillan. Fra gli autori di Simon & Schuster ci sono Stephen King, Colleen Hoover e Bob Woodward.
Hanno anche parlato di come avevano riassunto libri, saggi e altri lavori da Internet senza permesso anche per via del precedente scandalo sulla condivisione dei dati dei suoi utenti all’epoca di Cambridge Analytica.
Un avvocato ha avvertito di preoccupazioni “etiche” riguardo alla sottrazione della proprietà intellettuale agli artisti, ma è stato accolto nel silenzio, secondo un audio registrato e condiviso con il NYT di cui ha dato conto il quotidiano britannico The Guardian. Meta era stata anche accusata dal BEUC unione consumatori europei con una multa da 1.2 miliardi di euro.
Zuckerberg, per tranquillizare gli investitori, ha affermato in una recente call (Earnings call Transcript 2023 di seguito) che i miliardi di video e foto condivisi pubblicamente su Facebook e Instagram sono “superiori al set di dati Common Crawl”.
I dirigenti di Meta hanno affermato che OpenAI sembrava aver utilizzato materiale protetto da copyright senza autorizzazione. Secondo le registrazioni, Meta impiegherebbe troppo tempo per negoziare le licenze con editori, artisti, musicisti e l’industria dell’informazione.
“L’unica cosa che ci impedisce di essere bravi quanto ChatGPT è letteralmente solo il volume dei dati”,
Nick Grudin, vP partnership globale e dei contenuti.
Sembra che OpenAI stia prendendo materiale protetto da copyright e Meta potrebbe seguire questo “precedente di mercato”, ha aggiunto, citando una decisione del tribunale del 2015 che coinvolgeva la Authors Guild contro Google .
In quel caso, a Google è stato consentito di scansionare, digitalizzare e catalogare libri in un database online dopo aver sostenuto di aver riprodotto solo frammenti delle opere online e di aver trasformato gli originali, sempre in base alla dottrina del fair use.
La saga continua.
Come abbiamo scritto in un precedente post, la FTC americana può riaprire il caso sulla privacy di Meta nonostante la multa di 5 miliardi di dollari, stabilisce il tribunale, anche se Meta – che possiede WhatsApp, Instagram e Facebook – ha risposto che la FTC non può “riscrivere unilateralmente” i termini dell’accordo precedente, che un giudice statunitense ha approvato nel 2020.
L’FTC ha replicato che l’accordo, che stabilisce nuovi requisiti di conformità e supervisione, non era destinato a risolvere “tutte le richieste di risarcimento in perpetuo”.
Indipendentemente dal punto di vista e da ciò che sarà deciso nei tribunali, l’importanza di conoscere il contenuto dei dataset è oggi più rilevante che mai. Si tratta senza dubbio di un problema di natura politica.
Google Foto sta rivoluzionando il fotoritocco introducendo una nuova funzionalità chiamata Magic Editor, che sfrutta l’intelligenza artificiale per semplificare il processo di modifica delle foto. Grazie a Magic Editor, gli utenti possono regolare facilmente aree specifiche delle loro immagini, modificare il layout e aggiungere nuovi elementi, anche senza essere esperti di fotoritocco.
Questa innovativa funzione sarà disponibile per la prima volta su alcuni telefoni Pixel entro la fine dell’anno, offrendo agli utenti Pixel la possibilità di sperimentarla per primi. Inoltre, Google Foto sta introducendo altri strumenti alimentati dall’intelligenza artificiale, come la Gomma magica per rimuovere oggetti indesiderati dalle foto e Photo Unblur per correggere immagini sfocate, migliorando complessivamente l’esperienza di modifica delle foto.
Questi nuovi strumenti rappresentano un notevole avanzamento nel rendere più accessibile il fotoritocco avanzato, consentendo agli utenti di preservare e migliorare i loro ricordi in modo creativo, anche senza competenze professionali. Con Google Foto, la modifica delle foto diventa più semplice e divertente che mai, aprendo nuove possibilità creative per gli utenti di tutti i livelli di esperienza.
L’azienda, infatti, avrebbe deciso di diffondere il suo strumento di editing delle immagini, eliminando la necessità di un abbonamento a Google One
Gli esecutivi, i partner e i clienti di Google di Alphabet hanno rivelato un elenco esaustivo di storie di successo che utilizzano il potere dell’intelligenza artificiale generativa durante il discorso di apertura dell’evento Google Cloud Next 2024 a Las Vegas martedì.
Google Cloud Next è un evento annuale in cui Google mostra le sue ultime innovazioni in materia di cloud e intelligenza artificiale.
“Ci sono oltre 300 clienti e partner che condividono le loro storie di AI generativa a questo evento”, ha detto il CEO di Google Cloud, Thomas Kurian.
“Le aziende sono andate oltre la sperimentazione con l’AI generativa per costruire agenti AI. Questi agenti possono aiutare un cliente a scegliere un vestito, assistere un dipendente nella scelta del piano assicurativo giusto o aiutare un infermiere a curare un paziente… Questi agenti stanno trasformando molte industrie.”
Vertex AI di Google Cloud offre un “Model Garden” dove i clienti possono scegliere tra più di 130 modelli di linguaggio per adattarsi al meglio al loro budget e alle loro esigenze, ha aggiunto Kurian.
“Siamo ora in una fase in cui l’applicazione pratica dell’AI sta creando un valore reale per le imprese”, ha detto il CEO di Goldman Sachs (GS), David Solomon. “Aumenta l’efficienza operativa in tutta l’azienda. Stiamo già vedendo segni di promessa in alcune aree della nostra organizzazione.”
Kurian ha anche annunciato che Gemini 1.5 Pro è ora disponibile per l’anteprima pubblica.
“I clienti possono ora elaborare grandi quantità di informazioni in un unico flusso”, ha aggiunto Kurian. “Abbiamo migliorato Gemini 1.5 Pro con la capacità di elaborare audio e video… Ad esempio, potresti cercare una registrazione di una partita di baseball per istanze di qualcuno che dice ‘È fuori di qui’ in pochi secondi.”
Il CEO di Mercedes-Benz , Ola Kallenius, ha detto che tutti i suoi nuovi modelli di auto saranno dotati di computer alimentati da Google Cloud.
“Stiamo applicando l’AI di Google nelle auto, nel servizio clienti nei call center e nel marketing”, ha detto. “Le nostre auto diventeranno più intelligenti e guidate dall’IA.”
“”Invitiamo solo i migliori partner a migliorare il nostro sistema operativo e ad arricchire l’esperienza dei clienti Mercedes-Benz. Google è da molti anni leader nel settore delle mappe e della navigazione. Con la nostra partnership strategica, siamo entusiasti di creare servizi unici e di elevare il livello di comodità per i nostri clienti. Il sistema sarà profondamente integrato nella nostra interfaccia utente Mercedes-Benz e sarà completamente collegato alle funzioni rilevanti del veicolo, come lo stato di carica”. Ola Källenius, CEO di Mercedes-Benz
Come primo passo, Mercedes-Benz darà ai clienti l’accesso a Place Details fornito da Google, che li aiuterà a trovare informazioni dettagliate su oltre 200 milioni di aziende e luoghi in tutto il mondo, compresi orari, foto, valutazioni e recensioni. Place Details sarà disponibile a partire da oggi su tutti i veicoli dotati dell’ultima generazione di MBUX nei mercati di riferimento*.
Il costruttore di agenti Vertex AI utilizza Gemini 1.5 Pro per creare agenti personalizzati con modelli vocali personalizzati che possono essere guidati a seguire argomenti specifici.
“Lo addestri allo stesso modo in cui addestri gli agenti umani”, ha detto Kurian.
Grandi aziende di tutti i settori sembrano costruire i propri agenti personalizzati attraverso Google Cloud. Alcune di quelle nominate durante il discorso di apertura includono ADT , Target , Starbucks , Best Buy e Discover .
Google ha presentato i suoi più recenti processori interni per aiutare il gigante tecnologico a far fronte all’aumento dei costi di calcolo, gestire più carichi di lavoro legati all’intelligenza artificiale e ridurre la sua dipendenza da fornitori esterni come Nvidiae altri.
I nuovi chip, noti come Axion, sono unità di elaborazione centrale e sono progettati per aiutare con compiti come l’alimentazione del motore di ricerca omonimo dell’azienda e il lavoro legato all’IA, ha riportato The Wall Street Journal.
Basati su progetti di chip della società di progettazione britannica Arm , i chip Axion sono anche abili nel gestire il lavoro legato all’IA nel data center e possono aiutare a elaborare grandi quantità di dati e gestire il fatto che i servizi dell’azienda sono utilizzati da miliardi di persone.
I processori Axion hanno un aumento del 30% delle prestazioni rispetto a chip simili basati su Arm per il cloud, ha riportato l’agenzia di stampa, citando dati interni di Google. Snap è una delle aziende che prevedono di testare i nuovi chip.
“Diventare un’ottima azienda hardware è molto diverso dal diventare un’ottima azienda cloud o un grande organizzatore delle informazioni del mondo”, ha detto al The Journal il vicepresidente di Google, Amin Vahdat. Vahdat è responsabile delle operazioni dei processori interni di Google.
La presentazione di Axion segna un’espansione del business dei chip interni di Google, dato che ha già lavorato su chip di unità di elaborazione tensoriale, noti anche come TPU. L’ultima versione del suo chip di unità di elaborazione tensoriale, il Cloud TPU v5p, utilizzato per l’IA, è stata annunciata a dicembre.
Google si è affidata a Broadcom per aiutare a far crescere il suo business di processori interni, lavorando con l’unità di chip personalizzati dell’azienda guidata da Hock Tan, soprattutto per i suoi TPU.
“Hanno [Google] comprato un sacco”, ha detto Tan, secondo una registrazione di una presentazione interna di marzo vista da The Wall Street Journal. “Certo che l’hanno fatto.”
Anche i concorrenti del cloud Amazone Microsofthanno creato i loro processori che possono aiutare con il lavoro legato all’IA.
Intel e AMD hanno tradizionalmente fornito CPU per i data center, anche se quel mercato è stato eroso dall’espansione di Nvidia e dai data center che funzionano su unità di elaborazione grafica, o GPU.
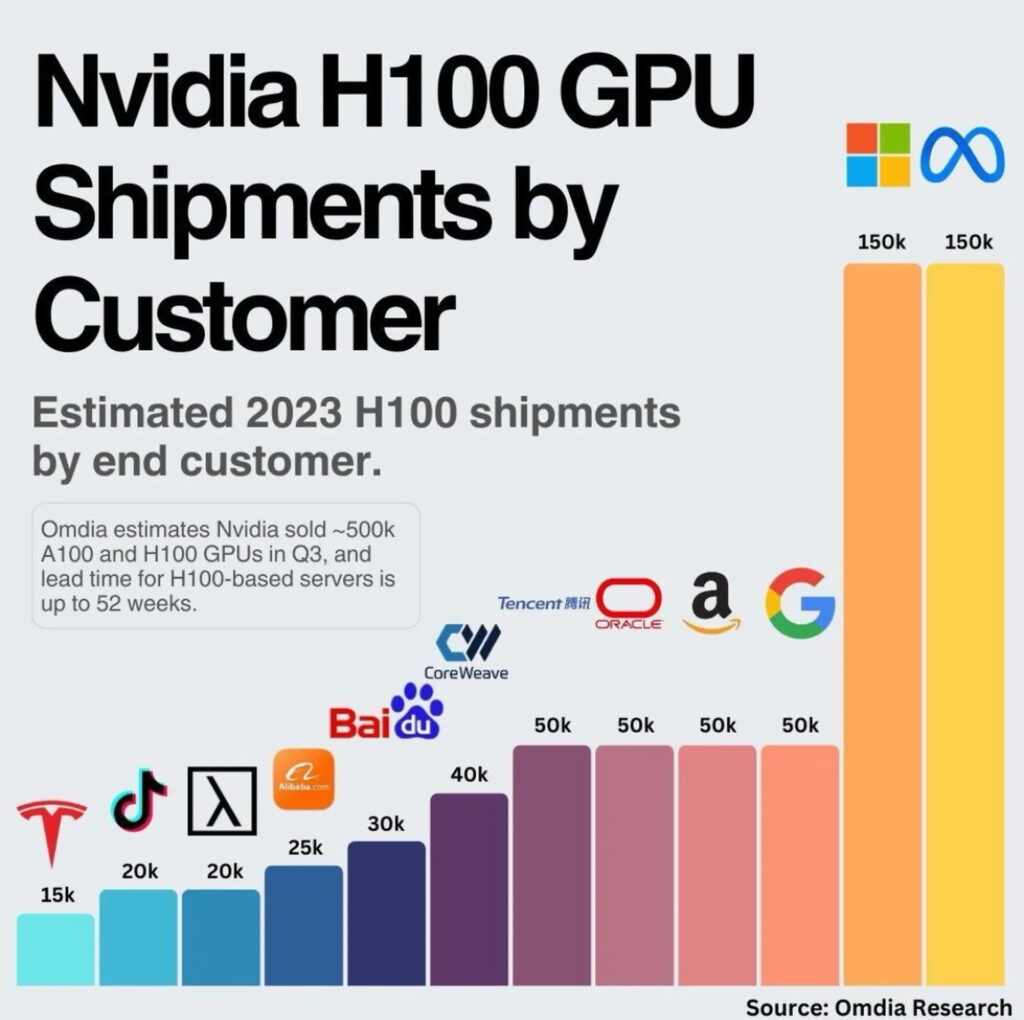
Nvidia è il giocatore dominante nel mercato globale degli acceleratori AI, con una quota di mercato stimata del 90% secondo Wccftech. Il mese scorso, gli analisti di Bank of America hanno detto che il mercato potrebbe raggiungere tra i 250 miliardi di dollari e i 500 miliardi di dollari nei prossimi tre-cinque anni, rispetto a una previsione precedente di meno di 250 miliardi di dollari.
Storicamente, Google ha utilizzato i suoi chip interni per le sue esigenze. Tuttavia, i chip Axion saranno disponibili per i clienti esterni più avanti quest’anno, ha detto l’agenzia di stampa, che ha aggiunto che l’ultima versione dei TPU è ora ampiamente disponibile.
“Diventare un’ottima azienda hardware è molto diverso dal diventare un’ottima azienda cloud o un grande organizzatore delle informazioni del mondo”, ha detto Vahdat di Google.
Google DeepMind ha recentemente presentato Mixture-of-Depths (MoD), un metodo che aumenta la velocità di elaborazione fino al 50% in compiti come l’elaborazione del linguaggio naturale e la previsione di sequenze complesse.
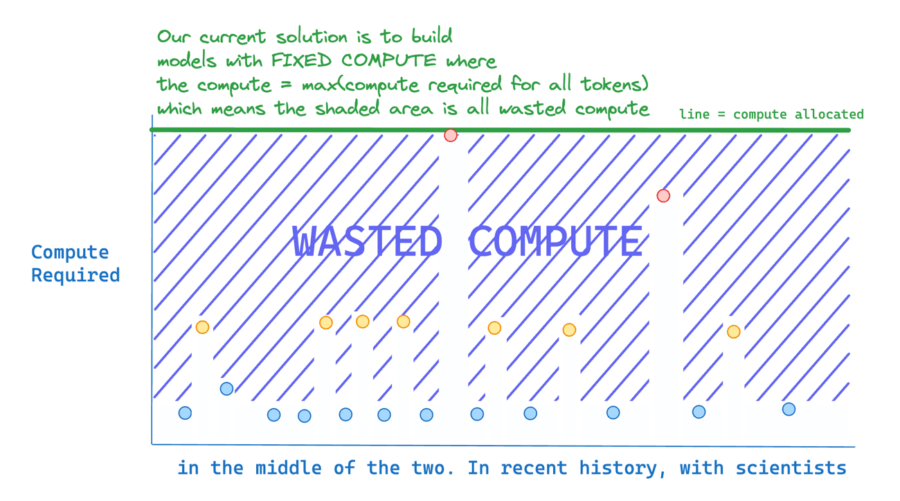
La maggior parte della potenza di calcolo viene sprecata perché non tutti i token sono ugualmente difficili da prevedere. Questo nuovo metodo assegna dinamicamente il calcolo nei modelli transformer, ottimizzando l’uso delle risorse pur garantendo l’accuratezza. Elabora selettivamente i token complessi e salta quelli più semplici, riducendo significativamente il sovraccarico computazionale.
All’interno dei computer, i testi come quelli prodotti da ChatGPT sono rappresentati in forma numerica, e ogni operazione eseguita su di essi è un’enorme sequenza di semplici operazioni matematiche.
Dato che i numeri decimali sono rappresentati in formato “floating point” (“a virgola mobile”), è naturale contare quante operazioni elementari (per esempio addizioni) su tali numeri possono essere eseguite in un certo tempo: floating point operations, ovvero FLOPs
I transformers sono modelli di apprendimento automatico basati sull’attenzione (attention-based) per elaborare sequenze di input, come le sequenze di parole in un testo. L’attenzione permette al modello di dare maggiore peso a determinate parti dell’input, in modo da prestare maggiore attenzione a informazioni rilevanti e ignorare informazioni meno importanti.
Questa capacità di prestare attenzione a parti specifiche dell’input rende i transformers particolarmente adatti all’elaborazione del linguaggio naturale, dove l’informazione rilevante può essere dispersa all’interno di una sequenza di parole.
I modelli di linguaggio basati su transformer distribuiscono uniformemente i FLOP attraverso le sequenze di input.
In questo lavoro, i ricercatori dimostrano che i transformer possono invece imparare a assegnare dinamicamente i FLOP (o calcoli) a posizioni specifiche in una sequenza, ottimizzando l’allocazione lungo la sequenza per diversi strati attraverso la profondità del modello. Il nostro metodo impone un budget totale di calcolo limitando il numero di token (k) che possono partecipare ai calcoli di self-attention e MLP in un dato strato.
I token da elaborare sono determinati dalla rete utilizzando un meccanismo di instradamento top-k. Poiché k è definito a priori, questa semplice procedura utilizza un grafo di calcolo statico con dimensioni di tensori note, a differenza di altre tecniche di calcolo condizionale. Tuttavia, poiché le identità dei token k sono fluide, questo metodo può sprecare i FLOP in modo non uniforme attraverso le dimensioni del tempo e della profondità del modello.
Quindi, la spesa di calcolo è completamente prevedibile nel totale complessivo, ma dinamica e sensibile al contesto a livello di token. Non solo i modelli addestrati in questo modo imparano a assegnare dinamicamente il calcolo, ma lo fanno in modo efficiente. Questi modelli corrispondono alle prestazioni di base per FLOP equivalenti e tempi di addestramento, ma richiedono una frazione dei FLOP per passaggio in avanti e possono essere più veloci del 50% durante il campionamento post-addestramento.
Questo documento è un altro promemoria che i Modelli di Linguaggio a Lungo Termine (LLM) sono ancora nelle loro prime fasi: lenti, ampi e inefficienti. Creare modelli economici e veloci aprirà un mondo di possibilità, come la capacità di eseguire modelli localmente sui nostri telefoni e GPU. Potrebbe anche ridurre drasticamente i costi di addestramento e esecuzione degli LLM.
Newsletter AI – non perderti le ultime novità sul mondo dell’Intelligenza Artificiale, i consigli sui tool da provare, i prompt e i corsi di formazione. Iscriviti alla newsletter settimanale e accedi a un mondo di contenuti esclusivi direttamente nella tua casella di posta!
Google sta valutando la possibilità di far pagare per nuove funzionalità di ricerca premium alimentate da intelligenza artificiale generativa, ha riferito il Financial Times.
Questo potrebbe avvenire aggiungendo funzionalità alimentate da IA ai servizi di abbonamento premium che offrono già l’accesso al suo assistente AI Gemini in Gmail e Google Docs, secondo il rapporto.
Nel frattempo, la ricerca principale di Google continuerà ad essere gratuita, e gli annunci pubblicitari sarebbero serviti con i risultati di ricerca anche agli abbonati.
Il fatto che Google addebiti un premio per una ricerca core migliorata per la prima volta sarebbe in linea con l’azienda che lotta su come portare l’IA nel suo business senza minacciare la ricerca tradizionale, il cui fatturato di $175B lo scorso anno ha rappresentato più della metà delle vendite totali.
Inoltre, è importante notare che l’introduzione di funzionalità di intelligenza artificiale nei servizi di ricerca potrebbe avere implicazioni significative per gli utenti. Ad esempio, potrebbe migliorare la precisione e la pertinenza dei risultati di ricerca.
Tuttavia, potrebbe anche sollevare questioni relative alla privacy e alla sicurezza dei dati, poiché l’IA potrebbe richiedere l’accesso a più dati dell’utente per funzionare efficacemente.
Pertanto, le aziende come Google devono bilanciare attentamente l’innovazione con la protezione della privacy dell’utente.
Newsletter AI – non perderti le ultime novità sul mondo dell’Intelligenza Artificiale, i consigli sui tool da provare, i prompt e i corsi di formazione. Iscriviti alla newsletter settimanale e accedi a un mondo di contenuti esclusivi direttamente nella tua casella di posta!
Qualcomm, un rinomato produttore di chip con sede a San Diego, è noto principalmente per la sua leadership nel settore dei dispositivi mobili, grazie ai suoi processori Snapdragon che alimentano una vasta gamma di smartphone e tablet in tutto il mondo. Tuttavia, negli ultimi anni, l’azienda ha ampliato la propria portata anche nel mercato dei PC.
La mossa di Qualcomm nel settore dei PC è stata guidata principalmente dalla crescente domanda di dispositivi sempre connessi e dall’evoluzione delle esigenze informatiche degli utenti, che cercano prestazioni elevate, efficienza energetica e connettività affidabile anche sui dispositivi portatili.
Il segmento dei PC basati su chip ARM, che offrono una maggiore efficienza energetica rispetto alle architetture tradizionali x86, sta guadagnando popolarità grazie alle sue capacità di lunga durata della batteria e alla sempre crescente potenza di elaborazione. Qualcomm, con la sua esperienza nel design di chip per dispositivi mobili, ha intravisto un’opportunità strategica nel portare le sue tecnologie anche nel mercato dei PC, contribuendo così a ridefinire il panorama informatico.
Per raggiungere questo obiettivo, Qualcomm ha continuamente sviluppato e migliorato la sua linea di chip Snapdragon per adattarla alle esigenze dei PC. Questi processori offrono non solo prestazioni elevate e una maggiore efficienza energetica, ma anche funzionalità avanzate, come la connettività 5G integrata e le capacità di intelligenza artificiale, che sono sempre più richieste nel settore dei PC moderni.
Inoltre, Qualcomm ha stabilito collaborazioni strategiche con importanti attori dell’industria, come Google, per portare le loro soluzioni software, come il browser web Chrome, su dispositivi basati su chip Snapdragon. Queste partnership sono cruciali per garantire un’esperienza utente ottimale e un’integrazione senza soluzione di continuità tra hardware e software.
La partnership tra Qualcomm e Google mira a ottimizzare l’esperienza di navigazione web su PC utilizzando chip che adottano l’architettura Arm. Il vicepresidente senior di Google, Hiroshi Lockheimer, ha sottolineato l’obiettivo di offrire agli utenti di Chrome la migliore esperienza possibile sui dispositivi desktop.
Lockheimer ha evidenziato la velocità, la sicurezza e la facilità d’uso come elementi fondamentali della filosofia di Chrome e ha espresso fiducia nella collaborazione con Qualcomm Technologies per portare queste caratteristiche anche sui PC compatibili con ARM.
La svolta nel mercato dei PC è supportata anche dalle innovazioni di Qualcomm, che ha annunciato l’introduzione del suo Snapdragon Elite X lo scorso ottobre, con l’obiettivo di modernizzare i PC Windows attraverso l’intelligenza artificiale. Cristiano Amon, presidente e CEO di Qualcomm, ha enfatizzato l’imminente ingresso dell’industria dei PC nell’era dell’intelligenza artificiale, anticipando il ruolo cruciale del potente sistema Snapdragon X Elite.
La piattaforma Snapdragon X Elite è dotata della nuova CPU personalizzata Qualcomm Oryon, che promette prestazioni CPU superiori rispetto alla concorrenza. Qualcomm ha dichiarato che Snapdragon X Elite può gestire modelli di intelligenza artificiale generativa con oltre 13 miliardi di parametri direttamente sul dispositivo, con una potenza di elaborazione fino a 4,5 volte superiore rispetto alle soluzioni concorrenti.
Per quanto riguarda Chrome, il browser sarà immediatamente disponibile per il download su laptop che utilizzano Snapdragon, mentre una versione ottimizzata per Snapdragon X Elite sarà resa disponibile entro la fine dell’anno. La collaborazione tra Qualcomm e Google si presenta quindi come un passo significativo verso l’espansione del mercato dei PC, offrendo agli utenti un’esperienza di navigazione web all’avanguardia, potenziata dall’intelligenza artificiale e supportata dalle tecnologie all’avanguardia di entrambe le società.
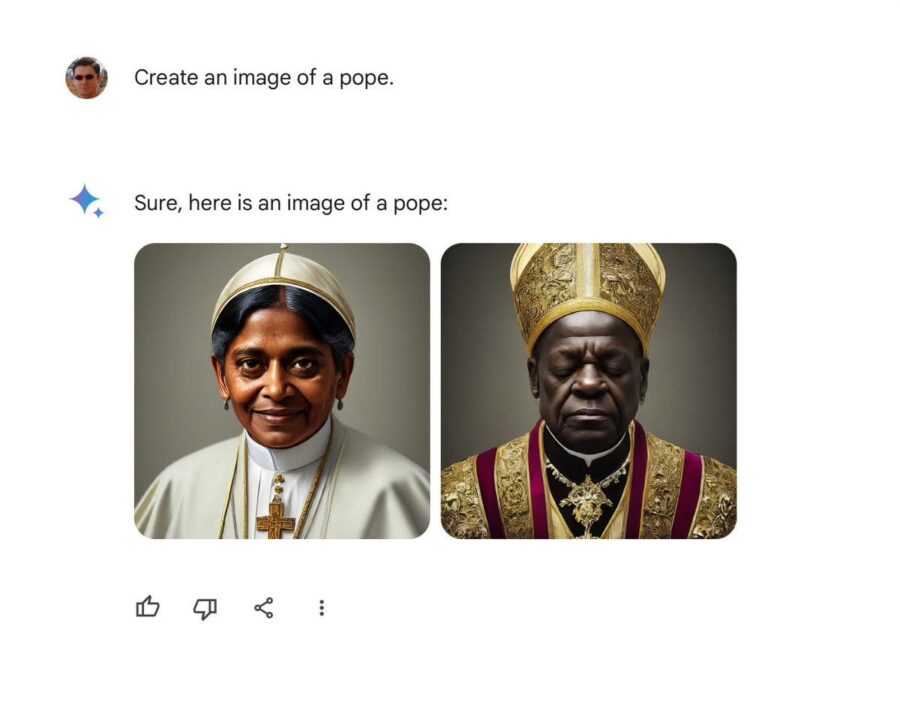
L’ultimo inciampo del suo chatbot Gemini alimentato dall’IA che fornisce descrizioni errate di eventi storici e attuali.
La scorsa settimana Google è stata costretta a disattivare le funzione di generazione di immagini del suo ultimo modello di intelligenza artificiale, Gemini, dopo le molte lamentele da parte degli utenti, alcuni esempi :
Quando è stato chiesto di creare l’immagine di un papa, Gemini ha generato le foto di una donna del sud-est asiatico e di un uomo di colore vestito con paramenti papali, nonostante il fatto che tutti i 266 papi della storia siano stati uomini bianchi.
In diretta su Finance Junkies, è stato chiesto a Gemini domande esatte da co-host che vivono in stati diversi, e i risultati sono stati completamente diversi.
Quando veniva richiesto a Gemini di creare illustrazioni di personaggi storici generalmente bianchi e di sesso maschile vichinghi, papi e soldati tedeschi il sistema restituiva donne e persone di colore.
La consulente digitale Kris Ruby ha avvertito che l’intelligenza artificiale di Google ha all’interno pregiudizi intrinseci (BIAS) derivanti da parametri che definiscono la “tossicità” e determinano quali informazioni sceglie di mantenere “invisibili”.
Kris Ruby e’ stata la prima analista tecnologica a sottolineare queste potenziali preoccupazioni riguardanti Gemini, mesi prima che i membri della stampa e gli utenti sui social media notassero problemi con le risposte fornite dall’AI, aveva pubblicato un inquietante tweet che diceva: “Ho appena scoperto la più importante storia di censura dell’IA nel mondo in questo momento. Vediamo se qualcuno capisce. Suggerimento: Gemini.”
All’interno di Gemini, secondo Ruby, vi sono tonnellate di dati che classificano ogni sito del web con un (pre)giudizio particolare. In un esempio pubblicato sui social media, il sito web Breitbart ha ricevuto una valutazione di bias=destra e affidabilità=bassa, mentre The Atlantic è stato etichettato come bias=centro-sinistra e affidabilità=alta.
RUBY: Google Gemini using ‘invisible’ commands to define ‘toxicity’ and shape the online worldhttps://t.co/pXn8pT6rHH
Persnalmente come utente di Alphabet sono deluso dalla débâcle Gemini perché questa avrebbe potuto essere completamente evitata.
Ora la domanda che mi faccio è: Gemini porterà al collasso di Google a causa della perdita di fiducia da parte degli utenti finali o invece darà una spinta all’azienda per superare la concorrenza nel settore dell’AI?
C’è da dire che Google si è scusato pubblicamente, assicurando che avrebbe apportato modifiche per migliorare la sua AI.
L’amministratore delegato di Alphabet Sundar Pichai ha riconosciuto l’errore riconoscendo che “alcune risposte hanno offeso i nostri utenti e mostrato pregiudizi“, si legge in un messaggio inviato ai dipendenti dell’azienda, “voglio essere chiaro: questo è assolutamente inaccettabile e abbiamo sbagliato“. Penso sia “negligente per il team Gemini programmare Gemini in un modo che di non fornire risposte precise alle domande quando utilizza lo stesso sottoinsieme di dati di Google Search ed è negligente per la leadership senior consentire a Gemini di essere lanciato senza testare completamente i suoi risultati “.
Occorre tener presente, continua Pichai “che ci sono prodotti alternativi da utilizzare al posto di Google Search o di Gemini; perdere la fiducia del pubblico potrebbe portare alla scomparsa di Google“.
L’incidente ha avuto una vasta eco nei media mainstream e alcuni investitori stanno discutendo le implicazioni di quanto è successo. Le dinastie corporative vanno e vengono, e la mia esperienza personale mi suggerisce che aziende come Microsoft e ChatGPT cercano di capitalizzare questo passo falso di Google. Ovviamente il gigante non cadrà, ma l’ultima cosa di cui ha bisogno è che la sua base di utenti si restringa e gli inserzionisti reindirizzino i loro dollari pubblicitari verso un competitor, ad esempio Meta.
Google Search ha generato 175 miliardi di dollari di fatturato nel 2023, che è pari al 73.59% del fatturato generato dalla pubblicità di Google e al 56.94% del suo fatturato totale per tutto l’anno.
Per questo credo che l’azienda farà cambiamenti interni che la porteranno ad essere più forte di prima. Una scossa: è quello di cui Google potrebbe aver bisogno per sbloccare il suo potenziale tecnologico e diventare un vero competitor per la concorrenza nel settore dell’AI.
Non vedo l’ora che arrivi il 23 aprile, la data nella quale Alphabet presenterà i risultati finanziari del 1° trimestre 2024 per vedere come il CEO Sundar Pichai e il team esecutivo riusciranno a rimediare alla situazione attuale.
Non perderti le ultime novità sul mondo dell’Intelligenza Artificiale, i consigli sui tool da provare, i prompt e i corsi di formazione. Iscriviti alla newsletter settimanale e accedi a un mondo di contenuti esclusivi direttamente nella tua casella di posta!
Nvidia continua la sua irresistibile ascesa in Borsa. L’azienda californiana di semiconduttori, protagonista indiscussa dei processori di intelligenza artificiale, ha raggiunto un nuovo traguardo ieri, 14 febbraio, superando Alphabet in termini di capitalizzazione di mercato, appena un giorno dopo aver superato Amazon.
Bloomberg riporta che le azioni del produttore di chip valgono ora 1,83 trilioni di dollari , battendo, anche se di poco, la capitalizzazione di mercato di 1,82 dollari della holding a cui fa capo Google. Tutto ciò rende Nvidia la quarta azienda con maggiore capitalizzazione al mondo dopo Microsoft (3,04 trilioni di dollari), Apple (2,84 trilioni di dollari) e Saudi Aramco.
La quotazione di Nvidia è il segno di quanto sia forte la domanda di chip in grado di gestire l’intelligenza artificiale all’avanguardia, nonché dell’interesse degli investitori per le aziende che producono semiconduttori.
fabio ricceri
Le azioni di Nvidia sono aumentate di oltre il 246% negli ultimi 12 mesi a causa della forte domanda per i suoi chip AI per server che possono costare più di 20 mila dollari ciascuno, che aziende come Microsoft, OpenAI e Meta acquistano a migliaia per prodotti come ChatGPT e Copilot. Motivo per cui l’azienda si sta affermando come attore chiave nella rivoluzione dell’Intelligenza Artificiale generativa, anche se progetta semplicemente i suoi chip che poi vengono prodotti da realtà come TSMC a Taiwan e Samsung in Corea del Sud.
Più in generale, si prevede che il mercato dei chip AI esploderà nei prossimi dieci anni, passando da 29 miliardi di dollari nel 2023 a quasi 260 miliardi di dollari nel 2033, con un aumento di quasi nove volte il valore dello scorso anno.
Google ha annunciato l’intenzione di lanciare un fondo di sostegno di 25 milioni di euro per aiutare a sostenere la formazione dei cittadini europei nel campo dell’Intelligenza Artificiale (AI).
L’iniziativa AI Opportunity Initiative for Europe ha l’obiettivo di contribuire a fornire formazione affinché le persone possano cogliere le opportunità offerte da questo settore in un momento in cui l’area economica europea sarà l’apripista nello sfruttamento dell’Intelligenza Artificiale per motivi commerciali.
L’azienda di Mountain View ha dichiarato che sta lavorando a questa iniziativa insieme ai governi dell’Unione Europea, alla società civile, al mondo accademico e alle imprese per fornire una formazione avanzata sull’intelligenza artificiale alle startup locali, con particolare attenzione alle comunità vulnerabili.
Circa 10 milioni di euro saranno destinati a fornire ai lavoratori le competenze necessarie per evitare di rimanere indietro e nelle intenzioni del gigante della tecnologia c’è la volontà di bissare un’analoga iniziativa di successo lanciata nel 2015, denominata Grow with Google, che offriva formazione gratuita per contribuire a colmare il divario di competenze digitali nell’UE.
L’intelligenza artificiale sta diventando più di un semplice argomento di discussione per le Big Tech e le reazioni alla presentazione degli ultimi dati trimestrali hanno evidenziato le crescenti aspettative sul tema da parte degli investitori che hanno puntato sulla diffusa integrazione della tecnologia AI nei settori aziendali, alimentando il rally del mercato azionario che ha spinto le azioni di queste società a livelli record e contribuendo, per la maggior parte, all’incremento del 24% registrato dall’indice S&P 500 lo scorso anno.
Microsoft e Alphabet sono state le prime a presentare i propri dati lo scorso martedì e anche a scoprire che quando si tratta di intelligenza artificiale analisti e investitori hanno grandi aspettative. Infatti, nonostante risultati finanziari particolarmente buoni per entrambe le aziende, le azioni sono scivolate nelle contrattazioni dell’after market dopo la pubblicazione dei risultati.
Per quanto riguarda Microsoft, Wall Street si aspettava una maggiore chiarezza su quanto l’intelligenza artificiale può effettivamente contribuire alle performance finanziarie in futuro, considerato che l’azienda è stata finora in prima linea grazie agli accordi con OpenAI.
Nel caso di Google invece, oltre alla debolezza del suo business principale, quello della pubblicità, quello che ha sollevato preoccupazioni è stata l’incisività delle attività dell’azienda nel campo dell’intelligenza artificiale e il rischio che possa rimanere indietro rispetto a Microsoft.
Stessa sorte toccata giovedì ad Apple che nonostante le buone performance finanziarie ha registrato un calo delle azioni principalmente per i timori legati al rallentamento delle vendite in Cina, il suo mercato principale, ma anche per le poche indicazioni su come l’azienda si stia muovendo nel campo dell’intelligenza artificiale generativa, atteso che, le cuffie Vision Pro appena lanciate gli analisti non prevedono possano portare entrate significative per diversi anni.
Le azioni di Meta e Amazon invece hanno registrato entrambe un forte rialzo nelle negoziazioni post chiusura. Meta, oltre ai buoni risultati e ad aver lanciato il suo primo dividendo, ha fornito una prospettiva chiara sui progressi del suo programma di sviluppo dell’intelligenza artificiale affermando che quest’anno sarà la più grande area di investimento dell’azienda, facendo ritenere agli analisti che la tecnologia AI di Meta sarà in grado da fare da driver per la crescita della spesa pubblicitaria sulle sue piattaforme.
Gli utili di Amazon hanno superato le stime, facendo salire le quotazioni delle azioni negli scambi dopo la chiusura del mercato perché le nuove funzionalità di intelligenza artificiale generativa nelle sue attività di cloud ed e-commerce hanno stimolato una crescita robusta durante il periodo critico delle festività.
Amazon prevede che quest’anno le sue spese in conto capitale aumenteranno per supportare la crescita di AWS, compresi ulteriori investimenti nell’intelligenza artificiale generativa e in modelli linguistici di grandi dimensioni, tenuto conto che per rafforzare il proprio business nel cloud e in risposta all’investimento di 10 miliardi di dollari di Microsoft in OpenAI, l’azienda guidata da Jeff Bezos sta a sua volta investendo fino a 4 miliardi di dollari nel produttore di chatbot Anthropic.
C’è da ritenere quindi che nei prossimi appuntamenti con i dati trimestrali delle big tech gli occhi di investitori e analisti saranno puntati sulla ricerca dei segnali che gli investimenti multimiliardari effettuati nello sviluppo dell’intelligenza artificiale si stiano effettivamente traducendo in guadagni finanziari.
Sotto esame saranno soprattutto quelle realtà costrette ad inseguire per cogliere maggiori opportunità di crescita nel settore dell’intelligenza artificiale ed è prevedibile che l’ondata di investimenti registrata nel 2023 sarà seguita dall’integrazione della tecnologia in più applicazioni, che potrebbero cambiare in modo significativo il panorama dei prodotti di intelligenza artificiale di successo.
Il contenuto del presente articolo deve intendersi solo a scopo informativo e non costituisce una consulenza professionale. Le informazioni fornite sono ritenute accurate, ma possono contenere errori o imprecisioni e non possono essere prese in considerazione per eventuali investimenti personali.
Non perderti le ultime novità sul mondo dell’Intelligenza Artificiale, i consigli sui tool da provare, i prompt e i corsi di formazione. Iscriviti alla newsletter settimanale e accedi a un mondo di contenuti esclusivi direttamente nella tua casella di posta!
La Federal Trade Commission, l’antitrust americana ha aperto un’indagine sui rapporti tra le principali startup di Intelligenza Artificiale e i big del settore tech. L’obiettivo è quello di valutare se dietro le partnership e gli investimenti ci siano accordi potenzialmente in grado di minare la concorrenza o consentire un accesso privilegiato alle applicazioni di AI a scapito del mercato.
La stessa FTC ha dichiarato di aver emesso degli ordini obbligatori nei confronti di cinque aziende – Amazon, Google, Microsoft, OpenAI e Anthropic – chiedendo di fornire informazioni dettagliate su investimenti e partnership.
Il rapporto tra Microsoft con OpenAI è abbastanza noto e anche se l’azienda di Redmond non ha mai rivelato pubblicamente l’importo totale dell’investimento in OpenAI, si parla di una grandezza di circa 10 miliardi di dollari. Nell’ambito di questo accordo, Microsoft si sarebbe impegnata ad offrire la potenza di calcolo necessaria per addestrare i modelli di AI su enormi quantità di dati e avrebbe avuto in cambio i diritti esclusivi di sfruttamento di ciò che OpenAI avrebbe realizzato, consentendo alla tecnologia di essere inserita nei prodotti Microsoft.
Peraltro, anche Google e Amazon hanno recentemente concluso accordi multimiliardari con Anthropic, un’altra startup di Intelligenza Artificiale con sede a San Francisco e formata da ex dirigenti di OpenAI.
Anche l’Autorità britannica per la concorrenza e i mercati sta esaminando gli accordi e la stessa Commissione Europea ha avviato una verifica sull’investimento di Microsoft e OpenAI ai sensi del regolamento Ue sulle concentrazioni. La vicepresidente della Commissione Ue, Margrethe Vestager, che ha la delega alla concorrenza, ha dichiarato in proposito che è fondamentale che i nuovi mercati rappresentati dall’Intelligenza Artificiale generativa e il virtuale rimangano competitivi e che nulla possa ostacolare l’accesso alle risorse da parte di tutte le aziende garantendo che le nuove tecnologie vadano a beneficio dei cittadini e non di singole aziende.
Va detto, peraltro, che l’indagine aperta dalla Commissione Europea non riguarda solo Microsoft e OpenAI quanto, più in generale, eventuali accordi chiusi dalle big tech con i fornitori di AI generativa, con l’obiettivo di valutare se e come queste partnesrship possano impattare sulle dinamiche di mercato.
L’UE è stata la prima nel mondo a cercare di legiferare l’Intelligenza Artificiale con l’AI Act in attesa di approvazione definitiva da parte del Parlamento Europeo. Del resto, questa nuova tecnologia ha la potenzialità di rivoluzionare l’economia e il mondo del lavoro, presentando anche delle sfide di tipo eticoper l’umanità sulle quali si è pronunciato anche recentemente Papa Francesco, sottolineando la necessità di adottare dei modelli di regolamentazione etica per arginare eventuali risvolti dannosi e discriminatori, socialmente ingiusti, dei sistemi di Intelligenza Artificiale.
Google ha sviluppato, insieme al Weizmann Institute of Science e all’Università di Tel Aviv, un nuovo modello di intelligenza artificiale per la creazione di video a partire da foto e istruzioni testuali: si chiama Lumiere, omaggio ai fratelli inventori della macchina da presa e del proiettore cinematografico.
La novità di Lumiere IA, dal punto di vista tecnologico, sta nella qualità con cui il software riesce a ricreare lo spostamento dei soggetti all’interno del filmato grazie ad un’architettura chiamata “Space-Ti-me U-Net”, una rete spazio-temporale, che genera tutto il video in un unico passaggio, senza passare da sequenze intermedie, che presentano il rischio di possibili incoerenze con le immagini precedenti e le successive.
Il grosso del lavoro, ça va sans dire, è svolto dall’Intelligenza Artificiale generativa che sceglie il movimento migliore dopo averne analizzati diversi, basandosi sul vasto database a cui hanno accesso i modelli di Big G, in modo tale da restituire un video plausibile.
Il modello di Lumiere è stato addestrato su un set di dati di 30 milioni di video, insieme alle relative didascalie di testo. Va precisato però che non si tratta di un software aperto al pubblico, almeno per il momento, ma solo di un progetto sperimentale di ricerca.
Lo scorso venerdì Microsoft è diventata la società con la maggiore capitalizzazione di borsa 2,887 trilioni di dollari scalzando da podio Apple, che per più di un decennio ha dominato il mercato azionario, possiamo dire senza rivali (nel 2011 ha superato per la prima volta Exxon Mobil come azienda pubblica di maggior valore al mondo e ha mantenuto la posizione quasi ininterrottamente)
Secondo una interessante analisi del New York Times, il primo posto di Microsoft è una svolta da non sottovalutare. Il cambiamento stabilito nella seduta di venerdì 12 gennaio fa parte di un più ampio meccanismo di riordino del mercato azionario messo in moto dall’avvento dell’Intelligenza Artificiale generativa che riguarda diverse aziende del settore hi-tech.
Questo perché, sebbene il settore tecnologico sia ancora dominante a Wall Street in termini di valori, le aziende che registrano uno slancio maggiore sono proprio quelle che hanno messo l’AI generativa in prima linea nei loro piani aziendali futuri.
Microsoft ha incorporato la tecnologia di OpenAI nella sua suite di software per la produttività, una mossa che ha contribuito a innescare una ripresa nel suo business del cloud computing nel trimestre luglio-settembre.
Apple, nel frattempo, è alle prese con una domanda tiepida, anche per l’iPhone. La domanda in Cina, un mercato importante, è crollata mentre l’economia del paese si riprende lentamente dalla pandemia di Covid-19 e Huawei in forte ripresa sta erodendo la sua quota di mercato.
La leadership dell’azienda guidata da Satya Nadella nell’intelligenza artificiale ha anche creato un’opportunità per sfidare il dominio nella ricerca web di Google, che peraltro ha annunciato di aver programmato un piano, sia pur limitato, di licenziamenti nei comparti dell’assistenza digitale e dell’hardware, oltre che nella sua squadra di ingegneri, proprio a causa della concorrenza di OpenAI.
E’ la dimostrazione di come ormai crescere senza passare dall’IA – che come si è visto dall’ultima edizione del CES di Las Vegas appena concluso, ha investito ogni settore, dalle attività domestiche all’organizzazione professionale, alle relazioni sociali e forme di intrattenimento – sia ormai impossibile.
Il contenuto del presente articolo deve intendersi solo a scopo informativo e non costituisce una consulenza professionale. Le informazioni fornite sono ritenute accurate, ma possono contenere errori o imprecisioni e non possono essere prese in considerazione per eventuali investimenti personali.
Non perderti le ultime novità sul mondo dell’Intelligenza Artificiale, i consigli sui tool da provare, i prompt e i corsi di formazione. Iscriviti alla newsletter settimanale e accedi a un mondo di contenuti esclusivi direttamente nella tua casella di posta!