

Quando si parla di privacy, Google non è certo estraneo a sollevare polveroni, ma stavolta il gigante della Silicon Valley ha dovuto fare i conti con la giustizia texana. Il procuratore generale del Texas, Ken Paxton, ha annunciato che Google ha accettato di sborsare ben 1,375 miliardi di dollari per risolvere una causa che l’accusava di violare la privacy dei dati dei propri utenti. Una somma che fa sembrare “piccolo” l’importo che ha dovuto pagare Meta lo scorso luglio, in un caso simile riguardante il riconoscimento facciale.
Tag: google Pagina 2 di 7
Il mondo digitale, come ogni bar malfamato di Caracas, ha i suoi borseggiatori. Solo che qui non usano le mani, ma le notifiche. Quelle stesse notifiche che ti compaiono sullo smartphone alle tre di notte con promesse oscene di guadagni facili, antivirus miracolosi e principi nigeriani in cerca d’amore. Google ha deciso di affrontare questa fiera del click truffaldino con una mossa che sa di rivoluzione (ma con il solito retrogusto di controllo totale): Chrome su Android ora usa intelligenza artificiale on-device per analizzare le notifiche e sputtanare in tempo reale quelle truffaldine. Tutto questo, ovviamente, senza mandare nulla ai server centrali. Giurano.

Hai presente quando pensavi che l’AI mobile fosse solo una scusa per filtri da influencer? E invece Google piazza un colpo da ko con il suo generatore di video da immagini, integrato direttamente nei nuovi smartphone Honor. Un lancio che sa di bivio tra “wow” e “mah, serviva proprio?” e che promette di trasformare ogni foto in un mini‐film da festival.

Questa estate a Mountain View non serviranno solo condizionatori. Serviranno avvocati, lobbisti e un discreto quantitativo di ansiolitici. Nella sede centrale di Google, l’aria si sta facendo densa di preoccupazioni, non solo per l’aria condizionata mal tarata, ma per il rischio concreto di un ridimensionamento epocale del suo core business: la ricerca.
Dopo un processo durato tre settimane, che si è chiuso a Washington con toni da processo storico (perché in effetti lo è), Google è in attesa della decisione di un giudice federale che potrebbe stravolgere le fondamenta economiche su cui l’azienda ha costruito il suo impero. Non è più questione di se, ma di quanto e come il giudice vorrà tagliare le unghie al colosso della Silicon Valley. E non parliamo di dettagli tecnici, ma del cuore pulsante di Alphabet: il motore di ricerca.

Sette percento. In una giornata. Per un’azienda come Google, pardon Alphabet, non è un piccolo raffreddore da mercato: è una febbre improvvisa, di quelle che ti costringono a fermarti e domandarti se è solo influenza o l’inizio di qualcosa di più serio. Il tonfo è avvenuto dopo la testimonianza di Eddy Cue, alto dirigente Apple, in un’aula di tribunale a Washington. Cue, con la solennità tipica di chi sa che sta dicendo qualcosa di potenzialmente storico, ha ammesso che per la prima volta in assoluto il volume di ricerca su Safari – dove Google è ancora il motore di default è diminuito. Non rallentato. Non stagnato. Diminuito.
Questa frase, lanciata in aula quasi come una bomba ad orologeria, ha avuto un eco immediato a Wall Street. Il mercato non ama le sorprese, e meno ancora ama i segnali di declino sistemico. Ma il punto è: davvero è una sorpresa?

Powering a New Era of American Innovation
La narrativa sulla corsa all’intelligenza artificiale ha sempre avuto due protagonisti: chi costruisce i modelli e chi li alimenta. Ma ora Google cambia bruscamente il copione e ci sbatte in faccia una realtà che Silicon Valley e Washington sembravano troppo impegnate a ignorare: l’AI sta prosciugando la rete elettrica, e il collasso non è più una distopia cyberpunk ma una scadenza tecnica misurabile in megawatt.
Nel suo ultimo atto da gigante responsabile o, se preferite, da monopolista in preda a panico sistemico, Google ha pubblicato una roadmap energetica in 15 punti per evitare che il futuro dell’AI venga spento da un banale blackout. Non si parla più solo di chip, modelli linguistici o investimenti in data center: il vero nodo è la corrente, l’infrastruttura fisica, i cavi, i trasformatori e soprattutto le persone che li fanno funzionare. Perché senza una rete elettrica moderna e resiliente, anche il più potente dei modelli transformer non è altro che un costoso fermacarte digitale.
Google, sempre più protagonista nell’universo della tecnologia, sta introducendo una nuova funzionalità per le famiglie, permettendo ai minori di utilizzare la sua intelligenza artificiale avanzata, Gemini, sui dispositivi Android monitorati tramite Family Link. Questo passo è stato annunciato tramite un’email inviata ai genitori, che presto vedranno i propri figli avere accesso a Gemini, un’IA progettata per assisterli in attività quotidiane come i compiti o la lettura di storie.

Il tempismo è quasi comico. Da mesi circolano denunce, lamentele e segnalazioni sul fatto che i giganti del tech, Google in testa, abbiano usato i contenuti pubblici del web per addestrare le loro AI senza consenso esplicito. Eppure, la reazione collettiva era sempre la stessa: un’alzata di spalle ben coreografata. Tutti facevano finta di non sapere. Nessuno voleva toccare il vespaio. Dovevamo aspettare Bloomberg, ancora una volta, per vedere la bolla scoppiare in diretta.

Nel mondo incerto dei Large Language Model, dove il confine tra genialità e delirio si gioca in pochi token, Google sgancia la bomba: un manuale di 68 pagine sul prompt engineering. Non è il solito PDF da policy interna. È la nuova Torah per chi maneggia IA come un alchimista contemporaneo, dove ogni parola può scatenare un miracolo… o un mostro.
La notizia completa (slides incluse) è qui: Google Prompt Engineering Guide

Google rilancia la sfida ad Adobe, Meta e OpenAI con un aggiornamento di Gemini che punta dritto al cuore dell’editing visivo. Da oggi, o meglio “nelle prossime settimane”, l’app Gemini sarà in grado di modificare direttamente immagini caricate dagli utenti o generate dall’AI stessa. Il tutto senza dover uscire dall’app o usare software terzi: è l’alba dell’editing nativo AI-driven secondo Mountain View.
Per capirci: carichi una foto tua, clicchi su “modifica” e puoi cambiare lo sfondo, aggiungere elementi, togliere persone, persino vedere che faccia avresti con i capelli viola. Fantascienza? No, solo la nuova normalità spinta al massimo dalla consumer AI.
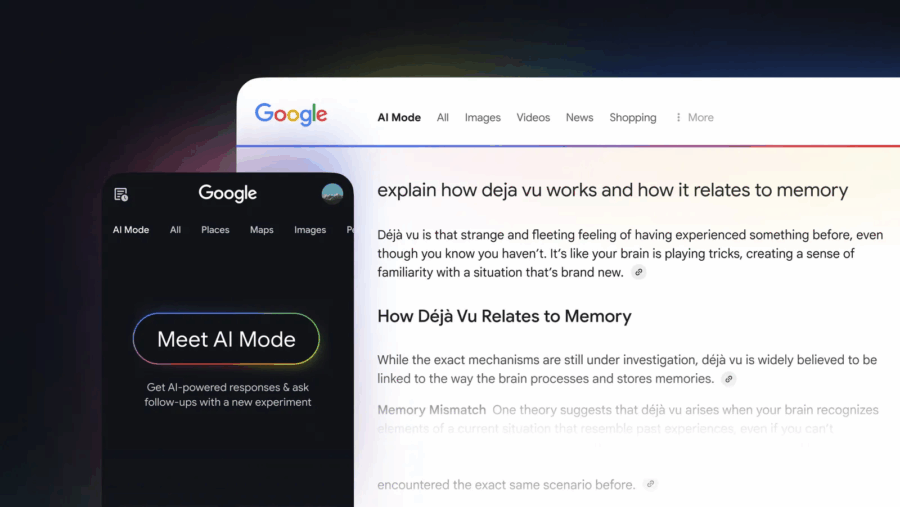
Google ha appena lanciato una nuova funzionalità chiamata “AI Mode”, una modalità di ricerca che sostituisce i tradizionali risultati con risposte generate dall’intelligenza artificiale. Questa innovazione, alimentata dal modello Gemini 2.0, è ora disponibile per tutti gli utenti statunitensi iscritti a Google Labs, senza più necessità di lista d’attesa.
AI Mode si distingue dalle precedenti funzionalità come gli AI Overviews. Mentre questi ultimi offrono brevi riassunti sopra i risultati di ricerca, AI Mode fornisce risposte più dettagliate e personalizzate, integrando informazioni in tempo reale, dati di prodotti e attività commerciali locali.
Una delle caratteristiche principali è la capacità di gestire query complesse e multipartite. Ad esempio, è possibile chiedere: “Qual è la differenza tra le funzionalità di monitoraggio del sonno di un anello intelligente, uno smartwatch e un tappetino di tracciamento?”. AI Mode utilizzerà un approccio multistep per elaborare la risposta, cercando informazioni pertinenti e adattando la risposta in base ai dati trovati.
Inoltre, AI Mode introduce schede visive per luoghi e prodotti. Ad esempio, cercando “migliori negozi vintage per mobili mid-century modern”, verranno mostrati negozi locali con informazioni come valutazioni, recensioni, orari di apertura e dettagli promozionali.
Questa mossa di Google è vista come una risposta diretta alla crescente concorrenza di servizi come Perplexity e OpenAI’s ChatGPT, che offrono esperienze di ricerca basate sull’intelligenza artificiale . Con AI Mode, Google mira a mantenere la sua posizione dominante nel mercato della ricerca online, offrendo un’esperienza più interattiva e personalizzata.
Tuttavia, l’introduzione di AI Mode solleva anche preoccupazioni tra gli editori online, che temono una riduzione del traffico verso i loro siti a causa delle risposte generate dall’IA . Google sostiene che queste nuove funzionalità aumenteranno l’engagement degli utenti e forniranno un contesto migliore, ma resta da vedere come evolverà l’ecosistema della ricerca online.
Per ora, AI Mode è disponibile solo per gli utenti statunitensi iscritti a Google Labs. Non è ancora chiaro quando verrà esteso ad altri paesi, ma è probabile che Google stia monitorando attentamente l’adozione e il feedback degli utenti prima di un lancio globale.
Per ulteriori dettagli, è possibile consultare l’annuncio ufficiale di Google: (blog.google).

Quello che si sta profilando all’orizzonte non è un semplice accordo tecnologico: è un armistizio tra titani, una tregua armata tra due delle aziende più potenti del pianeta. Google e Apple stanno per siglare un’intesa storica per integrare Gemini, il modello linguistico di Google, direttamente nei dispositivi iOS. Siri, la tanto vituperata assistente digitale di Apple, potrebbe finalmente evolversi e diventare qualcosa di più di una segreteria vocale di lusso. La conferma è arrivata in pieno processo antitrust, come spesso accade quando la verità salta fuori sotto giuramento: Sundar Pichai ha dichiarato che l’accordo con Apple per integrare Gemini dovrebbe chiudersi entro metà 2025. E il rollout? Entro fine anno.
Il sottotesto è chiaro: Apple non vuole restare schiacciata tra l’entusiasmo popolare per ChatGPT e la spinta tentacolare di Google. E se l’IA è il nuovo petrolio, Cupertino non intende comprarlo solo da un pozzo. La strategia è multi-modello, pluralista, e profondamente opportunistica. Craig Federighi lo aveva lasciato intendere già lo scorso anno: l’obiettivo è offrire agli utenti una scelta tra diversi modelli di IA, Gemini incluso. Questo spiega perché nell’ultima beta di iOS 18.4 sono comparsi riferimenti espliciti a “Google” come possibile opzione all’interno di Apple Intelligence. Non è un bug, è una bandiera piantata in territorio nemico.

Google ha deciso di rimettere mano a Gmail su mobile, e come spesso accade, lo fa senza chiedere il permesso. Se sei un utente Android o iOS, preparati a trovarti un’interfaccia diversa, nuove trovate “intelligenti” e, ovviamente, una sottile ma inevitabile pressione a usare di più la loro AI. Gli aggiornamenti sono in rollout globale sia per gli account Workspace sia per quelli personali, quindi non sperare di scamparla.
Partiamo dal pezzo forte: i possessori di tablet Android e dei cosiddetti foldable (per chi ancora ci crede) riceveranno un’interfaccia Gmail finalmente quasi adulta. In modalità landscape ora puoi spostare liberamente il divisorio tra la lista delle email e la conversazione aperta. Vuoi vedere solo le email? Trascina tutto a sinistra. Vuoi vedere solo il contenuto? Spingi il divisore a destra. È un concetto di base talmente semplice che quasi ti chiedi come abbiano fatto a non implementarlo prima. Ah già, volevano tenere alto il tasso di frustrazione utente. A scanso di equivoci, l’animazione ufficiale che mostra il tutto in azione è una tristezza avvilente, ma se sei curioso, puoi dare un’occhiata qui.

Non bastava qualche chitarrina stonata generata dall’intelligenza artificiale per mettere a soqquadro il già fragile ecosistema musicale, no. Google DeepMind ha deciso di alzare il volume (e l’asticella) presentando il suo nuovo prodigio: Lyria 2. Un upgrade spietato e chirurgico del suo Music AI Sandbox, pensato non per i soliti nerd da cameretta, ma per produttori, musicisti e cantautori professionisti che, guarda caso, cominciano a capire che l’IA non è più un giocattolo, ma un concorrente diretto sul mercato creativo.
Questa nuova versione di Lyria non si limita a generare canzoncine ascoltabili solo dopo sei gin tonic. Produce audio di qualità da studio, pensato per integrarsi senza cuciture in flussi di lavoro professionali. Parliamo di un salto quantico nella qualità dell’output: suoni puliti, dinamica curata, senso della struttura musicale… insomma, roba che non ti aspetteresti mai da una macchina, e invece eccoci qui a constatare che forse il chitarrista hipster del tuo gruppo può essere sostituito da un prompt di testo ben scritto.

La recente pubblicazione del rapporto tecnico relativo a Gemini 2.5 Pro da parte di Google ha sollevato non poche polemiche, soprattutto per la sua scarsità di dettagli utili. Dopo settimane di attesa, il gigante di Mountain View ha finalmente rilasciato un documento che, tuttavia, lascia ancora molti interrogativi sulla sicurezza del suo modello. Come sottolineato da Peter Wildeford in un’intervista a TechCrunch, il rapporto in questione è troppo generico, al punto da risultare quasi inutile per una valutazione accurata della sicurezza del sistema.
L’assenza di dettagli chiave rende impossibile per gli esperti del settore capire se Google stia effettivamente rispettando gli impegni presi, e se stia implementando tutte le necessarie misure di protezione per garantire un utilizzo sicuro di Gemini 2.5 Pro. Il documento pubblicato non fornisce informazioni sufficienti a valutare se il modello sia stato sottoposto a test adeguati, né se le vulnerabilità potenziali siano state analizzate in modo rigoroso. In sostanza, non c’è modo di capire come Google stia affrontando la questione della sicurezza nei suoi modelli AI più recenti, lasciando un alone di opacità che solleva dubbi sulle reali intenzioni dell’azienda.

Nel silenzioso fermento delle aule federali, si sta giocando una partita che potrebbe riscrivere le fondamenta della ricerca online. A luglio scorso, OpenAI ha bussato alla porta di Google con una richiesta non proprio modesta: accedere al suo motore di ricerca per alimentare un progetto chiamato SearchGPT, ovvero un ibrido tra motore AI e indicizzazione in tempo reale. Una mossa tanto audace quanto rivelatrice delle ambizioni di OpenAI nel diventare la piattaforma da cui passa la conoscenza digitale del futuro.
La risposta di Google? Un secco “no”, datato 13 agosto. Una data che non cade a caso: pochi giorni prima, un giudice federale aveva ufficialmente sancito che Google detiene un monopolio illegale nel mercato delle ricerche online. Curioso tempismo, verrebbe da dire. Ma la storia, come sempre, si complica.

Quando la giustizia statunitense mette una Big Tech all’angolo, il gioco si fa interessante. E questa volta il palco è dominato da Google, accusata formalmente di monopolizzare il mercato della ricerca online, con un processo che potrebbe portare a un evento storico: lo spin-off forzato del browser Chrome. A spingere sull’acceleratore non è solo il Dipartimento di Giustizia, ma anche OpenAI, che osserva la situazione con un certo appetito predatorio.
Nick Turley, il responsabile di ChatGPT, lo ha detto chiaro e tondo in aula: “Sì, saremmo interessati a comprarlo, come molte altre parti”. È la prima volta che OpenAI mostra pubblicamente la sua ambizione non solo di essere presente nel browser più usato al mondo, ma addirittura di metterci le mani sopra. Il contesto? Un’audizione in cui si decide il futuro della struttura industriale del search online. Il giudice Amit Mehta dovrà stabilire entro agosto quali pratiche commerciali Google dovrà abbandonare e, soprattutto, se dovrà separarsi dal suo gioiellino da miliardi: Chrome.

Quando sei il re indiscusso del motore di ricerca globale e ti ritrovi sul banco degli imputati per monopolio illegale, non combatti per la tua innocenza, combatti per mantenere il potere il più possibile intatto. Questa settimana, il processo antitrust contro Google si è trasformato in un teatrino squisitamente illuminante su come funziona davvero il capitalismo delle Big Tech. E no, non è un complotto: è tutto documentato, verbalizzato e testimoniato davanti a un giudice federale.
Peter Fitzgerald, vice-presidente delle partnership di Google, ha confermato davanti al tribunale che da gennaio Google paga Samsung una cifra mensile definita “enorme” per preinstallare l’app Gemini AI su tutti i dispositivi Samsung di nuova generazione, come se fosse il nuovo Bixby, ma con molta meno personalità e molti più dati da succhiare. E no, non è uno scherzo. La stessa Samsung, che da anni tenta di affermare il proprio assistente vocale, ha sostanzialmente gettato la spugna per un assegno a sei (forse sette) zeri.
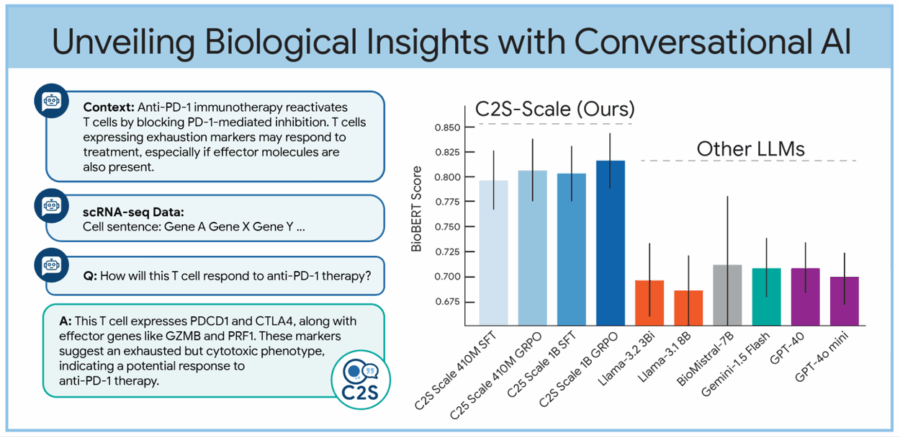
Sembra un’idea uscita da un laboratorio segreto di Google X, e invece è realtà open source. Prendi una cellula, una qualsiasi, una di quelle che ti porti appresso ogni giorno senza degnarla di uno sguardo. Quella cellula sta facendo qualcosa: produce proteine, si divide, reagisce agli stimoli. Ora immagina di trasformare tutte queste attività, tradizionalmente descritte da migliaia di numeri inaccessibili ai più, in una semplice frase in inglese. Voilà: benvenuti nell’era del linguaggio cellulare, dove le cellule parlano e i Large Language Models (LLM) ascoltano.
Dietro questa rivoluzione semiotica c’è C2S-Scale, una suite di modelli linguistici sviluppata a partire dalla famiglia Gemma di Google, pensata per interpretare e generare dati biologici a livello monocellulare. L’acronimo sta per “Cell-to-Sentence Scale” e il concetto è tanto semplice quanto spiazzante: convertire il profilo di espressione genica di una singola cellula in una frase testuale. Come trasformare una sinfonia genetica in una poesia sintetica. A quel punto puoi parlarci. Chiederle cosa fa. O come si comporterebbe sotto l’effetto di un farmaco.
Demo rigorosamente controllata e potrebbe non rappresentare la realtà

E rieccoci. Come un sequel che nessuno ha chiesto ma che tutti sospettavano sarebbe arrivato, Google torna al centro del mirino del Dipartimento di Giustizia USA. Il tema? Sempre lo stesso: abuso di posizione dominante. Cambia solo il contesto, perché se una volta si parlava di motori di ricerca, oggi il campo di battaglia è l’intelligenza artificiale generativa, dove il colosso di Mountain View starebbe già ripetendo lo stesso schema da libro di testo.
Durante l’ultima udienza del processo antitrust in corso, l’accusa è stata chiara: Google sta cercando di replicare nell’AI la stessa architettura monopolistica che ha consolidato nella search. L’avvocato del governo ha infatti puntato il dito contro un nuovo accordo commerciale stretto da Google con Samsung, grazie al quale l’app del chatbot Gemini sarà installata di default su tutti i nuovi dispositivi dell’azienda coreana. Déjà vu? Esattamente. Lo stesso tipo di accordo, con Apple in primis, era stato cruciale per cementare la leadership incontrastata del motore di ricerca di Google, come rilevato nella sentenza dello scorso agosto che lo ha bollato come monopolio illegale.

Google ha recentemente annunciato l’introduzione dei modelli Gemma 3 ottimizzati con Quantization-Aware Training (QAT), una tecnologia che consente l’esecuzione di modelli AI avanzati su GPU consumer come la NVIDIA RTX 3090. Questa innovazione riduce significativamente i requisiti di memoria, mantenendo al contempo un’elevata qualità delle prestazioni.
Con l’ottimizzazione QAT, il modello Gemma 3 27B può ora essere eseguito localmente su una singola GPU desktop, come la NVIDIA RTX 3090 con 24 GB di VRAM. Allo stesso modo, il modello Gemma 3 12B è compatibile con GPU per laptop, come la NVIDIA RTX 4060 Laptop GPU con 8 GB di VRAM, portando capacità AI potenti anche su macchine portatili.
Questi modelli sono disponibili su piattaforme come Hugging Face, dove gli utenti possono accedere a diverse versioni ottimizzate di Gemma 3, tra cui il modello Gemma 3 27B IT QAT in formato int4.
La disponibilità di modelli AI avanzati su hardware consumer rappresenta un passo significativo verso la democratizzazione dell’accesso all’intelligenza artificiale, permettendo a sviluppatori e ricercatori di sperimentare e implementare soluzioni AI senza la necessità di infrastrutture costose.
Per ulteriori dettagli, è possibile consultare l’annuncio ufficiale di Google
La narrazione dell’onnipotente Google che domina il web inizia a sgretolarsi a colpi di sentenze. Un tribunale federale della Virginia ha inferto un colpo chirurgico al cuore dell’impero pubblicitario di Mountain View, stabilendo che la compagnia ha violato la legge antitrust “acquisendo e mantenendo volontariamente un potere monopolistico” nel settore delle tecnologie pubblicitarie. Non si tratta di una semplice multa o di una reprimenda retorica: è l’inizio di una potenziale disgregazione strutturale del modello di business che ha reso Google il gigante che conosciamo oggi.

Quando un colosso come Google inizia a regalare qualcosa, è il momento di preoccuparsi. A partire da oggi, gli studenti universitari negli Stati Uniti possono accedere gratuitamente al piano Google One AI Premium, un servizio normalmente venduto a 20 dollari al mese, fino al 30 giugno 2026. Una mossa che suona tanto come beneficenza digitale, ma che odora pesantemente di colonizzazione dell’ambiente accademico.
Per aderire, basta iscriversi entro il 30 giugno 2025 usando un’email .edu, cioè l’equivalente tecnologico del lascia passare imperiale nel mondo universitario americano. Google, bontà sua, promette anche di avvisare via email prima della scadenza, così gli studenti potranno “cancellare in tempo”. L’intenzione dichiarata? Aiutare gli studenti a “studiare in modo più intelligente”. L’intenzione reale? Intrappolarli nel proprio ecosistema prima che imparino a leggere la concorrenza.

Google si trova nuovamente al centro delle polemiche per la gestione della trasparenza e della sicurezza dei suoi modelli di intelligenza artificiale, in particolare Gemini 2.5 Pro e la nuova variante Flash. Nonostante le promesse di innovazione e affidabilità, l’azienda è stata criticata per la scarsa chiarezza nei report di sicurezza e per le pratiche di valutazione discutibili.
Il report di sicurezza di Gemini 2.5 Pro è stato definito “scarno” da TechCrunch, sollevando dubbi sulla reale affidabilità del modello. La mancanza di dettagli specifici e l’assenza di una documentazione approfondita hanno alimentato le preoccupazioni sulla trasparenza delle pratiche di Google. Inoltre, l’azienda non ha ancora pubblicato un report per il modello Gemini 2.5 Flash, annunciando che sarà disponibile “presto”, ma senza fornire una data precisa.
Quando anche i giganti cambiano idea, di solito c’è un odore nell’aria: quello della competizione che comincia a bruciare sul collo. Google aveva promesso che Gemini Live, la sua feature AI con super-poteri visivi, sarebbe rimasta un’esclusiva per chi sborsava l’abbonamento Gemini Advanced. Ma oggi, con una mossa che sa più di ritirata strategica che di generosità improvvisa, ha deciso di renderla disponibile gratuitamente a tutti gli utenti Android attraverso l’app Gemini.
Google ha deciso che il cinema del futuro non lo faranno più i registi indie né gli studios di Hollywood: lo gireremo tutti noi, un prompt alla volta, con Veo 2, la nuova generazione del suo modello di intelligenza artificiale per la creazione di video realistici e ad alta risoluzione. Per ora, però, solo i Gemini Advanced subscribers possono giocare con questa nuova macchina dei sogni. Sì, sempre che abbiano tempo, fantasia e pazienza da vendere. E soprattutto: sempre che non sforino la quota mensile imposta da mamma Google. Perché l’intelligenza artificiale sarà anche generosa, ma mica gratis.
Da oggi, gli abbonati a Gemini possono scegliere Veo 2 dal menù a tendina nella versione web o mobile e generare clip da otto secondi in formato 720p. Più che cinema, un trailer di TikTok. A proposito: se stai usando l’app su mobile, puoi caricare il tuo capolavoro direttamente su TikTok o YouTube grazie al tasto share. Come dire: se non diventi virale, è colpa tua, non dell’algoritmo.
La notizia è secca, quasi banale: Google sta integrando Photos con Gemini, il suo nuovo assistente AI. Ma attenzione: è solo per “un gruppo selezionato di utenti invitati”.
L’effetto è quello di una festa a cui non sei stato chiamato, ma dalla strada vedi tutto attraverso le finestre.La vera questione non è cosa fa, ma cosa promette di diventare.
L’integrazione, attualmente in rollout graduale su Android e iOS, permette a Gemini di accedere al tuo archivio fotografico e di rispondere a richieste del tipo “mostrami le foto con Mario al lago di Como” oppure “quando ho rinnovato il passaporto?” o ancora “che cavolo ho mangiato a Barcellona l’anno scorso?”.

Nel panorama dell’educazione moderna, dove la digitalizzazione e l’intelligenza artificiale sono ormai una realtà consolidata, Google Classroom fa un passo importante con l’introduzione di uno strumento AI che promette di semplificare e potenziare il processo di creazione dei quiz. L’annuncio, fresco di roll-out, riguarda l’integrazione di Gemini AI, un motore avanzato di intelligenza artificiale che, a partire da file caricati o testo inserito manualmente, è in grado di generare domande di quiz in modo completamente automatico.
Il concetto di base è semplice: gli insegnanti, grazie a Gemini AI, possono creare domande mirate che coprono diverse competenze e conoscenze, risparmiando tempo prezioso. Non si tratta solo di generare domande generiche, ma di personalizzarle in modo che siano in linea con gli obiettivi educativi specifici. L’IA permette anche una selezione precisa delle abilità che si vogliono testare, un aspetto fondamentale per ottenere un feedback dettagliato sul progresso degli studenti.
Gemini Blog: https://workspaceupdates.googleblog.com/2025/04/use-gemini-in-google-classroom-to-generate-questions-from-text.html
Google ha messo in campo una delle sue creazioni più sorprendenti: un modello di intelligenza artificiale, soprannominato DolphinGemma, sviluppato per analizzare e decifrare i suoni dei delfini. La notizia ha suscitato una curiosità generale, aprendo un nuovo capitolo nella comprensione del mondo animale e nel tentativo, ormai quasi ossessivo, di creare ponti tra le forme di comunicazione non umane e la tecnologia. Ma cosa c’è veramente dietro questo progetto?

Mentre il mondo tech continua a rotolare tra bolle di hype e delusioni strutturali, Google sta affinando la sua arte preferita: licenziare senza far troppo rumore. Dopo il teatrale taglio del 2023, quando 12.000 dipendenti furono mandati a casa in un solo colpo (il 6,4% della forza lavoro), oggi Mountain View ha imparato a fare il macellaio con il silenziatore. Niente più fuochi d’artificio, niente più comunicati stampa epocali. Solo tagli chirurgici, distribuiti nel tempo, a colpi di “qualche centinaio di persone” qua e là. Più discreto, meno PR tossica, ma altrettanto letale.
La strategia è semplice, quasi elegante nella sua brutalità. Colpire ogni area con piccole ondate: vendite pubblicitarie, hardware, ingegneria, assistente virtuale, cloud, il reparto X da sempre specializzato in sogni impossibili (e costi altrettanto visionari), e – ultimo ma non meno importante – l’intero comparto Android, Chrome e Pixel. Tradotto: tagli ovunque ci siano muscoli che non portano più valore immediato.

Google ha recentemente introdotto Firebase Studio, un potente ambiente di sviluppo web-based che promette di rivoluzionare il modo in cui vengono create e distribuite applicazioni di intelligenza artificiale full-stack. Integrando in un’unica piattaforma Project IDX, Genkit e Gemini, Firebase Studio fornisce agli sviluppatori un set di strumenti avanzati per progettare, costruire e distribuire applicazioni con un’efficienza senza precedenti. La funzionalità più interessante? Un agente di prototipazione delle app che può generare automaticamente applicazioni complete a partire da semplici prompt o disegni, riducendo drasticamente il tempo di sviluppo.
Leggi l’annuncio ufficiale di Google
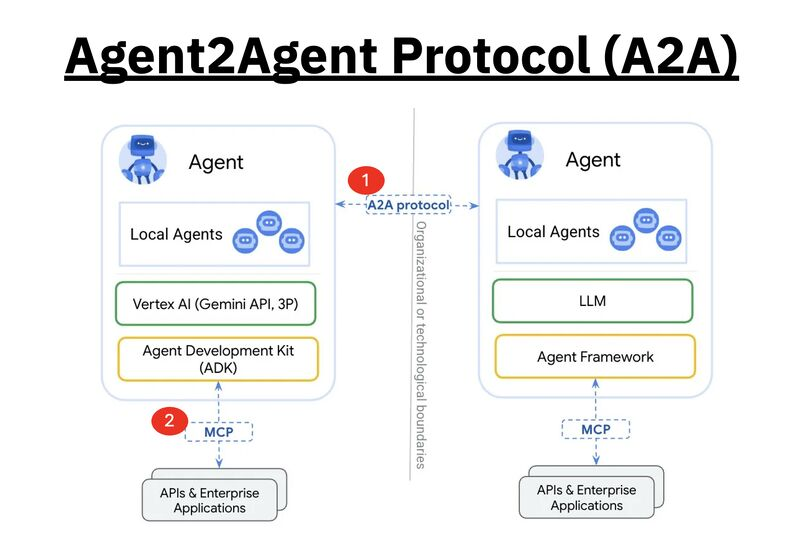
In un mondo dove l’intelligenza artificiale viene ancora gestita come una collezione di agenti autistici — intelligenti sì, ma ognuno chiuso nel proprio silo tecnologico — arriva A2A, l’Agent-to-Agent Protocol di Google, come una telefonata improvvisa nel silenzio assordante. Lanciato ieri con tanto di benedizione open source, A2A potrebbe rappresentare lo strato mancante che rende finalmente operativa, interoperabile e scalabile l’intelligenza artificiale multi-agente. Non è la solita iniziativa “alpha-only” con puzza di lock-in, ma un ecosistema già supportato da oltre 50 partner, da Salesforce a LangChain, fino a SAP. Quando si muovono questi, forse qualcosa di grosso bolle davvero in pentola.
Il protocollo A2A è, in estrema sintesi, una lingua franca tra agenti AI. Un set di regole e convenzioni che permette a software intelligenti di comunicare, coordinarsi, passarsi lavoro e completare task senza dover riscrivere ogni volta la Torre di Babele del middleware. Un agente riceve un compito, lo passa a un altro che ha le competenze per completarlo, e voilà: niente più API spaghetti, nessun vendor lock-in, zero pareti proprietarie. Il sogno bagnato di chiunque abbia passato gli ultimi cinque anni cercando di orchestrare architetture modulari senza impazzire.

Nel panorama già sovraffollato delle intelligenze artificiali che vogliono “aiutarti” a lavorare meglio, Google ha appena rilanciato con una mossa che mescola tecnologia avanzata e un pizzico di follia da Silicon Valley: podcast generati dall’IA dentro Google Docs. Sì, hai capito bene. Ora, se volevi ascoltare due voci robotiche discutere del tuo report trimestrale prima che tu lo mandi al capo, Google ha deciso che ne avevi bisogno, anche se non lo sapevi.
La novità rientra nel pacchetto di aggiornamenti Gemini per le Workspace apps. Un’ondata di funzionalità AI che promette di rivoluzionare – o complicare ulteriormente – il nostro modo di scrivere, analizzare e presentare contenuti. Tutto, ovviamente, sotto il mantra onnipresente: “con Gemini al centro”.

Google ha appena alzato l’asticella dell’illusionismo AI. Con l’ultima evoluzione di Veo 2, il suo modello video generativo, promette che chiunque dallo stagista al regista frustrato potrà produrre contenuti “cinematografici” degni di un trailer Marvel, senza nemmeno sporcare le mani con una telecamera vera. L’update arriva tramite la piattaforma Vertex AI e spalma le novità anche su Imagen 3 per le immagini e su Lyria e Chirp 3 per musica e voce. Ma dietro le luci della ribalta c’è il solito dilemma: chi sta veramente scrivendo questa nuova grammatica visiva e sonora?
Il cuore dell’dell’aggiornamento di Veo 2 pulsa attorno a due concetti presi in prestito da Photoshop ma portati in video: inpainting e outpainting. Il primo cancella elementi indesiderati da una clip — loghi, sfondi fuori luogo, o dettagli che potrebbero ricordarti che la realtà è meno perfetta di un feed Instagram. L’outpainting invece espande il frame, aggiungendo porzioni di video create artificialmente, in modo coerente con la scena. Una specie di Photoshop Motion per video, con la mano invisibile dell’AI che completa lo spazio vuoto come se fosse un assistente di Kubrick.

Reddit, la piattaforma nota per le sue innumerevoli comunità online, ha recentemente annunciato l’integrazione di Google Gemini nel suo strumento di ricerca conversazionale, ‘Reddit Answers’. Questa mossa strategica mira a migliorare la pertinenza e la rapidità delle risposte fornite agli utenti, sfruttando le avanzate capacità di intelligenza artificiale di Google.
Reddit Answers funziona permettendo agli utenti di fare domande tramite un’interfaccia conversazionale alimentata dall’intelligenza artificiale. Grazie a Vertex AI Search, l’IA analizza e sintetizza conversazioni e informazioni pertinenti presenti su Reddit. I risultati forniti includono collegamenti a comunità e post correlati, facilitando l’accesso a contenuti rilevanti.
‘Reddit Answers’, lanciato in beta nel dicembre 2024, consente agli utenti di porre domande e ricevere sintesi curate di commenti e post pertinenti. L’obiettivo è trattenere gli utenti sulla piattaforma, offrendo risposte immediate senza la necessità di ricorrere a motori di ricerca esterni come Google. L’integrazione di Gemini, il modello AI di punta di Google, rappresenta un passo significativo in questa direzione.

Nel panorama tecnologico odierno, l’intelligenza artificiale è la protagonista indiscussa, e Google non perde occasione per ribadire la sua presenza. Il 9 aprile 2025, durante il Google Cloud Next 25, l’azienda ha presentato Ironwood, il suo settimo Tensor Processing Unit (TPU), progettato specificamente per l’inferenza nell’AI.
Ironwood rappresenta un’evoluzione significativa rispetto ai suoi predecessori, integrando funzionalità precedentemente separate e offrendo miglioramenti sostanziali in termini di memoria e efficienza energetica. Secondo Amin Vahdat, vicepresidente di Google, il chip offre il doppio delle prestazioni per watt rispetto al modello Trillium dell’anno scorso.

Nel panorama tecnologico odierno, le alleanze strategiche tra giganti del settore e startup emergenti nel campo dell’intelligenza artificiale (IA) sono diventate pratica comune. Tuttavia, queste mosse non sono passate inosservate agli occhi vigili dei legislatori statunitensi. I senatori democratici Elizabeth Warren e Ron Wyden hanno recentemente sollevato preoccupazioni riguardo alle partnership tra Microsoft e OpenAI, nonché tra Google e Anthropic, temendo che tali accordi possano soffocare la concorrenza e limitare le scelte dei consumatori.
In lettere indirizzate alle due colossali aziende tecnologiche, i senatori hanno richiesto dettagli sui termini finanziari e sulle clausole di esclusività di queste collaborazioni. La loro apprensione principale è che tali alleanze possano consolidare il potere di mercato delle grandi aziende, soffocando l’innovazione e portando a prezzi più elevati per i consumatori. Inoltre, hanno sollevato interrogativi sulla possibilità che Microsoft e Google intendano acquisire i loro partner nell’IA, trasformando queste partnership in vere e proprie fusioni mascherate.
Nel panorama tecnologico odierno, dove l’intelligenza artificiale sembra essere la panacea per ogni problema, Google ha deciso di applicarla anche al mondo dell’arte e della cultura. Recentemente, Google Arts & Culture ha introdotto una funzione sperimentale che utilizza Gemini, il suo modello AI, per creare “episodi audio approfonditi” su artefatti culturali selezionati. In altre parole, ora possiamo ascoltare podcast generati dall’AI che ci raccontano storie su orsi bruni e ceramiche cinesi antiche.
Secondo il blog ufficiale di Google, questa funzione permette di apprendere, ad esempio, che l’orso bruno, tecnicamente un carnivoro, ottiene circa il 90% della sua dieta dalle piante. Oppure, possiamo seguire il viaggio della ceramica cinese antica attraverso l’Eurasia tramite l’audio. Un modo innovativo per trasformare il tempo trascorso nel traffico o sul divano in un’esplorazione culturale. blog.google
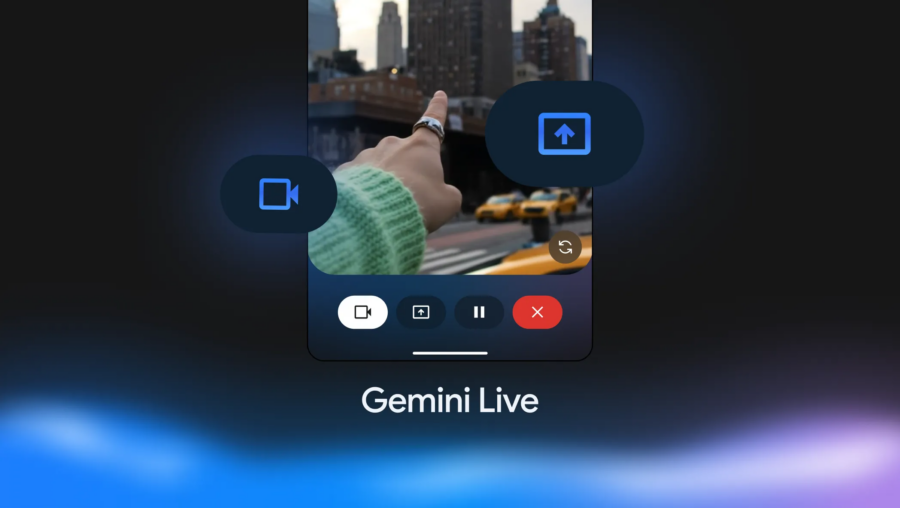
C’è qualcosa di vagamente distopico ma irresistibilmente seducente nell’idea che un’intelligenza artificiale possa guardare quello che stiamo guardando e dirci in tempo reale cosa stiamo vedendo, consigliarci cosa comprare o addirittura dirci se quel pesce nell’acquario è un tetra o un guppy. Non è fantascienza, è il nuovo giocattolo di Google: Gemini Live. E adesso è ufficialmente in rollout, a partire da due flagship che sembrano nati per ospitare un futuro da Black Mirror: il Pixel 9 e il Galaxy S25.
L’annuncio arriva tra le righe, senza fanfare da keynote, ma con la fredda efficienza di un update che cambia le carte in tavola. Gemini Live, l’interfaccia “live” dell’ecosistema Gemini, ora consente non solo di attivare la videocamera e farsi assistere visivamente dall’AI, ma anche di condividere lo schermo del proprio smartphone. E il tutto con una naturalezza che nasconde un’enorme complessità infrastrutturale sotto il cofano. Basta un tap per passare da “scatto la foto al pesce” a “consigliami un nuovo outfit su Zalando”, con la stessa voce pacata e infallibile che ti aiuta a scrivere un’email o sintetizza una riunione su Meet.