
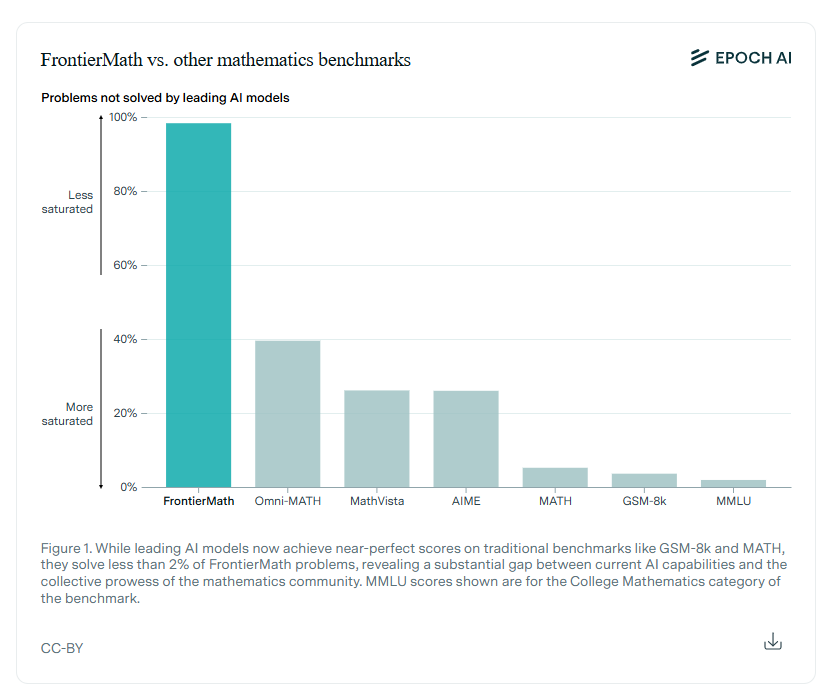
La valutazione delle capacità di ragionamento dell’intelligenza artificiale sta vivendo una svolta decisiva con l’introduzione di FrontierMath, un benchmark composto da centinaia di problemi matematici complessi e originali, ideato per mettere alla prova i sistemi di IA. Realizzato in collaborazione con oltre 60 esperti e matematici di fama mondiale, FrontierMath si presenta come un banco di prova ineguagliabile per testare le abilità logiche e matematiche avanzate degli algoritmi, affrontando campi come la teoria dei numeri, l’analisi reale, l’algebra astratta e la geometria algebrica.
Tag: benchmark
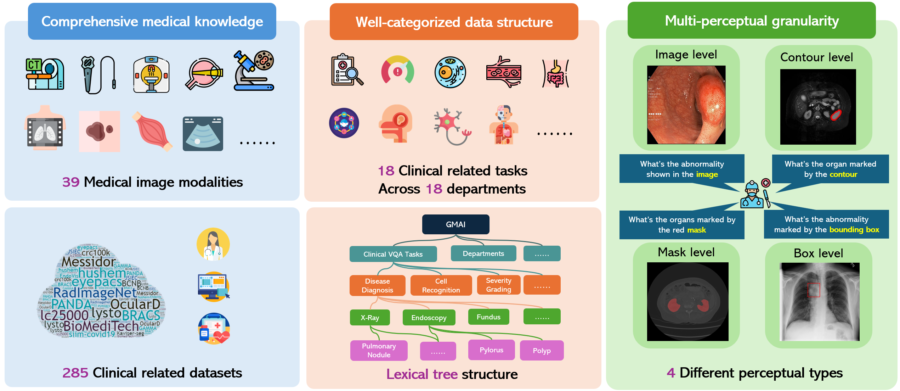
Un benchmark di valutazione multimodale completo verso l’intelligenza artificiale medica generale
GMAI-MMBench rappresenta un importante passo avanti nella valutazione delle intelligenze artificiali mediche generali. Questo benchmark multimodale è stato progettato per affrontare le sfide attuali nella valutazione delle capacità dei modelli di linguaggio visivo (LVLM) nel campo medico, fornendo una struttura di dati ben categorizzata e una granularità percettiva multi-livello.