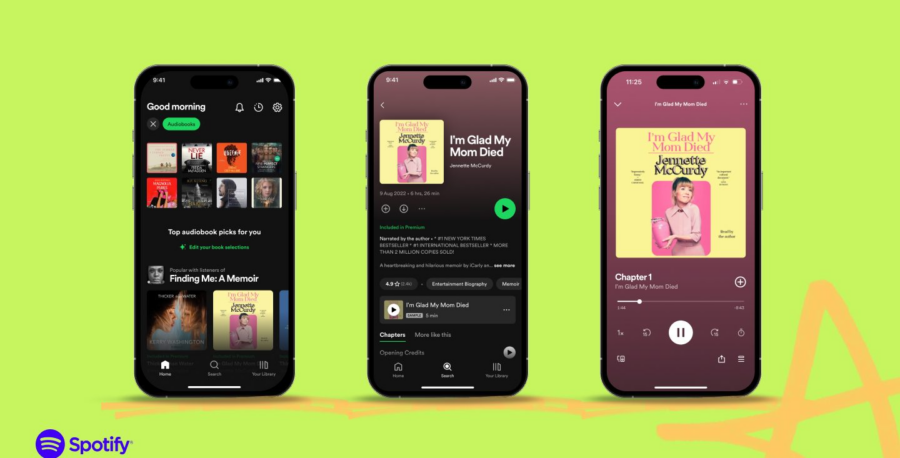
Spotify ha deciso che la voce umana è sopravvalutata e che il futuro dell’ascolto è sintetico. Grazie a una nuova partnership con ElevenLabs, la piattaforma di streaming musicale si appresta a riempire i suoi scaffali digitali di audiolibri narrati dall’intelligenza artificiale. Il tutto, ovviamente, con il nobile scopo di “espandere il mercato degli audiolibri” e “rendere la produzione più accessibile”. Traduzione: più contenuti, meno costi, profitto invariato.
Non che gli audiolibri generati dall’IA fossero assenti da Spotify fino a ieri. La piattaforma già permetteva la distribuzione di titoli sintetici attraverso Findaway Voices, ma solo per pochi “partner selezionati”. ElevenLabs, essendo uno dei nomi più noti nel settore delle voci digitali, spalanca ora le porte a un’invasione di narratori virtuali, senza stanchezza né diritti sindacali.
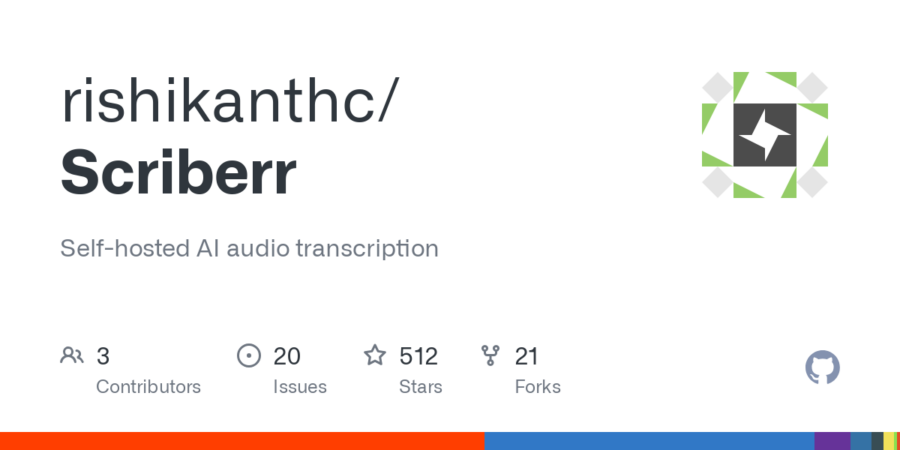
Oggi, i contenuti audio sono più diffusi che mai. Che si tratti di podcast, interviste, riunioni o conferenze, l’audio è diventato uno strumento fondamentale per comunicare informazioni. Tuttavia, la trascrizione di questi file audio in testo può essere un processo lungo e complesso, che richiede spesso l’uso di servizi di terze parti basati su cloud, sollevando preoccupazioni relative alla privacy dei dati.
Immagina di poter trascrivere i tuoi file audio in modo completamente sicuro e senza dover affidare i tuoi dati sensibili a piattaforme esterne. Questo è ciò che Scriberr, un’app di trascrizione audio basata su AI, ti permette di fare, fornendo una soluzione locale che ti garantisce privacy e controllo assoluto sui tuoi contenuti.
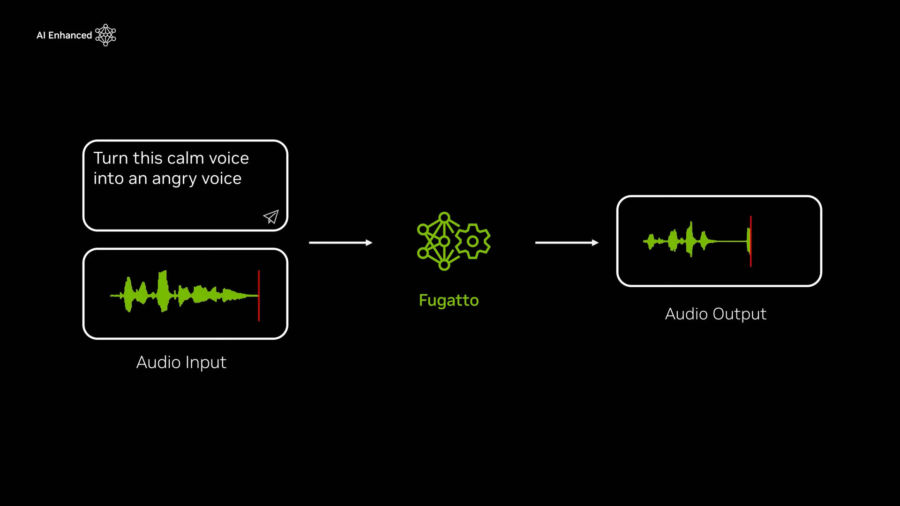
Nvidia ha recentemente presentato Fugatto, un modello di intelligenza artificiale generativa progettato per rivoluzionare la produzione sonora, offrendo strumenti avanzati per musicisti, sviluppatori e creatori di contenuti. Questo innovativo modello consente la generazione di musica, la modifica di voci e la creazione di paesaggi sonori completamente nuovi utilizzando semplici comandi testuali o audio.
Fugatto (Foundational Generative Audio Transformer Opus 1) si distingue per la sua versatilità. È alimentato da un trasformatore generativo con 2,5 miliardi di parametri, supportato da sistemi Nvidia DGX con 32 GPU H100 Tensor Core. Questa tecnologia permette operazioni avanzate, come trasformare voci per simulare accenti, emozioni o toni specifici, e generare effetti sonori unici, come una tromba che “abbaia” o un temporale che evolve in un’alba calma.
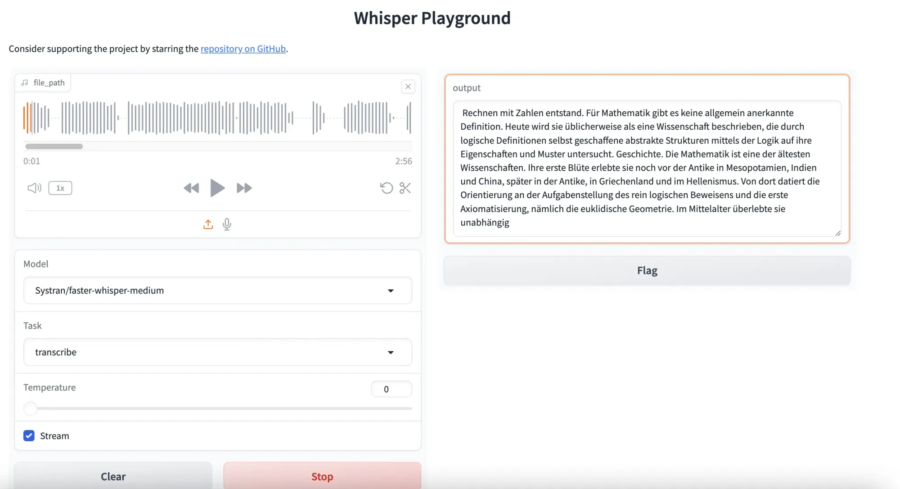
Whisper di OpenAI è ora lo strumento principale per il riconoscimento automatico del parlato e la traduzione. Usando un’architettura Transformer, è stato addestrato su 680.000 ore di dati per funzionare su vari set di dati e domini.
Il team di ingegneri di Baseten ha segnato un’importante innovazione nell’ambito dell’intelligenza artificiale per la trascrizione audio, creando un motore di inferenza che porta Whisper a una velocità senza precedenti. Whisper, uno dei modelli open-source più avanzati sviluppati da OpenAI, è ormai diventato uno standard per chi necessita di una trascrizione automatica accurata, ma Baseten ha introdotto un’incredibile ottimizzazione, raggiungendo nuovi livelli di efficienza.
Open Voice v2 è un modello di sintesi vocale sviluppato da OpenAI, un’azienda di ricerca sull’intelligenza artificiale. Questo modello utilizza l’apprendimento profondo per generare voci sintetiche di alta qualità, simili a quelle umane.
Open Voice v2 è stato addestrato su un vasto dataset di voci umane, il che gli consente di generare voci con diverse tonalità, accenti e lingue.
Il modello è progettato per essere utilizzato in una vasta gamma di applicazioni, tra cui assistenti virtuali, sistemi di navigazione, audiolibri e altro ancora. OpenAI ha rilasciato Open Voice v2 come parte del suo impegno a rendere l’intelligenza artificiale accessibile e vantaggiosa per tutti.
Come spiegato nel articolo e nel sito Web , i vantaggi di OpenVoice sono triplici:
1. Clonazione accurata dei colori dei toni. OpenVoice può clonare accuratamente il colore del tono di riferimento e generare parlato in più lingue e accenti.
2. Controllo flessibile dello stile vocale. OpenVoice consente un controllo granulare sugli stili vocali, come emozione e accento, nonché su altri parametri di stile tra cui ritmo, pause e intonazione.
3. Clonazione vocale multilingue zero-shot. Né la lingua del discorso generato né la lingua del discorso di riferimento devono essere presentate nel set di dati di formazione multilingue per parlanti massivi.
Nell’aprile 2024 e’ stato rilasciato rilasciato OpenVoice V2, che include tutte le funzionalità della V1 e dispone di:
1. Migliore qualità audio. OpenVoice V2 adotta una strategia di formazione diversa che offre una migliore qualità audio.
2. Supporto multilingue nativo. Inglese, spagnolo, francese, cinese, giapponese e coreano sono supportati nativamente in OpenVoice V2.
3. Uso commerciale gratuito. A partire da aprile 2024, sia la V2 che la V1 vengono rilasciate sotto licenza MIT. Gratuito per uso commerciale.
L’intelligenza artificiale sta scuotendo Internet con le sue straordinarie capacità creative, evidenziate dalle immagini generate da piattaforme come Midjourney, Dall-E e Stable Diffusion. Queste rappresentazioni suscitano riflessioni sull’approccio “vedere per credere” per comprendere il potere dell’IA. E una volta accettata questa potenza visiva, non sorprende che l’IA sia altrettanto efficace nel dominio audio.
La musica, fondamentale per l’esperienza cinematografica, può essere generata e completata dall’IA. Registi come Gareth Edwards hanno sperimentato l’IA per comporre colonne sonore, ottenendo risultati sorprendentemente buoni. Sebbene possa non raggiungere l’eccellenza di artisti consolidati come Hans Zimmer, per i creatori emergenti un’IA che produce una colonna sonora decente può fare la differenza tra avere una colonna sonora e non averne affatto.
Come Photoshop ha rivoluzionato la grafica, l’IA offre nuove opportunità anche nella composizione musicale. Tutorial online permettono a chiunque, anche senza esperienza musicale, di creare la propria musica.
L’intelligenza artificiale non è limitata al visivo e all’audio, ma può anche abbattere le barriere linguistiche. Offrendo traduzioni in tempo reale, rende possibile la comprensione reciproca tra persone che parlano lingue diverse, aumentando la connessione umana anche attraverso video, testi e situazioni reali.
Vediamo alcuni esempi di come l’AI viene utilizzata nell’ambito audio:
Riconoscimento automatico del parlato (ASR): Gli algoritmi di ASR utilizzano l’intelligenza artificiale per convertire il parlato umano in testo scritto. Questa tecnologia è utilizzata in assistenti vocali come Siri, Alexa e Google Assistant, nonché in applicazioni di trascrizione automatica per riunioni, interviste e altro ancora.
Sintesi vocale: L’AI può essere utilizzata per generare voci sintetiche realistiche che possono leggere testo scritto ad alta voce. Questa tecnologia è utile per la creazione di audiolibri, assistenti vocali e applicazioni di accessibilità per persone non vedenti o ipovedenti.
Riconoscimento musicale: Alcune applicazioni utilizzano l’AI per riconoscere canzoni in base al suono, consentendo agli utenti di identificare brani musicali in corso di riproduzione.
Trascrizione automatica di brani musicali: Gli algoritmi di trascrizione musicale utilizzano l’AI per convertire brani musicali registrati in partiture musicali o spartiti.
Editing e mastering audio: Alcuni software di editing audio utilizzano l’AI per migliorare la qualità del suono, rimuovere il rumore di fondo, normalizzare il volume e applicare altri effetti audio.
Riconoscimento dell’umore e delle emozioni: L’AI può essere utilizzata per analizzare l’audio e identificare l’umore o le emozioni associate al parlato o alla musica. Questa tecnologia può essere utilizzata per scopi di analisi del feedback dei clienti, di valutazione dell’esperienza dell’utente e di analisi dei sentimenti sui social media.
Generazione di musica e suoni: Alcuni algoritmi di intelligenza artificiale sono in grado di generare musica e suoni originali in base a modelli e stili esistenti. Questa tecnologia è utilizzata in composizione musicale assistita dall’AI e nella produzione di effetti sonori per film, giochi e altri media.
Chiamate telefoniche
AICaller.io – AICaller è una soluzione per chiamate collettive automatizzate e semplice da usare che utilizza la più recente tecnologia di intelligenza artificiale generativa per attivare chiamate telefoniche per te e portare a termine le tue attività. Può eseguire operazioni come la qualificazione dei lead, la raccolta di dati tramite telefonate e molto altro. Viene fornito con una potente API, prezzi bassi e prova gratuita.
Cald.ai – Agenti di chiamata basati sull’intelligenza artificiale per chiamate telefoniche in uscita e in entrata.
podcast.ai – Un podcast interamente generato dall’intelligenza artificiale, basato sull’intelligenza artificiale testo-voce di Play.ht.
VALL-E X – Un modello linguistico codec neurale multilingue per la sintesi vocale multilingue.
TorToiSe – Un sistema di sintesi vocale multi-voce addestrato con un’enfasi sulla qualità. #opensource
Bark : un modello da testo ad audio basato su trasformatore. #opensource
Musica
Loudly: Loudly è un’applicazione mobile che offre un servizio di riconoscimento musicale simile a Shazam. Gli utenti possono utilizzare l’app per identificare canzoni in corso di riproduzione semplicemente avvicinando il loro dispositivo mobile alla fonte del suono. Una volta identificata la canzone, Loudly fornisce informazioni dettagliate sul brano, come il titolo, l’artista, l’album e la possibilità di ascoltarlo direttamente dall’app o di acquistarlo.
Suno: Suno è un’altra applicazione mobile che offre funzionalità simili a Loudly e Shazam. Gli utenti possono utilizzare Suno per identificare canzoni ascoltate in tempo reale o registrate in precedenza. Inoltre, Suno offre anche funzionalità sociali che consentono agli utenti di condividere le loro scoperte musicali con amici e seguaci attraverso la piattaforma.
Harmonai : siamo un’organizzazione guidata dalla comunità che rilascia strumenti audio generativi open source per rendere la produzione musicale più accessibile e divertente per tutti.
Mubert : un ecosistema musicale esente da royalty per creatori di contenuti, marchi e sviluppatori.
MusicLM – Un modello di Google Research per generare musica ad alta fedeltà da descrizioni di testo.
Questo sono solo alcuni esempi, ormai nel mondo si contano piu’ di 2100 applicazioni AI con un tasso di crescita del 30% anno… il famoso Hype.