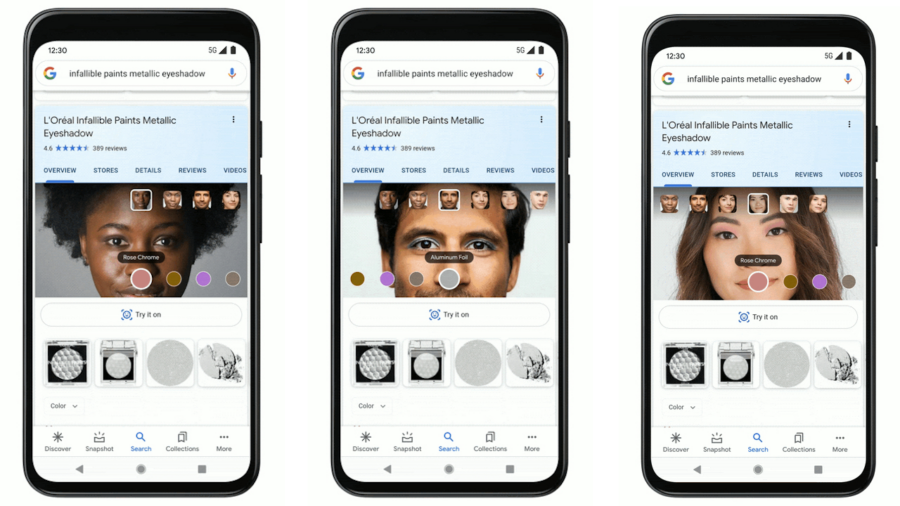
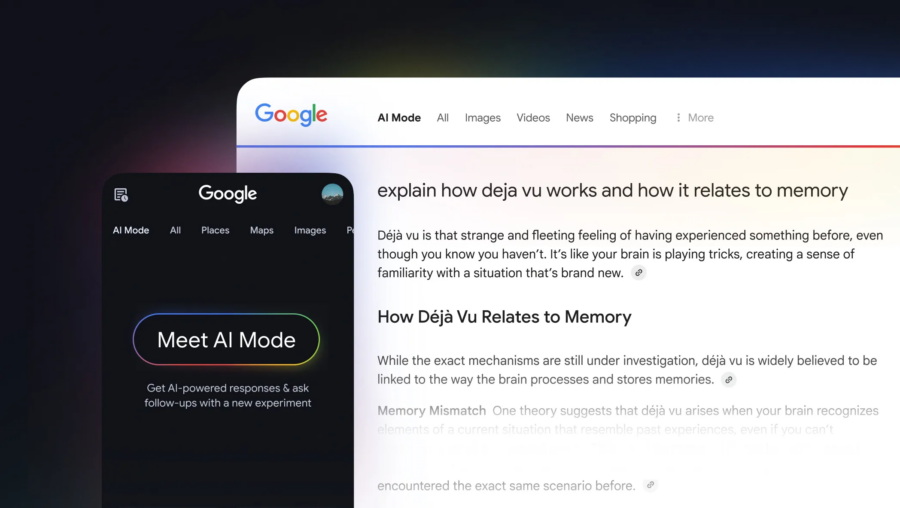
L’evoluzione dell’intelligenza artificiale passa attraverso la capacità di potenziare il ragionamento dei modelli linguistici con tecniche sempre più avanzate.
Il reinforcement learning (RL) sta emergendo come una delle soluzioni più promettenti, capace di superare i limiti del pretraining convenzionale e delle tecniche di fine-tuning. Il nuovo modello QwQ-32B dimostra il potenziale di questa metodologia, offrendo prestazioni di livello paragonabile a modelli ben più grandi come DeepSeek-R1, ma con un numero significativamente inferiore di parametri attivi.