

Midjourney ha lanciato un importante aggiornamento per il suo editor di immagini, migliorando notevolmente l’interfaccia web rispetto all’editor tradizionale su Discord. Questa evoluzione non solo rende la piattaforma più intuitiva, ma indica anche una mossa strategica verso la creazione di un’interfaccia indipendente per la generazione di immagini, in linea con concorrenti come Leonardo e Ideogram.
Categoria: Prompt e Tecnologie Pagina 3 di 5
Regole e indicazioni studiati per sfruttare al meglio i nuovi servizi di GENAI

La Commissione europea ha approvato 5 miliardi di euro di aiuti di Stato tedeschi per sostenere la costruzione e l’attività di un nuovo stabilimento di produzione di microchip da parte della European Semiconductor Manufacturing Company (ESMC) a Dresda, in Germania.
Questo investimento totale dovrebbe superare i 10 miliardi di euro, con iniezioni di capitale, prestiti obbligazionari e aiuti da parte dell’UE e del governo tedesco.
Deep Live Cam è un innovativo strumento di deepfake che consente di trasformare foto statiche in flussi video in diretta, utilizzando il volto di una persona per “animare” un’immagine o un video target.
Questo software open source, distribuito sotto licenza GNU GPLv3, è stato sviluppato per supportare artisti e creativi in vari settori, come l’animazione, il design e la moda, permettendo loro di visualizzare e modificare istantaneamente i loro progetti.
Visita: https://github.com/hacksider/Deep-Live-Cam

Il futuro: un ricercatore di intelligenza artificiale completamente automatizzato che migliora se stesso in modo aperto (LLM²).
Sakana AI, una startup giapponese, ha introdotto un sistema innovativo chiamato The AI Scientist, che afferma di automatizzare l’intero processo di ricerca scientifica. Questo modello di intelligenza artificiale, sviluppato in collaborazione con ricercatori dell’Università di Oxford e dell’Università della Columbia Britannica, è progettato per condurre autonomamente ricerche, dalla generazione di idee alla scrittura e revisione di articoli scientifici.
Anthropic ha recentemente lanciato una nuova funzionalità chiamata prompt caching, disponibile in versione beta pubblica per i modelli Claude 3.5 Sonnet e Claude 3 Haiku.
Questa innovazione consente agli sviluppatori di memorizzare contesti frequentemente utilizzati tra le chiamate API, con l’obiettivo di ridurre i costi fino al 90% e la latenza fino all’85% per i prompt lunghi.
Opera ha lanciato Opera One, il suo browser di punta alimentato dall’IA, per iPhone. Questa versione per iOS offre le stesse caratteristiche estetiche del browser desktop Opera One premiato, insieme a una serie di funzionalità progettate per offrire un’esperienza di navigazione ottimale su iPhone.

Runway ML ha recentemente lanciato Gen-3 Alpha Turbo, una nuova versione del suo innovativo modello di generazione video, che promette prestazioni significativamente superiori rispetto al suo predecessore. Questo aggiornamento, annunciato il 31 luglio 2024, introduce un sistema in grado di generare video fino a sette volte più velocemente rispetto a Gen-3 Alpha, mantenendo al contempo una qualità elevata e realistica.

Google ha recentemente annunciato una significativa riduzione dei prezzi per il suo modello di intelligenza artificiale Gemini 1.5 Flash, con un abbattimento del 70% rispetto ai precedenti modelli. Questa mossa mira a rendere l’IA più accessibile agli sviluppatori, offrendo al contempo funzionalità avanzate e prestazioni elevate.

OpenAI, ha affermato di avere una nuova versione del suo modello linguistico di grandi dimensioni GPT-4o, ma ha fornito pochi dettagli a riguardo.
“C’è un nuovo modello GPT-4o disponibile su ChatGPT dalla scorsa settimana”, “Speriamo che vi stiate divertendo e che lo diate un’occhiata se non l’avete ancora fatto! Noi pensiamo che vi piacerà.”
Secondo VentureBeat , alcuni utenti hanno scoperto che il nuovo modello include un ragionamento in più fasi e spiegazioni più dettagliate dei suoi processi .
Microsoft ha investito miliardi di dollari in OpenAI a gennaio 2023, poco dopo che il chatbot AI generativo ChatGPT aveva conquistato il pubblico. Da allora, OpenAI ha lanciato nuovi modelli, tra cui GPT-4o a maggio. Ha anche rilasciato una versione più piccola e conveniente, GPT-4o mini, il mese scorso.

Recenti ricerche hanno rivelato vulnerabilità allarmanti in Microsoft Copilot AI, evidenziando il suo potenziale di essere utilizzato come una macchina per phishing automatizzata. Questa questione è stata evidenziata dal ricercatore di sicurezza Michael Bargury durante la conferenza Black Hat sulla sicurezza a Las Vegas, dove ha dimostrato diversi proof-of-concept che sfruttano le capacità dell’AI.

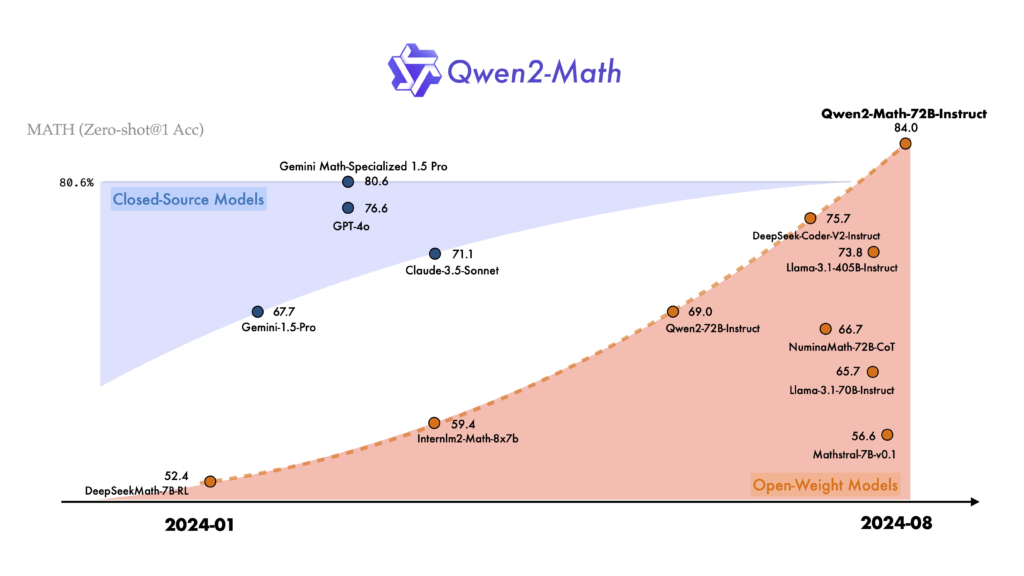
Negli ultimi anni, l’intelligenza artificiale ha fatto passi da gigante, specialmente nel campo dei modelli di linguaggio. Oggi, siamo entusiasti di presentare Qwen2-Math, una nuova serie di modelli linguistici specializzati nella risoluzione di problemi matematici complessi. Questi modelli si basano sulla robusta architettura di Qwen2 e sono progettati per superare le capacità matematiche di modelli precedenti, come GPT-4o.

Raspberry Pi ha recentemente lanciato il Raspberry Pi Pico 2, un microcontrollore avanzato basato sul chip RP2040, progettato per semplificare lo sviluppo di progetti hardware. Questa nuova versione mantiene le caratteristiche fondamentali del modello originale, ma offre miglioramenti significativi in termini di prestazioni e funzionalità.

GPT-2, il modello linguistico di OpenAI, ha suscitato grande interesse per le sue straordinarie capacità di generazione del linguaggio. Recentemente, è stata sviluppata un’interfaccia interattiva che permette di esplorare in tempo reale le previsioni di GPT-2 e la sua mappa dell’attenzione. Questo strumento innovativo offre uno sguardo affascinante sul funzionamento interno di questo modello di intelligenza artificiale.

Mistral AI ha recentemente annunciato importanti aggiornamenti per i suoi modelli di punta, Mistral Large 2 e Codestral, rendendo possibile una personalizzazione completa tramite “La Plateforme“. Questa novità offre agli sviluppatori la possibilità di adattare i modelli alle esigenze specifiche delle loro applicazioni.

Mistral AI ha recentemente introdotto AGENTS, una nuova funzionalità progettata per migliorare l’automazione e la gestione del flusso di lavoro tramite agenti basati sull’intelligenza artificiale.
Questi agenti sono sistemi autonomi che sfruttano modelli linguistici di grandi dimensioni (LLM) per eseguire attività basate su istruzioni di alto livello, consentendo loro di pianificare, utilizzare strumenti e intraprendere azioni per raggiungere obiettivi specifici.
Una volta creati, gli agenti possono essere distribuiti e accessibili tramite un’API o tramite Le Chat, l’interfaccia di chat di Mistral.

JP Morgan Payments, una divisione di JPMorgan Chase, ha annunciato l’espansione della sua collaborazione con PopID per l’avvio di un programma pilota che permetterà agli acquirenti di effettuare pagamenti tramite riconoscimento facciale presso alcuni commercianti negli Stati Uniti.

Con l’aumento della richiesta di intelligenza artificiale più sicura ed efficiente, l’IA decentralizzata (DeAI) diventerà sempre più importante per l’infrastruttura di IA. Tuttavia, per sfruttare al massimo il suo potenziale, un nuovo whitepaper afferma che DeAI dovrà incorporare la tecnologia dei Trusted Execution Environment (TEE).
Huggingface ha presentato una demo di BiRefNet , un modello concesso in licenza dal MIT, per la rimozione gratuita dello sfondo delle immagini.
Provatelo
Ecco una tabella aggiornata con 50 chatbot, ordinati per uso principale. Ogni riga include il nome del chatbot, il link e la categoria di utilizzo.

Google DeepMind ha recentemente annunciato il rilascio di Gemma 2 2B, un modello di linguaggio all’avanguardia che si distingue per la sua leggerezza e capacità di funzionare con soli 1 GB di memoria. Questa nuova aggiunta alla famiglia Gemma è progettata per offrire prestazioni eccezionali in un formato accessibile, rendendo la tecnologia AI avanzata disponibile anche per dispositivi con risorse limitate.

OpenAI ha recentemente annunciato il lancio della modalità vocale avanzata per gli utenti di ChatGPT Plus, una funzionalità attesa che promette di rivoluzionare l’interazione con il chatbot. Questa nuova modalità, attualmente in fase alpha, è stata progettata per offrire conversazioni più naturali e coinvolgenti, avvicinando ulteriormente l’esperienza utente a quella di una conversazione reale.

Hugging Face ha recentemente annunciato un nuovo servizio di Inference-as-a-Service che sfrutta le potenzialità delle microservizi NVIDIA NIM, presentato durante la conferenza SIGGRAPH. Questo servizio offre agli sviluppatori l’accesso immediato a modelli di intelligenza artificiale (AI) di alta qualità, ottimizzati per l’efficienza e la velocità, grazie all’infrastruttura NVIDIA DGX Cloud.

Runway ha recentemente lanciato una nuova funzionalità che consente di generare video a partire da immagini statiche, utilizzando il suo modello Gen-3 Alpha. Questa innovazione, implementata solo poche ore fa, ha suscitato grande entusiasmo tra i creatori di contenuti e gli appassionati di tecnologia.

Meta ha recentemente presentato la seconda generazione del suo modello di segmentazione degli oggetti, il Meta Segment Anything Model 2 (SAM 2) (provate il demo nel link). Questo avanzato modello di intelligenza artificiale rappresenta un significativo passo avanti nella capacità di identificare e isolare gli oggetti all’interno di immagini e video.

La startup Synchron specializzata in impianti cerebrali ha annunciato martedì che l’Apple Vision Pro può essere controllato tramite il pensiero di una persona.

Generare codice sorgente e soluzioni utilizzando l’AI suona eccitante da un lato e terrificante dall’altro, ma non è questo il punto della conversazione.

VidAU è una piattaforma innovativa che semplifica la creazione di video coinvolgenti utilizzando link o descrizioni di prodotti, grazie a avatar realistici che parlano in diverse lingue e accenti.
Con una suite completa di strumenti di editing video, come scambio di volti e traduzione, VidAU sta rapidamente guadagnando popolarità tra aziende e piattaforme di e-commerce, migliorando l’efficienza del content marketing e i tassi di conversione.

Nell’era digitale, l’originalità dei contenuti è diventata un aspetto cruciale per editori, scrittori e creatori di contenuti. Con l’aumento della produzione di contenuti online, garantire che un testo sia autentico e non copiato è fondamentale per mantenere la credibilità e l’integrità. È qui che entra in gioco Originality.ai, una piattaforma innovativa progettata per rilevare il plagio e l’originalità dei contenuti.
Originality.ai è stata fondata da Jon Gillham dopo aver venduto un’agenzia di content marketing che aveva fondato in precedenza. L’azienda si concentra sulla fornitura di strumenti per rilevare il contenuto generato dall’IA e garantire l’integrità del contenuto.

Babylon Health è un’azienda britannica fondata a Londra nel 2013, che offre servizi sanitari di cure primarie attraverso una piattaforma digitale. Questa piattaforma, basata su un’applicazione installata su smartphone, consente agli utenti di accedere a consulenze mediche tramite videochiamate e messaggi di testo, oltre a fornire altre funzionalità come la gestione delle prescrizioni e la prenotazione di visite specialistiche.

Cloudflare, una delle principali aziende di sicurezza internet al mondo, che dichiara di proteggere quasi il 20% del traffico web globale, ha recentemente introdotto una nuova funzionalità rivolta ai proprietari di siti web: un pulsante “easy button” per bloccare i servizi di intelligenza artificiale (IA) dall’accesso ai loro contenuti. Questa iniziativa risponde all’aumento esponenziale della domanda di contenuti utilizzati per l’addestramento dei modelli di IA.

Negli ultimi anni, il campo dell’intelligenza artificiale (IA) ha fatto passi da gigante, rivoluzionando diversi settori e introducendo innovazioni che sembravano fantascienza solo qualche decennio fa. Uno degli sviluppi più affascinanti e controversi è la capacità di ricreare le voci di persone decedute, utilizzando sofisticati algoritmi di IA. La nuova applicazione Reader di ElevenLabs è all’avanguardia in questo settore, permettendo agli utenti di ascoltare celebrità come Burt Reynolds e Judy Garland leggere testi moderni o classici come le opere di Shakespeare.

Grazie all’introduzione delle nuove schede NPU (Neural Processing Unit) di Tenstorrent sul cloud Seeweb, le aziende possono portare il training e l’inferenza di modelli di intelligenza artificiale a un livello superiore.
Queste NPU offrono una potenza di calcolo significativamente maggiore rispetto alle tradizionali GPU, consentendo di accelerare i carichi di lavoro AI in modo più efficiente.
Inoltre, l’adozione di queste soluzioni in cloud permette di ottimizzare i costi e ridurre i consumi energetici, in quanto le risorse vengono erogate in modalità “pay-per-use” senza la necessità di investimenti iniziali in hardware.

I ricercatori di Microsoft hanno scoperto una tecnica di jailbreak chiamata “Skeleton Key” che può superare le protezioni di molti modelli di intelligenza artificiale generativa, permettendo agli hacker di ottenere informazioni sensibili o dannose.

Oggi siamo tutti dei followers e continuiamo a finanziare i grandi players che sono lontani dal nostro paese e dalle nostra Europa. Stiamo vivendo un periodo di innovazione nell’ambito dell’intelligenza artificiale! Ogni giorno sembra esserci una nuova innovazione che spinge oltre i limiti di ciò che le macchine possono fare. Uno dei settori di sviluppo più emozionanti è quello dei modelli linguistici di grandi dimensioni (LLM). Questi modelli stanno assumendo un ruolo centrale, impressionandoci con la loro capacità di generare testi simili a quelli umani e comprendere complessi schemi linguistici.
Quando ho iniziato a esplorare GenAI, ho commesso alcuni errori. L’argomento era immenso e mi sentivo piuttosto intimorito. Tuttavia, scoprire LangChain e i numerosi repository ed esempi open source ha semplificato il percorso (anche se con qualche frustrazione, ad essere sinceri). Ho avuto la fortuna di lavorare con un team straordinario, il che è stato fondamentale per l’esplorazione, l’apprendimento e il ricevimento di feedback.
Affrontare GenAI e LLM potrebbe essere travolgente.
Gestire letteralmente tonnellate di informazioni, framework, guide, video e qualsiasi altro tipo di cosa disponibile GRATUITAMENTE per iniziare con GenAI e LLM potrebbe essere impegnativo.

Dopo una carriera di oltre 22 anni, posso affermare senza ombra di dubbio che lo sviluppo software è un’arte.
Come ogni forma d’arte, richiede impegno, talento e conoscenza. Anche se sembra un lavoro individuale per le abilità tecniche, in realtà dipende dall’interazione e collaborazione del team per ottenere risultati straordinari. Vedere per credere.

Luma AI ha recentemente lanciato Dream Machine, un sistema di generazione di video basato sull’intelligenza artificiale che consente di creare scene realistiche e fantastiche da istruzioni di testo e immagini. Questo strumento, diverso da altri come Sora, è completamente aperto e disponibile per l’utilizzo gratuito da parte di tutti.

Ci sono quei momenti in cui trovi qualcosa di incredibile e dici WOW!
Queste sono state esattamente le mie parole quando ho visto per la prima volta LangChain Tools. Non avrei creduto a ciò che affermava la documentazione senza provarlo personalmente.
