
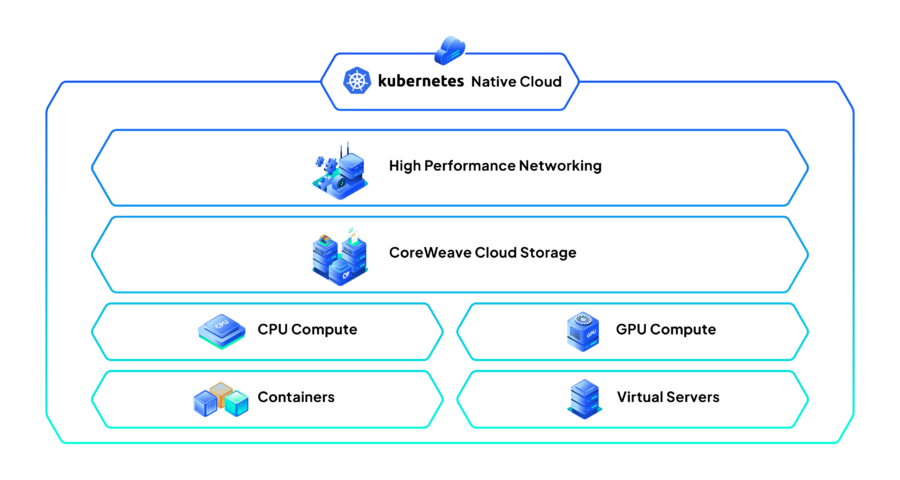
La startup CoreWeave, sostenuta da Nvidia, sta preparando il terreno per un debutto pubblico da record nel 2024, mirando a una valutazione superiore a 35 miliardi di dollari, secondo fonti riportate da Reuters. Con un settore sempre più focalizzato su intelligenza artificiale e cloud computing, questa IPO potrebbe segnare un punto di svolta per il panorama tecnologico.
Categoria: AI Pagina 3 di 14
L’ hub-per-una-copertura-completa-sullintelligenza-artificiale-e-lapprendimento-automatico
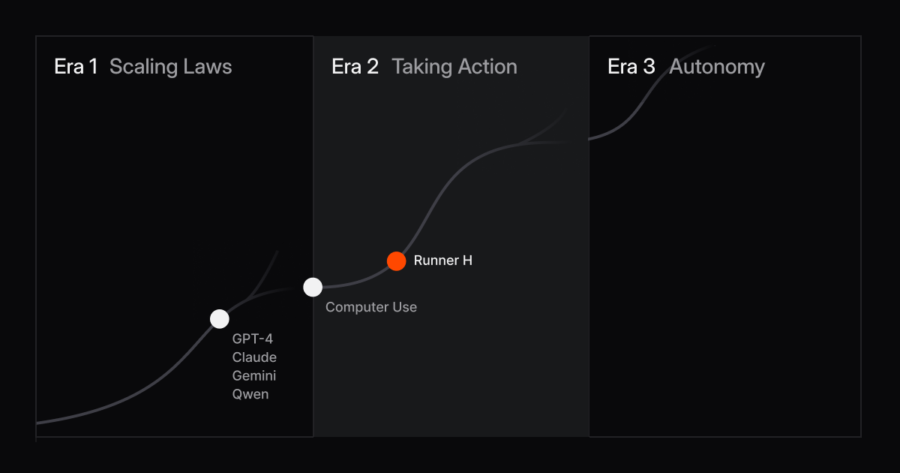
H, la startup parigina fondata da ex Google, ha fatto parlare di sé la scorsa estate con l’annuncio inaspettato di un round di finanziamento da 220 milioni di dollari, prima ancora di lanciare un singolo prodotto. Dopo qualche mese, senza un prodotto concreto, quell’annuncio sembrava destinato a diventare un fallimento catastrofico, quando tre dei cinque cofondatori hanno lasciato l’azienda a causa di “disaccordi operativi e commerciali”. Tuttavia, H non si è fermata e oggi presenta al mondo il suo primo prodotto: Runner H, un’intelligenza artificiale “agentica” progettata per rispondere alle esigenze di aziende e sviluppatori in ambiti come l’automazione dei processi e il controllo qualità.

Le ambizioni di Google nel campo dell’intelligenza artificiale hanno spesso spinto i limiti di ciò che la tecnologia è in grado di fare, e il progetto Orca è un esempio emblematico di questa spinta. Sviluppato come una collaborazione tra DeepMind e YouTube, Orca era uno strumento di intelligenza artificiale progettato per creare musica combinando l’input dell’utente con sofisticati algoritmi. Permetteva agli utenti di creare una canzone nel stile del loro artista preferito, utilizzando pochi semplici comandi: dal genere ai testi, fino alla voce dell’artista stesso. Lo strumento mirava a rivoluzionare il modo in cui viene prodotta la musica, ma ha dovuto affrontare significativi ostacoli legali che ne hanno portato alla sospensione nel 2023.
Il cancro, una delle malattie più devastanti e diffuse a livello globale, continua a rappresentare una sfida imponente per i sistemi sanitari, le comunità scientifiche e le economie mondiali. Secondo recenti proiezioni, si stima che entro il 2050 il numero di casi di cancro diagnosticati annualmente supererà i 35 milioni. Questo drammatico aumento richiede un’azione immediata per rafforzare le capacità di prevenzione, diagnosi precoce, e trattamento, così come per affrontare le implicazioni sociali ed economiche di questa epidemia crescente.
La scienza medica sta compiendo passi significativi per contrastare questa tendenza. Le tecnologie emergenti come la medicina di precisione, l’intelligenza artificiale e le terapie geniche stanno trasformando il panorama oncologico. Le immunoterapie, che potenziano il sistema immunitario per combattere il cancro, hanno già dimostrato risultati promettenti, soprattutto nei tumori difficili da trattare come il melanoma e il carcinoma polmonare.
Entra in scena OneCell Diagnostics, una startup pioniera nel settore della genomica applicata all’oncologia di precisione, con l’obiettivo di aiutare i sopravvissuti al cancro a ridurre le recidive attraverso una tecnologia innovativa basata sulla biopsia cellulare.
Alibaba ha presentato un nuovo modello di intelligenza artificiale chiamato Matrix, progettato per rivoluzionare il settore della creazione di mondi virtuali. Questa tecnologia sfrutta avanzati algoritmi generativi per creare ambienti digitali dinamici in tempo reale, con un frame rate di 16 FPS (fotogrammi per secondo). Questa capacità rappresenta un notevole passo avanti nella generazione di contenuti 3D e si colloca nell’ambito delle applicazioni per il metaverso e realtà virtuale/aumentata, un settore in cui il colosso cinese sta consolidando la sua presenza.
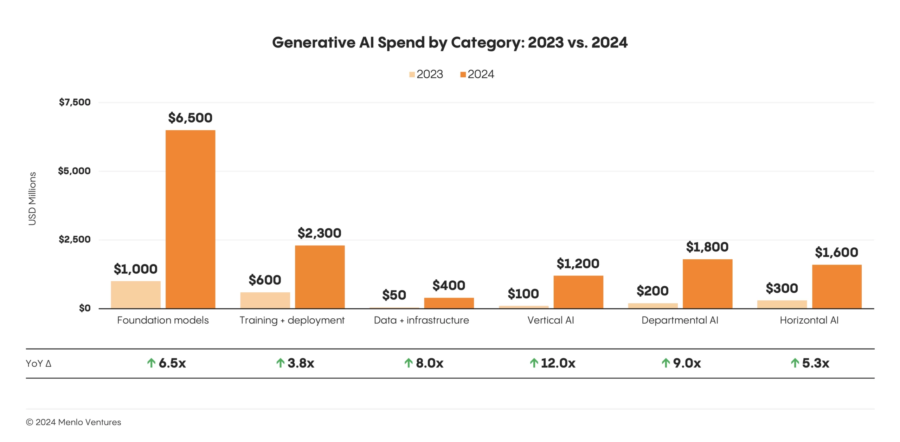
La spesa aziendale per l’intelligenza artificiale generativa ha registrato una crescita vertiginosa del 500% nel 2024, passando da 2,3 miliardi di dollari nel 2023 a ben 13,8 miliardi di dollari, secondo i dati rilasciati da Menlo Ventures mercoledì scorso. Questo significativo aumento, che segna un punto di svolta nell’adozione dell’IA nel settore aziendale, è il risultato di un crescente interesse per le applicazioni avanzate delle tecnologie AI, che stanno rapidamente trasformando i processi aziendali in vari settori.

Il 21 novembre 2024, (bellissimo articolo su Nature) un gruppo di esperti ha sollevato un allarme sui potenziali rischi bio-sanitari legati all’intelligenza artificiale (AI), in particolare riguardo alla capacità della tecnologia di progettare patogeni con nuove proprietà pericolose. In questo scenario, si delineano non solo le opportunità straordinarie per la ricerca biomedica, ma anche i rischi significativi che potrebbero derivare dall’uso non regolamentato di AI nella progettazione e manipolazione di agenti patogeni.

ProRata.ai, una promettente start-up tecnologica, ha recentemente ottenuto una valutazione di 130 milioni di dollari, grazie alla firma di accordi di licenza con importanti editori britannici, tra cui il Guardian e il Daily Mail. Questo segna un passo significativo per l’azienda, che si propone di rivoluzionare il mercato delle licenze e dei diritti per i contenuti digitali.

DeepSeek, una compagnia di ricerca AI finanziata da trader quantitativi, ha presentato una versione preliminare di DeepSeek-R1, un modello che promette di competere direttamente con o1 di OpenAI. Questo modello di ragionamento avanzato mira a superare alcune delle sfide che i modelli AI tradizionali affrontano, come la verifica dei fatti e la gestione di domande complesse, attraverso una metodologia che sembra porre un netto miglioramento rispetto agli approcci tradizionali.
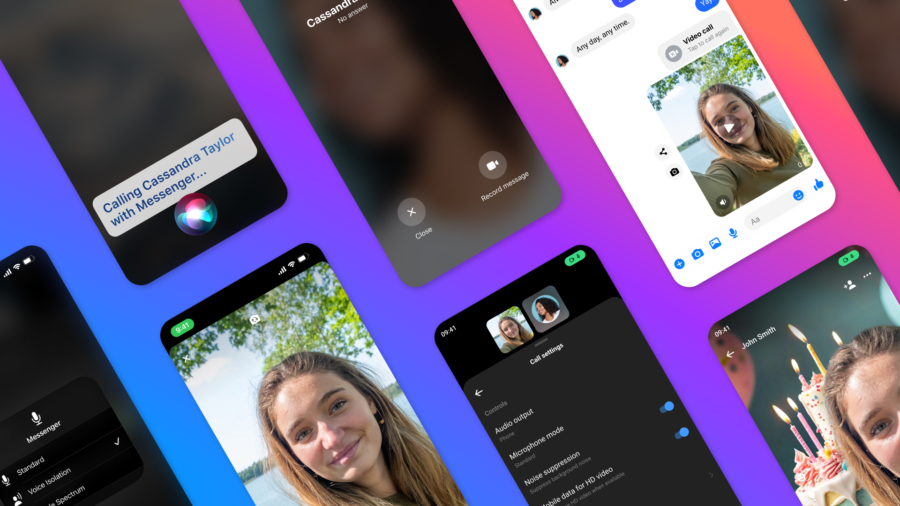
Meta ha introdotto una serie di aggiornamenti significativi all’app Messenger, che puntano a migliorare le chiamate video e audio con nuove funzionalità, come confermato sul blog ufficiale della società. Questi cambiamenti non solo arricchiscono l’esperienza utente, ma portano l’app a competere direttamente con le piattaforme di videocomunicazione più consolidate.

Microsoft ha annunciato un nuovo strumento, Interpreter, disponibile per gli abbonati Microsoft 365, in grado di utilizzare l’intelligenza artificiale per traduzioni vocali in tempo reale, disponibile nel 2025. Questo strumento si distingue per la capacità di replicare fedelmente i messaggi vocali senza alterare il tono o aggiungere interpretazioni superflue. Tuttavia, il debutto di questa tecnologia solleva interrogativi sia sull’impatto positivo che sui rischi associati alla sua implementazione.

Uno studio pubblicato su Nature all’inizio di quest’anno ha sollevato un allarme sul potenziale futuro dell’intelligenza artificiale (AI). I ricercatori hanno avvertito che l’addestramento di modelli AI su dati sintetici, cioè generati da sistemi AI stessi piuttosto che da esseri umani, potrebbe portare a un fenomeno noto come “collasso del modello”. Questo processo ricorsivo, secondo gli autori, porterebbe i modelli a peggiorare progressivamente, poiché vengono continuamente addestrati su dati di qualità sempre più bassa, generati da iterazioni precedenti.

Niantic, il creatore di Pokémon Go e Ingress, sta sviluppando un modello di intelligenza artificiale geospaziale unico nel suo genere. Il progetto sfrutta anni di dati raccolti da milioni di giocatori in tutto il mondo, ponendo le basi per una piattaforma AI capace di comprendere e navigare nel mondo reale con una precisione mai vista prima. Il modello ambisce a offrire un’esperienza immersiva e contestuale, simile alla fluidità con cui ChatGPT genera risposte testuali, ma applicata al mondo fisico.

Microsoft ha stretto un accordo con HarperCollins Publishers per utilizzare una selezione dei suoi libri nella formazione di modelli di intelligenza artificiale (AI). La partnership si concentra principalmente sui contenuti di non-fiction, con l’obiettivo di migliorare le capacità linguistiche e analitiche delle applicazioni AI di Microsoft. Questo accordo rappresenta un ulteriore passo avanti nell’integrazione delle risorse letterarie per sviluppare tecnologie AI più sofisticate, mentre si cerca di bilanciare innovazione e rispetto per i diritti degli autori.
Un gruppo di ricercatori provenienti da varie istituzioni, tra cui l’Università di Lahore e l’Università di Shenzhen, ha creato VirtuDockDL, una piattaforma basata su Python che sta mostrando risultati promettenti nel prevedere quali composti potrebbero diventare farmaci efficaci.
La pipeline VirtuDockDL (github) si presenta come un’innovativa piattaforma progettata per rivoluzionare il processo di screening virtuale nella scoperta di farmaci, sfruttando il potenziale del deep learning per migliorare precisione e velocità. Proposta da Fatima Noor e colleghi, questa soluzione combina tecniche avanzate di apprendimento automatico con metodi computazionali per affrontare le sfide critiche nella selezione di candidati farmacologici promettenti.
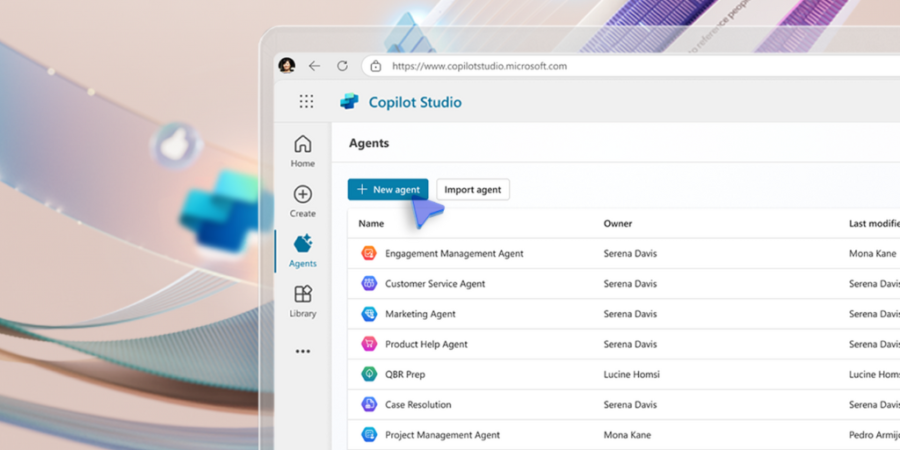
Microsoft ha annunciato un’espansione significativa della sua strategia AI, introducendo nuove funzionalità con Copilot Studio, una piattaforma progettata per creare agenti autonomi in grado di trasformare i processi aziendali. Questa mossa evidenzia la crescente importanza dell’AI nel modernizzare i flussi di lavoro e nel migliorare l’efficienza organizzativa.

Il MIT Jameel Clinic ha annunciato oggi il lancio di Boltz-1, un modello open-source progettato per modellare accuratamente le interazioni biomolecolari complesse. Si tratta del primo modello completamente disponibile commercialmente e open-source in grado di raggiungere la precisione di AlphaFold3 nella previsione delle strutture tridimensionali di complessi biomolecolari. Questo rappresenta un passo significativo nella democratizzazione dell’accesso agli strumenti avanzati di modellazione biomolecolare, stabilendo un nuovo standard nella biologia strutturale open-source.

I creatori della nuova serie TV di fantascienza “Space Nation’ TV Show“ stanno ridefinendo i confini della produzione audiovisiva. Per questa ambiziosa produzione, strettamente legata al gioco basato su Ethereum “Space Nation Online“, è stata sviluppata una soluzione di intelligenza artificiale (AI) su misura, destinata a generare scenari futuristici, astronavi e altri elementi visivi distintivi.
Basato sul popolare MMORPG crittografico che opera sulla rete Ethereum Layer-2 Immutable zkEVM, “Cosmic Frontier Online” è diventato un punto di riferimento per l’integrazione tra tecnologia blockchain e intrattenimento. La serie TV, che funge da prequel del gioco, è guidata da un team di peso: i produttori esecutivi Roland Emmerich noto per pellicole iconiche come “Independence Day“ e “Stargate, e Marco Weber, già celebre per il thriller futuristico “The Thirteenth Floor, Igby Goes Down“.

Kai-Fu Lee, imprenditore visionario e fondatore della startup 01.AI, sta guidando una nuova impresa di intelligenza artificiale con l’obiettivo di entrare nel mercato statunitense, sfruttando un modello linguistico avanzato chiamato Yi-34B. Questa iniziativa nasce con l’intento di competere con i colossi della Silicon Valley e dimostrare che la tecnologia cinese può eccellere su scala globale. Tuttavia, nonostante il successo tecnico, l’impresa si trova ad affrontare il crescente scetticismo degli investitori preoccupati per le tensioni geopolitiche tra Stati Uniti e Cina.

Mistral, una startup francese nel campo dell’intelligenza artificiale generativa, sostenuta da Microsoft, ha svelato importanti aggiornamenti per la sua tecnologia AI, consolidando la sua posizione nel panorama globale dell’innovazione tecnologica. Tra le novità spicca il chatbot Le Chat, ora potenziato con capacità di ricerca sul web e nuove funzioni avanzate di editing e modifica dei contenuti, basate sui modelli proprietari dell’azienda.

Google Workspace ha svelato una nuova funzionalità rivoluzionaria: un generatore di immagini basato su AI, alimentato dalla tecnologia Gemini, integrato direttamente in Google Docs. Questo strumento consente agli utenti di creare rapidamente immagini personalizzate per arricchire i propri documenti, avvicinandosi al concetto di “clip art su misura”, con un approccio che sfida e affianca la funzionalità simile introdotta da Microsoft nei suoi prodotti Office.

Al Global Mobile Broadband Forum (MBBF 2024), Huawei ha presentato le sue innovative soluzioni 5G-AA, che segnano una svolta fondamentale nel panorama delle comunicazioni mobili e nell’evoluzione delle reti 5G. Cao Ming, Vice Presidente di Huawei e Presidente della divisione Wireless Solutions, ha svelato le capacità straordinarie di queste soluzioni, pensate per soddisfare le crescenti esigenze di connessioni sempre più intelligenti e diversificate, alimentate dall’Intelligenza Artificiale Mobile (Mobile AI).

YouTube sta testando una nuova funzionalità che consente ai creatori di remixare brani musicali tramite l’intelligenza artificiale, semplicemente inserendo dei prompt per modificare l’umore o il genere di una canzone. Questa funzione, attualmente in fase di test per un gruppo selezionato di creatori, permette di generare clip musicali di 30 secondi per i Shorts di YouTube, riadattando brani già esistenti. Gli utenti possono scegliere tra una lista di canzoni selezionate e, utilizzando l’opzione “Restyle a track”, possono trasformare brani con nuove caratteristiche sonore, come un cambio di tempo o l’aggiunta di un genere musicale differente.
Anthropic ha recentemente lanciato una suite innovativa di strumenti pensata per automatizzare e perfezionare l’ingegneria dei prompt nella sua console per sviluppatori. Questo aggiornamento è destinato a migliorare l’efficienza nello sviluppo delle applicazioni AI, soprattutto in ambito aziendale, dove l’accuratezza e l’affidabilità dei modelli di linguaggio, come Claude, sono essenziali. Le nuove funzionalità, tra cui il “prompt improver” e la gestione avanzata degli esempi, puntano a semplificare la creazione di applicazioni AI più robuste, ottimizzando la scrittura e la gestione dei prompt.

In un’imprevista mossa che segna una svolta epocale nel campo delle scienze molecolari, Google DeepMind ha rilasciato il codice sorgente e i pesi del modello di AlphaFold 3 per un uso accademico, con l’ambizioso obiettivo di accelerare la scoperta scientifica e lo sviluppo di farmaci. La notizia arriva a solo poche settimane dalla vittoria del Premio Nobel per la Chimica 2024 attribuito ai creatori del sistema, Demis Hassabis e John Jumper, per il loro lavoro pionieristico nella previsione della struttura delle proteine.

Alibaba: Siamo entusiasti di annunciare il rilascio open-source della serie Qwen2.5-Coder, un progetto dedicato a promuovere in modo continuo lo sviluppo dei modelli di linguaggio di codice open-source. Questo rilascio si distingue per la sua potenza, versatilità e praticità, apportando significativi avanzamenti nella programmazione automatizzata e nel supporto agli sviluppatori.
L’ascesa della ricerca aziendale AI
Glean, una promettente startup di intelligenza artificiale, sta scuotendo il panorama tecnologico con il suo innovativo prodotto di ricerca interna. La piattaforma consente ai dipendenti di accedere rapidamente ai dati aziendali, spesso dispersi tra diverse applicazioni cloud, migliorando produttività ed efficienza. Il successo di Glean ha attirato l’attenzione di giganti del settore e stimolato la nascita di soluzioni concorrenti, segnando una svolta nel mercato della ricerca aziendale basata su AI.

Grazie a una rivoluzionaria collaborazione con la Garcia Estate, ElevenLabs ha introdotto un’innovazione straordinaria che unisce nostalgia, tecnologia e accessibilità. L’app ElevenReader consente agli utenti di ascoltare testi – che siano libri, articoli, PDF o persino e-mail – narrati dalla voce digitalmente ricreata di Jerry Garcia, leggendario frontman dei Grateful Dead. Questa novità segna un passo significativo nella fusione tra tecnologia e cultura popolare.
L’app si inserisce nel più ampio progetto “Iconic Voice Project” di ElevenLabs, che mira a preservare e dare nuova vita alle voci di personaggi iconici del passato. Oltre a Garcia, l’app include altre voci leggendarie come James Dean, Judy Garland, John Wayne e Burt Reynolds, portando l’utente a un’esperienza immersiva unica.
Nel panorama tecnologico in continua evoluzione, O2, il colosso britannico delle telecomunicazioni, ha introdotto una soluzione innovativa e inaspettatamente divertente per contrastare le frodi telefoniche. “Daisy”, un’intelligenza artificiale conversazionale progettata per intrappolare i truffatori in conversazioni interminabili, sta rivoluzionando il settore. Questo approccio unico non solo protegge i clienti di O2 da potenziali perdite, ma offre anche uno spettacolo ironico, trasformando le chiamate fraudolente in un vero e proprio teatro dell’assurdo.

Le aziende che sviluppano modelli di intelligenza artificiale (IA) generalmente li addestrano per evitare di dire cose dannose e per non assistere in attività pericolose. L’obiettivo è quello di formare modelli che si comportino in modo “innocuo”, minimizzando i rischi. Tuttavia, quando pensiamo al carattere di persone che troviamo davvero ammirevoli, non ci limitiamo a considerare l’evitamento del danno. Pensiamo anche a quelle persone curiose del mondo, che cercano di dire la verità senza essere scortesi, e che riescono a vedere molteplici sfaccettature di un problema senza diventare eccessivamente sicure di sé o troppo prudenti nelle proprie opinioni. Pensiamo a coloro che sono pazienti ascoltatori, pensatori attenti, conversatori spiritosi e molte altre qualità che associamo a una persona saggia e ben equilibrata.
Anche se i modelli di IA non sono persone, man mano che diventano più capaci, crediamo che sia possibile – e necessario – addestrarli a comportarsi bene in questo senso più ampio. Fare ciò potrebbe anche aiutarli a diventare più discreti quando si tratta di evitare di assistere in attività dannose, e di come decidono di rispondere in alternativa.

Dario Amodei, CEO di Anthropic, ha recentemente sollevato preoccupazioni che il mondo della tecnologia ha iniziato a considerare inevitabili: l’Intelligenza Artificiale Generale (AGI) potrebbe eguagliare, se non addirittura superare, le capacità umane entro pochi anni. Secondo Amodei, già entro il 2027 potremmo trovarci di fronte a sistemi AI di pari o superiore intelligenza, capaci di impatti trasformativi e potenzialmente catastrofici per la nostra società, a seconda di come tali poteri saranno gestiti.
La possibilità di ottenere un’AGI, un tipo di intelligenza capace di comprendere, adattarsi e migliorare il mondo con lo stesso livello di comprensione umana, comporta rischi e responsabilità estremi. Amodei mette in guardia sul fatto che queste intelligenze non risponderebbero agli stessi limiti morali e sociali che governano il comportamento umano, come la paura delle conseguenze legali o sociali. L’intelligenza artificiale, infatti, non ha paura della perdita, del danno personale o dell’ostracismo sociale: agirebbe senza tale “costo sociale,” il che potrebbe creare rischi di distacco tra capacità e morale.

Google ha ufficialmente lanciato l’app Gemini per iOS, aprendo agli utenti iPhone l’accesso completo alla sua potente intelligenza artificiale in un’app autonoma, simile a quanto offerto su Android. Questo debutto rappresenta una svolta strategica: mentre Gemini era già integrato nella Google app, l’app autonoma introduce funzionalità avanzate che arricchiscono l’esperienza degli utenti iOS, in una mossa che mira a competere con le offerte IA di Apple.
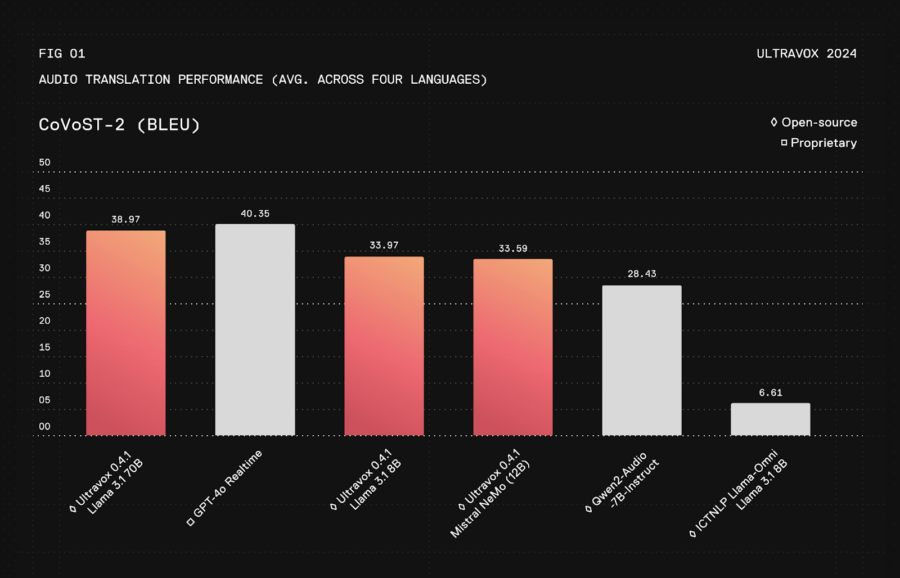
Fixie AI ha introdotto Ultravox v0.4.1, una nuova famiglia di modelli di intelligenza artificiale open source progettata specificamente per potenziare le conversazioni in tempo reale, introducendo una serie di innovazioni che promettono di ridefinire gli standard di interazione con i sistemi di intelligenza artificiale. Questo rilascio rappresenta un avanzamento notevole in termini di velocità, versatilità e accessibilità, posizionandosi come un’alternativa credibile ai modelli proprietari come GPT-4.
Google ha lanciato “Learn About”, (non disponibile se non con VPN…) un nuovo strumento di intelligenza artificiale, differente dai chatbot a cui siamo abituati, come Gemini e ChatGPT. Basato sul modello LearnLM AI, presentato la scorsa primavera, questo strumento rappresenta un’evoluzione unica nel campo dell’istruzione, progettata appositamente per ottimizzare il processo di apprendimento. Google ha sviluppato Learn About per essere “radicato nella ricerca educativa e adattato a come le persone imparano”, un concetto che punta a migliorare l’interazione con le informazioni e a stimolare l’apprendimento autonomo.

Nonostante OpenAI abbia dimostrato in passato progressi significativi nel miglioramento dei propri modelli linguistici, sembra che il modello Orion, sostenuto da Microsoft , stia affrontando sfide inaspettate. Sebbene le capacità di Orion superino quelle di ChatGPT-4 in compiti specifici e risposte a domande, le innovazioni e i miglioramenti apportati appaiono meno rilevanti rispetto al salto qualitativo tra GPT-3 e GPT-4, come riferisce un recente report di The Information. Le fonti anonime citate suggeriscono che la principale sfida risieda nella crescente scarsità di dati di alta qualità per l’addestramento di nuovi modelli linguistici.

Epoch AI ha recentemente pubblicato due articoli che affrontano temi cruciali nell’evoluzione dei modelli di intelligenza artificiale (IA).
Il primo studio esplora il divario nelle prestazioni tra modelli di IA aperti e chiusi, scoprendo che i modelli “open-source” sono in ritardo di circa un anno rispetto ai modelli chiusi. Nonostante la crescente disponibilità di pesi di modelli aperti, che consentono l’adozione e l’adattamento da parte della comunità, questi ultimi non riescono ancora a competere con le prestazioni superiori dei modelli chiusi, come quelli sviluppati da OpenAI e Google. Le differenze non sono solo una questione di accessibilità, ma anche di ottimizzazione computazionale. Ad esempio, pur utilizzando meno potenza di calcolo, i modelli aperti come DeepSeek V2 e Gemma 2 9B non sono riusciti a superare l’efficienza dei modelli chiusi.
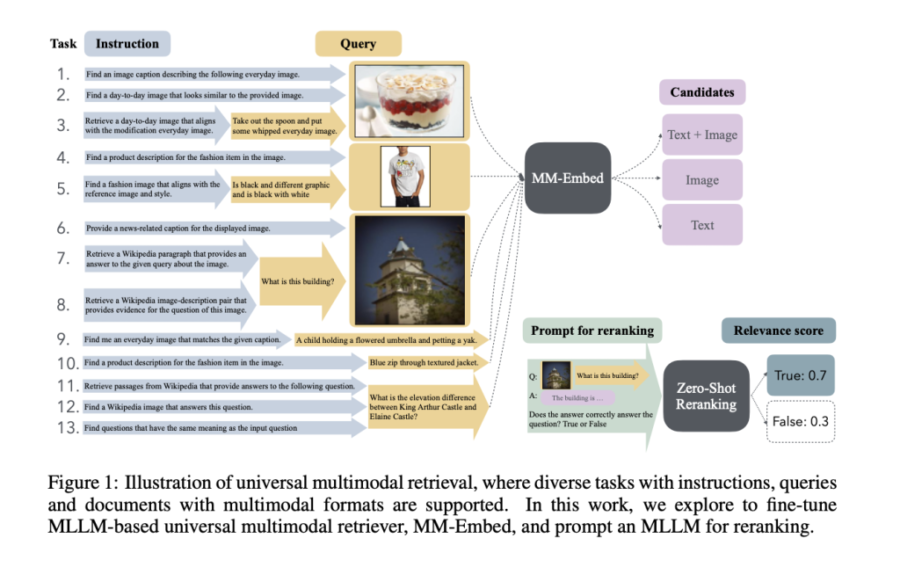
“MM-Embed,” è un modello avanzato per la ricerca multimodale universale, sviluppato da NVIDIA e l’Università di Waterloo. Il modello si concentra su un nuovo approccio di recupero dell’informazione, in grado di gestire simultaneamente più modalità (testo, immagini e combinazioni di entrambi), in un unico sistema integrato per diversi compiti di recupero.
MM-Embed è progettato per comprendere e rispondere a query che combinano testo e immagini. Questa versatilità consente di affrontare compiti complessi, come domande visive e risposte basate su immagini, migliorando l’esperienza utente nella ricerca di informazioni.
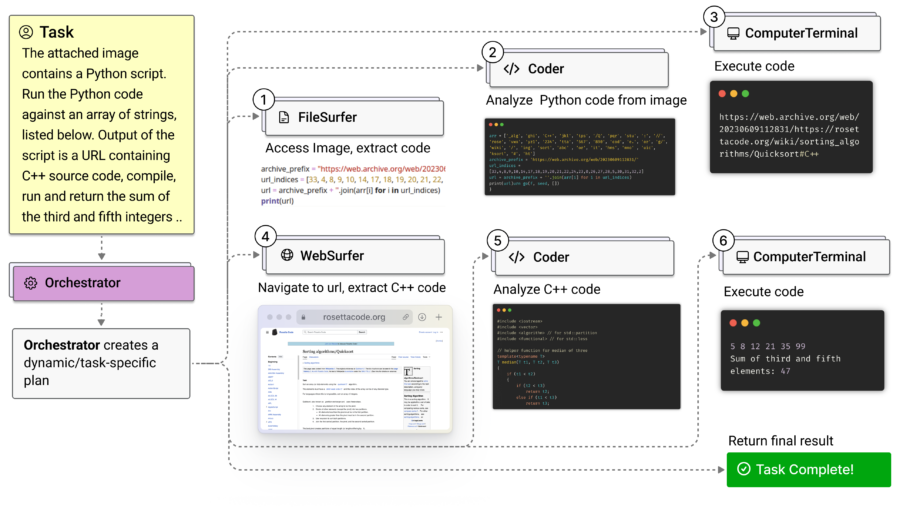
Microsoft Research ha recentemente presentato Magentic-One, un sistema multi-agent generalista progettato per gestire compiti aperti e complessi sia su web che su file, rivoluzionando le possibilità di interazione autonoma e intelligente dei sistemi AI in un’ampia gamma di contesti. Sviluppato su Microsoft AutoGen, una piattaforma open-source per applicazioni multi-agent, Magentic-One segna un avanzamento cruciale verso lo sviluppo di assistenti che possono occuparsi di attività che le persone affrontano quotidianamente sia nel lavoro che nella vita personale.
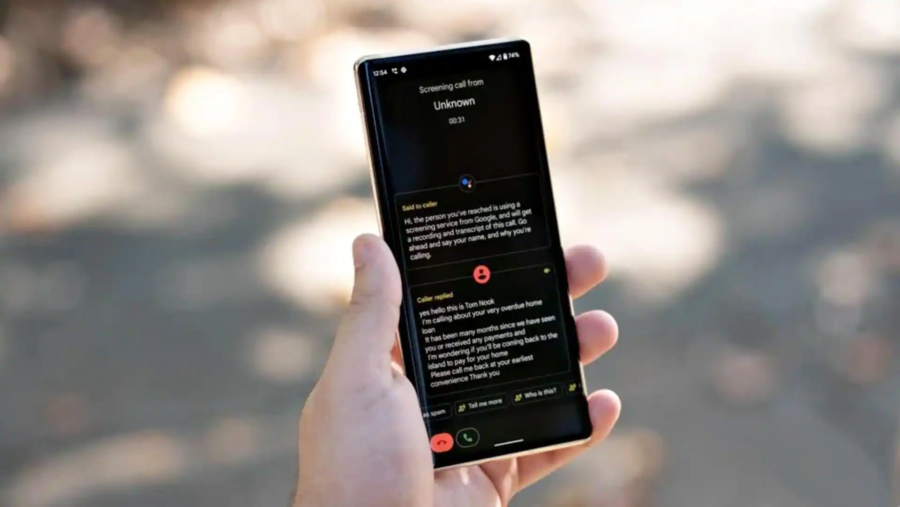
Google sta lavorando per migliorare la sua funzionalità di Call Screen nei telefoni Pixel, introducendo risposte generate dall’intelligenza artificiale. Questo aggiornamento, chiamato AI Replies, mira a fornire risposte più personalizzate e contestuali durante la schermatura delle chiamate.
Secondo le informazioni emerse da un teardown del codice dell’app Phone, Google sta sviluppando una funzione che suggerisce risposte intelligenti basate sulle interazioni reali con i chiamanti. Attualmente, la funzionalità di Call Screen consente all’Assistente Google di rispondere alle chiamate per identificare il chiamante e il motivo della chiamata, utilizzando risposte contestuali standard.

CrowdStrike ha recentemente lanciato un servizio innovativo chiamato AI Red Team Services, progettato per proteggere i sistemi di intelligenza artificiale da minacce emergenti come il manipolamento dei modelli e il data poisoning. Questo servizio si basa sull’esperienza di CrowdStrike nella sicurezza informatica e utilizza tecniche avanzate di emulazione degli avversari per identificare e mitigare le vulnerabilità nei sistemi AI, inclusi i modelli di linguaggio di grandi dimensioni (LLM).