

Mentre la rivoluzione dell’IA avanza, è vitale rivalutare continuamente come questa tecnologia sta plasmando il nostro mondo. A tale scopo, i ricercatori dell’Istituto per l’IA centrata sull’Uomo (HAI) di Stanford pubblicano annualmente un rapporto per tracciare, sintetizzare e visualizzare dati specifici del mondo dell’IA.
Con il rilascio odierno del settimo rapporto annuale sull’Indice dell’IA dell’HAI, i ricercatori di Stanford sperano di fornire ai decisori le conoscenze necessarie per integrare questa tecnologia in modo responsabile ed etico nelle loro attività quotidiane. Il rapporto completo, che si estende per quasi 400 pagine, è ricco di informazioni sullo stato dell’IA.
Di seguito sono riportati alcuni dei punti più importanti emersi dal rapporto completo:
L’Industria Sta Guidando lo Sviluppo dell’IA
Mentre il rapporto menziona che fino al 2014 l’accademia dominava il mondo dei modelli di apprendimento automatico, questo non è più il caso. Nel 2023, il rapporto ha individuato 51 modelli di apprendimento automatico significativi prodotti dall’industria privata.
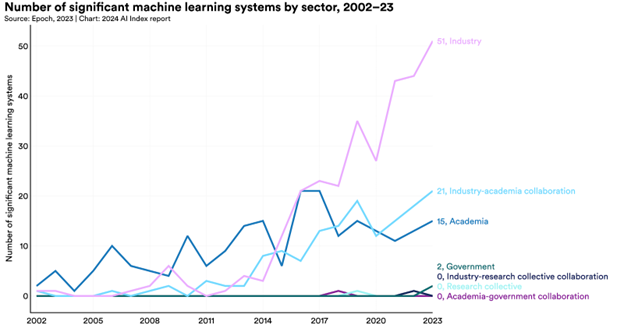
Questo confronto avviene con soli 15 modelli originari dell’accademia e 21 modelli in collaborazioni accademico-industriali. I modelli di proprietà governativa chiudevano il fondo della lista con 2 modelli.
Questo cambiamento sembra essere legato alle risorse necessarie per eseguire questi modelli di apprendimento automatico. Le enormi quantità di dati, potenza di calcolo e denaro necessarie sono semplicemente al di fuori della portata delle istituzioni accademiche. Questo spostamento è stato notato per la prima volta nel rapporto dell’Indice dell’IA dell’anno scorso, anche se il divario tra industria e accademia sembra essersi leggermente ridotto.
Impatti Economici Trasformativi dell’IA
Il rapporto ha individuato un trend interessante riguardante gli investimenti globali in AI. Mentre gli investimenti privati nell’IA nel loro insieme sono quasi raddoppiati tra il 2020 e il 2021, sono leggermente diminuiti da allora. Gli investimenti nel 2023 sono scesi del 7% a $95,99 miliardi rispetto al 2022, che ha visto un calo ancora più significativo rispetto al 2021.
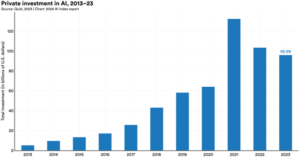
In termini del Ciclo di Hype di Gartner, sembrerebbe che il “Picco delle Aspettative Esagerate” sia avvenuto nel 2021. Se così fosse, il leggero calo nell’attuale “Abisso della Delusione” riflesso negli investimenti globali indicherebbe che il mercato vede ancora un grande valore nell’IA.
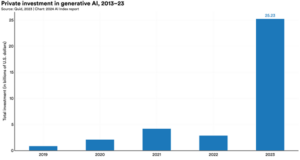
Inoltre, mentre gli investimenti complessivi nell’IA sono leggermente diminuiti, gli investimenti privati nell’IA generativa in particolare sono esplosi. Nel 2023. L’investimento in questa area è aumentato a $25,2 miliardi, che è un aumento di nove volte rispetto al 2022 e quasi 30 volte rispetto al 2019. Infatti, circa un quarto di tutti gli investimenti in AI nel 2023 poteva essere attribuito all’IA generativa in modo specifico.
Inoltre, per integrare la quantità di denaro investito, l’IA sta anche fornendo riduzioni dei costi e aumenti dei ricavi alle organizzazioni che la implementano. Complessivamente, il 42% dei partecipanti ha segnalato diminuzioni dei costi a seguito dell’implementazione dell’IA, mentre il 59% ha segnalato aumenti dei ricavi. Rispetto all’anno precedente, le organizzazioni hanno visto un aumento di 10 punti percentuali per le diminuzioni dei costi e un calo di 3 punti percentuali per gli aumenti dei ricavi.
Analizzando più nel dettaglio, le tre industrie che hanno riportato più frequentemente diminuzioni sono state la manifattura (55%), le operazioni di servizio (54%) e il rischio (44%). Per quanto riguarda i guadagni, le industrie più inclini a segnalare un beneficio sono state la manifattura (66%), il marketing e le vendite (65%) e la strategia e la finanza aziendale (64%).
Mancanza di Valutazioni Standardizzate sull’IA Responsabile
Con l’integrazione sempre più profonda dell’IA nelle operazioni quotidiane della società, c’è un crescente desiderio di vedere responsabilità e affidabilità nella tecnologia. Il rapporto ha specificamente menzionato i benchmark responsabili TruthfulQA, RealToxicityPrompts, ToxiGen, BOLD e BBQ e ne ha monitorato le citazioni anno dopo anno. Anche se le citazioni non riflettono perfettamente l’uso dei benchmark, servono comunque come un indicatore generale dell’attenzione dell’industria su di essi. Ogni benchmark menzionato ha visto più citazioni nel 2023 rispetto al 2022, il che indicherebbe che le organizzazioni stanno prendendo seriamente in considerazione l’IA responsabile.
Detto ciò, l’Indice dell’IA ha anche menzionato che manca un benchmark standardizzato per la segnalazione dell’IA responsabile. Il rapporto menziona che non esiste un insieme universalmente accettato di benchmark sull’IA responsabile. TruthfulQA è utilizzato da tre dei cinque sviluppatori selezionati, mentre RealToxicityPrompts, ToxiGen, BOLD e BBQ sono stati utilizzati solo da uno dei cinque sviluppatori.
È chiaro che l’industria deve stabilire dei benchmark per l’IA responsabile e iniziare a standardizzare il prima possibile.
IA che Accelerare le Scoperte Scientifiche
L’IA ha dimostrato più volte di essere uno strumento estremamente utile nell’ambito della scoperta scientifica. Il rapporto fa menzione di diverse applicazioni di IA legate alla scienza che hanno compiuto grandi progressi nel campo nel 2023:
AlphaDev: Un sistema di IA di Google DeepMind che rende più efficiente la classificazione algoritmica. FlexiCubes: Uno strumento di ottimizzazione della rete 3D che utilizza l’IA per l’ottimizzazione basata sul gradiente e parametri adattabili, migliorando così una vasta gamma di scenari nei videogiochi, nell’immagine medica e oltre. Synbot: Synbot integra la pianificazione dell’IA, il controllo robotico e l’esperimento fisico in un ciclo chiuso, consentendo lo sviluppo autonomo di ricette di sintesi chimica ad alto rendimento. GraphCast: Uno strumento di previsione meteorologica che può fornire previsioni meteorologiche accurate fino a 10 giorni in meno di un minuto. GNoME: Uno strumento di IA che facilita il processo di scoperta dei materiali. Il rapporto ha anche analizzato alcuni degli strumenti di IA più influenti in medicina:
SynthSR: Uno strumento di IA che converte le scansioni cerebrali cliniche in immagini ad alta risoluzione pesate in T-1. Sensori infrarossi plasmonici accoppiati: sensori infrarossi plasmonici accoppiati all’IA che possono rilevare malattie neurodegenerative come il morbo di Parkinson e l’Alzheimer. EVEscape: Questa applicazione di IA è in grado di prevedere l’evoluzione virale per migliorare la preparazione alle pandemie. AlphaMIssence: Consente una migliore classificazione delle mutazioni dell’IA.
Riferimento dell’Umano Pangenoma: Uno strumento di IA per aiutare a mappare il genoma umano. Il rapporto ha inoltre scoperto che l’IA medica altamente competente è qui ed è in uso. I sistemi di IA sono significativamente migliorati negli ultimi anni sul benchmark MedQA, che è un test cruciale per valutare l’esperienza clinica dell’IA. Con un tasso di accuratezza del 90,2%, il modello più notevole del 2023—GPT-4 Medprompt—ha ottenuto un miglioramento di 22,6 punti percentuali rispetto al punteggio più alto del 2022. Le prestazioni dell’intelligenza artificiale (IA) su MedQA sono quasi triplicate dal lancio del benchmark nel 2019.
Inoltre, la FDA sta trovando sempre più utilizzi nello spazio dell’IA. La FDA ha autorizzato 139 dispositivi medici correlati all’IA nel 2022, in aumento del 12,9% rispetto all’anno precedente. La quantità di dispositivi medici correlati all’IA che hanno ricevuto l’approvazione della FDA è più che quadruplicata dal 2012. L’IA viene applicata sempre di più a questioni mediche pratiche.
Educazione e “Brain Drain” del Talento dell’IA Anche se gli strumenti di IA possono rendere molti lavori più facili per i loro controparti umani, gli esseri umani devono comunque svolgere un ruolo nello sviluppo e nell’avanzamento della tecnologia. Pertanto, il rapporto ha dettagliato la forza lavoro umana dietro la rivoluzione dell’IA.
Per cominciare, il numero di laureati americani e canadesi in Informatica (CS) e dottorati continua a crescere, nonostante i nuovi laureati magistrali in CS siano rimasti relativamente stabili. I dati del 2011 hanno mostrato circa lo stesso numero di dottorandi appena laureati in AI che trovavano impiego in accademie (41,6%) e industria (40,9%). Ma entro il 2022, un percentuale molto più alta (70,7%) è entrata nel mondo del lavoro dopo la laurea rispetto a coloro che hanno proseguito gli studi (20,0%). La percentuale di dottorandi in AI che si sono diretti verso l’industria è aumentata di 5,3 punti percentuali nell’ultimo anno da solo, suggerendo un “brain drain” del talento accademico verso l’industria.
Inoltre, i programmi di laurea correlati all’IA sono in aumento a livello globale. Il numero di programmi di laurea post-laurea in inglese sull’IA è triplicato dal 2017, mostrando una crescita costante negli ultimi cinque anni. Ciò dimostra che le università di tutto il mondo vedono i vantaggi nell’offrire programmi di laurea più focalizzati sull’IA.















































Lascia un commento
Devi essere connesso per inviare un commento.