
Negli ultimi anni è nata la necessità di dover garantire che i sistemi basati sull’Intelligenza Artificiale siano in grado di evitare in maniera efficace eventuali comportamenti dannosi o pericolosi, soprattutto quando si parla di sistemi dotati di alta autonomia oppure per quelli impiegati in contesti
critici.
Categoria: AI Pagina 16 di 18
L’ hub-per-una-copertura-completa-sullintelligenza-artificiale-e-lapprendimento-automatico


Secondo quanto riferito dal Wall Street Journal ., la FDA ha dato il via libera a Neuralink di Elon Musk per procedere con l’impianto del suo sistema di chip cerebrale in un secondo paziente.
In un’epoca in cui l’intelligenza artificiale sta rapidamente trasformando il modo in cui interaghiamo con la tecnologia, la Catholic Answers ha introdotto un’iniziativa innovativa: Justin.AI, un modello 3D supportato dall’IA per fornire risposte alle domande sulla fede cattolica.
Lanciato il 25 aprile 2024, Justin.AI ha suscitato un grande interesse nella comunità cattolica e non solo. Molti si sono affrettati a provare questo nuovo strumento, curiosi di vedere come un’intelligenza artificiale potrebbe affrontare questioni di fede complesse e delicate.

Durante la conferenza I/O della scorsa settimana, Google ha presentato una serie di promettenti prodotti di intelligenza artificiale generativa.
Tuttavia, alcuni creatori sono preoccupati che queste nuove funzionalità possano diminuire il traffico web, riducendo le visite organiche e le entrate pubblicitarie.

Google ha presentato martedì la sesta generazione dei suoi chip con unità di elaborazione tensor, notando un significativo miglioramento rispetto alla generazione precedente. I nuovi chip, denominati Trillium, saranno disponibili per i clienti cloud entro la fine dell’anno e offrono un miglioramento delle prestazioni quasi cinque volte (4,7 volte) rispetto al TPU v5e presentato lo scorso agosto.

L’ultimo “modello di punta” di OpenAI, GPT-4o, (o sta per omnimodel) non solo è più veloce di GPT-4, ma migliora anche le sue capacità per voce, testo e immagini, ha rivelato lunedì l’organizzazione no-profit sostenuta da Microsoft. GPT-4o Input $5/1M tokens. Output $15/1M tokens.
Il nuovo modello sarà disponibile gratuitamente per tutti gli utenti. Noi l’abbiamo provato su https://chat.lmsys.org/, in quanto non disponibile per il momento in italia se non con VPN. Questo modello è 2 volte più veloce e il 50% più economico del turbo GPT-4.
“Questa è la prima volta che facciamo un grande passo avanti in termini di facilità d’uso,” durante un live streaming lunedì. “La nostra missione è garantire a tutti i nostri strumenti avanzati di intelligenza artificiale.”
Mita Murati, chief technology officer di OpenAI

IBM ha recentemente scosso il mondo dell’intelligenza artificiale e dello sviluppo software rilasciando otto nuovi modelli di linguaggio di grandi dimensioni (LLM) specializzati nella generazione di codice. Questi modelli, disponibili in modalità base o istruzione, sono addestrati su un vasto set di dati di 116 linguaggi di programmazione e offrono un’ampia gamma di funzionalità, tra cui:

OpenAI, l’organizzazione di ricerca sull’intelligenza artificiale fondata da Elon Musk e Sam Altman, ha recentemente introdotto un nuovo standard chiamato “Model Spec” per documentare in modo chiaro e trasparente i modelli di AI. In un blog post intitolato “Introducing the Model Spec“, OpenAI delinea le motivazioni e i dettagli di questo nuovo framework, che mira a promuovere una maggiore comprensione e responsabilità nello sviluppo e nell’implementazione dei sistemi di AI.

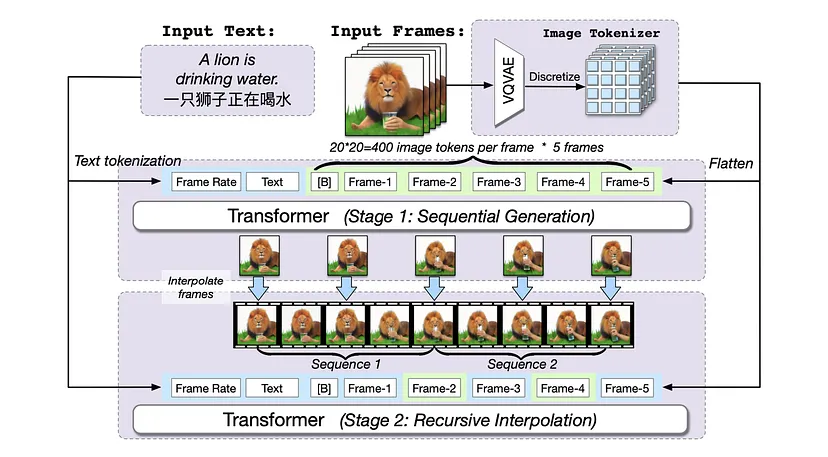
Mentre i recenti generatori di immagini da testo come Google’s Imagen e OpenAI’s DALL-E hanno attirato molta attenzione, i ricercatori della Tsinghua University e della BAAI intendono fare un passo avanti proponendo un generatore di video da testo, chiamato CogVideo, che si dice sia in grado di superare di gran lunga tutti i modelli pubblicamente disponibili nelle valutazioni di macchina e umane. Diamo un’occhiata ad alcune demo qui sotto.

Il prompt engineering, o progettazione dei prompt, ha conquistato il mondo dell’IA generativa. Questo lavoro, consiste nell’ottimizzare l’input testuale per comunicare efficacemente con modelli linguistici di grandi dimensioni.
Il prompt engineering, in un mondo sempre più avvolto dall’ombra dell’intelligenza artificiale, è diventato un ponte cruciale tra l’ingegneria linguistica e l’autonomia creativa delle macchine. Questa disciplina, che si preoccupa di fornire input testuali mirati e ben strutturati alle IA, è stata vista come una chiave per sfruttare al massimo il loro potenziale. Tuttavia, come ogni fenomeno emergente nel vasto universo della tecnologia, il suo ruolo potrebbe subire profonde trasformazioni nel tempo.

Perplexity sta collaborando con SoundHound AI, leader globale nell’intelligenza artificiale vocale.
SoundHound Chat AI si è distinto come il pioniere degli assistenti vocali, essendo il primo a integrare tecnologie di intelligenza artificiale generativa. Inoltre, ha segnato la storia entrando per primo in produzione nell’ambito automobilistico. Grazie alla collaborazione con Stellantis, SoundHound Chat AI è attualmente operativo in oltre 12 paesi e disponibile in 18 lingue diverse.
Neuralink, l’innovativa azienda di neurotecnologia guidata da Elon Musk, ha recentemente divulgato che il proprio sistema di interfaccia cervello-computer (BCI) ha presentato malfunzionamenti alcune settimane dopo l’impianto in Noland Arbaugh, un giovane di 29 anni coinvolto in un grave incidente.
All’inizio dell’anno, nell’ambito dello studio PRIME autorizzato dalla FDA, Arbaugh ha ricevuto il dispositivo sperimentale, progettato per consentire a persone con disturbi neurologici di manovrare dispositivi elettronici mediante il pensiero.
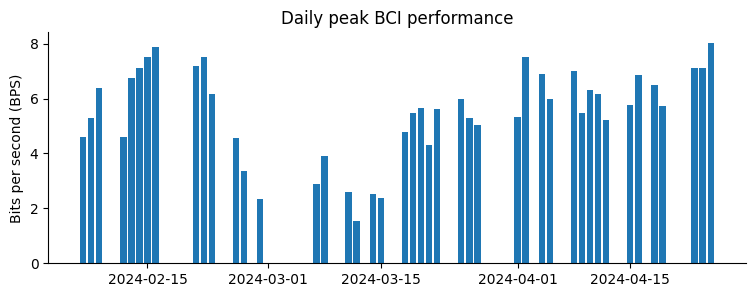
Tuttavia, mercoledì la compagnia ha comunicato che alcuni elettrodi dell’impianto di Arbaugh sono usciti dalla loro posizione originaria poche settimane dopo l’operazione.
Questo problema ha causato un calo nel bit rate per secondo, una metrica fondamentale per valutare la performance della BCI secondo gli standard di Neuralink. La società ha poi adottato misure correttive, incluse ottimizzazioni dell’algoritmo di registrazione, che hanno portato a un netto e costante miglioramento della metrica, ora superiori ai risultati iniziali ottenuti da Arbaugh.
In futuro intendiamo estendere le funzionalità del Link al mondo fisico per consentire il controllo di bracci robotici, sedie a rotelle e altre tecnologie che potrebbero aiutare ad aumentare l’indipendenza delle persone che vivono con la tetraplegia.
Elon Musk, noto per essere alla guida di Tesla e SpaceX, ha espresso il suo entusiasmo per i progressi di Arbaugh lo scorso marzo, in seguito alla pubblicazione sui progressi fatti dal paziente, paralizzato dalla spalle in giù dopo un incidente nel 2016, che ha sperimentato per la prima volta il dispositivo attraverso la piattaforma X.

L’intelligenza artificiale (IA) sta trasformando il posto di lavoro, portando sia opportunità che sfide che richiedono una considerazione attenta. Secondo l’Organizzazione per la cooperazione e lo sviluppo economico (OECD), l’IA può portare benefici significativi sul posto di lavoro, con quattro lavoratori su cinque che dicono che l’IA ha migliorato la loro prestazione al lavoro e tre su cinque che dicono che l’IA ha aumentato il loro piacere del lavoro. Tuttavia, l’adozione dell’IA sul posto di lavoro viene anche accompagnata da rischi che devono essere affrontati.

Elon Musk ci ha presentato una nuova dimostrazione del Tesla bot, mostrando esattamente di cosa è capace il robot. Questa è una sorpresa piuttosto grande, considerando che questa è una delle prime dimostrazioni dal 15 gennaio, quando abbiamo visto il Tesla bot piegare una camicia. In questa dimostrazione è effettivamente piuttosto affascinante, perché possiamo vedere il Tesla bot fare molte cose diverse.

Un recente studio da HAI Stanford Universityha rivelato che i grandi modelli linguistici utilizzati ampiamente per le valutazioni mediche non riescono a supportare adeguatamente le loro affermazioni.


Maxime Labonne, un ricercatore di intelligenza artificiale, ha creato un nuovo modello di linguaggio di grandi dimensioni chiamato Meta-Llama-3-120B-Instruct. Questo modello è stato ottenuto fondendo più istanze del precedente modello Meta-Llama-3-70B-Instruct utilizzando uno strumento chiamato MergeKit.
Il processo di “self-merge”
Questa tecnica innovativa, chiamata “self-merge”, permette di scalare il modello da 70 miliardi a 120 miliardi di parametri. Labonne ha strutturato il processo di fusione sovrapponendo gli intervalli di strati da 0 a 80, migliorando così le capacità complessive del modello.
Ottimizzazione delle prestazioni
Labonne ha impiegato una tecnica di fusione “passthrough”, mantenendo il tipo di dati come float16 per ottimizzare le prestazioni. Questa scelta ha permesso di mantenere l’efficienza del modello nonostante l’aumento significativo della sua dimensione.
Prestazioni del modello
Il modello Meta-Llama-3-120B-Instruct si posiziona al sesto posto nella classifica della benchmark di scrittura creativa, superando il precedente modello Llama 3 70B. Tuttavia, nonostante le sue ottime prestazioni nella scrittura creativa, il modello non riesce a eguagliare le capacità di altri modelli come GPT-4 nelle attività di ragionamento.
Applicazioni
Questo nuovo modello di linguaggio è particolarmente adatto per attività di scrittura creativa. Esso utilizza il template di chat di Llama 3 con una finestra di contesto predefinita di 8K.
Ulteriori informazioni
Maxime Labonne ha dichiarato che il processo di fusione dei modelli ha richiesto un’attenta progettazione per garantire la coerenza e l’efficacia del modello risultante. Inoltre, il Meta-Llama-3-120B-Instruct è stato progettato per essere facilmente adattabile e personalizzabile per diversi compiti di elaborazione del linguaggio naturale.
Il lavoro di Maxime Labonne dimostra come l’innovazione e la sperimentazione possano portare allo sviluppo di nuovi modelli di linguaggio di grandi dimensioni, offrendo nuove opportunità e applicazioni nell’ambito dell’intelligenza artificiale.

L’articolo ‘Imagine Flash: Accelerating Emu Diffusion Models with Backward Distillation‘ discute la ricerca GenAI che supporta le ultime funzionalità di generazione di immagini in Meta AI, oltre al rilascio di Meta Llama 3.
Questa ricerca si concentra sull’accelerazione dei modelli di diffusione Emu attraverso una tecnica chiamata Backward Distillation. La Backward Distillation mira a mitigare le discrepanze tra addestramento e inferenza calibrando il modello studente sulla sua stessa traiettoria inversa. Questo approccio è fondamentale per consentire la generazione di campioni ad alta fedeltà e diversificati utilizzando un numero minimo di passaggi, tipicamente compreso tra uno e tre.
L’articolo introduce anche la Shifted Reconstruction Loss, che adatta dinamicamente il trasferimento di conoscenza in base al passo temporale corrente, e la Noise Correction, una tecnica di inferenza che migliora la qualità del campione affrontando le singolarità nella previsione del rumore.
Attraverso esperimenti approfonditi, lo studio dimostra che il loro metodo supera i concorrenti esistenti sia in metriche quantitative che in valutazioni umane, raggiungendo prestazioni paragonabili al modello insegnante con soli tre passaggi di denoising, facilitando così una generazione efficiente di alta qualità.
Sintesi :
I modelli di diffusione rappresentano un robusto framework generativo, tuttavia implicano un processo inferenziale dispendioso. Le tecniche di accelerazione correnti spesso degradano la qualità delle immagini o risultano inefficaci in scenari complessi, specie quando si limitano a pochi step di elaborazione.
Nel presente studio, META introduce un innovativo framework di distillazione ideato per la produzione di campioni vari e di alta qualità in soli uno a tre step. La metodologia si articola in tre componenti fondamentali: (i) Distillazione inversa, che riduce il divario tra fase di addestramento e inferenza attraverso la calibrazione dello studente sulla propria traiettoria inversa; (ii) Perdita di ricostruzione adattiva, che modula il trasferimento di conoscenza in funzione del tempo di passaggio specifico; e (iii) Correzione adattiva del rumore, una strategia inferenziale che raffina la qualità dei campioni intervenendo sulle anomalie nella previsione del rumore.
Mediante una serie di esperimenti approfonditi, META ha verificato che il metodo eccelle rispetto ai rivali in termini di metriche quantitative e giudizi qualitativi forniti da valutatori umani. In modo significativo, il nostro approccio raggiunge livelli di performance similari al modello originale con soli tre step di denoising, promuovendo una generazione di immagini di alta qualità e ad alta efficienza.

OpenBioLLM-8B è un modello di linguaggio avanzato open source progettato specificamente per il dominio biomedico. Sviluppato da Saama AI Labs, questo modello utilizza tecniche all’avanguardia per raggiungere prestazioni all’avanguardia in una vasta gamma di compiti biomedici.
Specializzazione biomedica: OpenBioLLM-8B è adattato alle esigenze linguistiche e di conoscenza uniche dei campi medici e delle scienze della vita. È stato sottoposto a fine-tuning su un vasto corpus di dati biomedici di alta qualità, consentendogli di comprendere e generare testi con precisione e fluidità specifiche del dominio.
Prestazioni superiori: con 8 miliardi di parametri, OpenBioLLM-8B supera gli altri modelli di linguaggio biomedico open source di scale simili. Ha anche dimostrato risultati migliori rispetto a modelli proprietari e open source più grandi come GPT-3.5 e Meditron-70B nei benchmark biomedici.
Tecniche di formazione avanzate: OpenBioLLM-8B si basa sulle potenti basi dei modelli Meta-Llama-3-8B e Meta-Llama-3-8B. Incorpora il set di dati DPO e la ricetta di fine-tuning, nonché un set di dati di istruzioni mediche personalizzato e diversificato. I componenti chiave del pipeline di formazione includono:
Ottimizzazione delle politiche: Ottimizzazione diretta delle preferenze (DPO) Set di dati di classificazione: berkeley-nest / Nectar Set di dati di fine-tuning: set di dati di istruzioni mediche personalizzato (abbiamo in programma di rilasciare un set di dati di formazione di esempio nel nostro prossimo articolo; resta aggiornato) Questa combinazione di tecniche all’avanguardia consente a OpenBioLLM-8B di allinearsi alle capacità e alle preferenze chiave per le applicazioni biomediche.
La classifica Open Medical LLM mira a tracciare, classificare e valutare le prestazioni dei modelli linguistici di grandi dimensioni (LLM) nelle attività di risposta alle domande mediche. Valuta gli LLM in una vasta gamma di set di dati medici, tra cui MedQA (USMLE), PubMedQA, MedMCQA e sottoinsiemi di MMLU relativi alla medicina e alla biologia. La classifica offre una valutazione completa delle conoscenze mediche e delle capacità di risposta alle domande di ciascun modello
Iscriviti alla nostra newsletter settimanale per non perdere le ultime notizie sull’Intelligenza Artificiale.
[newsletter_form type=”minimal”]

Google afferma che i suoi modelli sanitari AI Med-Gemini battono GPT-4
Google e DeepMind hanno pubblicato lunedì un documento che descrive Med-Gemini, un gruppo di modelli di intelligenza artificiale avanzati destinati ad applicazioni sanitarie.
Il documento descrive Med-Gemini, una famiglia di modelli multimodali altamente capaci specializzati in medicina, basati sulle solide capacità di Gemini in ragionamento multimodale e a lungo contesto.
Med-Gemini è in grado di utilizzare la ricerca sul web in modo fluido e può essere adattato in modo efficiente a nuove modalità utilizzando encoder personalizzati. Il testo riporta i risultati dell’evaluazione di Med-Gemini su 14 benchmark medici, stabilendo nuovi record di performance in 10 di essi e superando la famiglia di modelli GPT-4 in ogni benchmark dove è possibile un confronto diretto, spesso con un ampio margine.
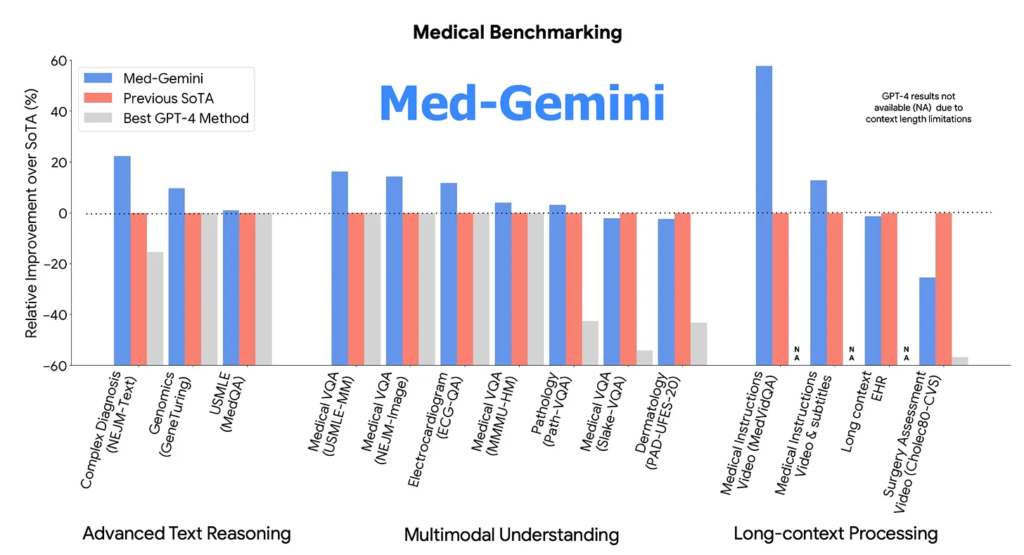
Il miglior modello Med-Gemini ha raggiunto una precisione del 91,1% sul popolare benchmark MedQA (USMLE), utilizzando una strategia di ricerca guidata dall’incertezza. Inoltre, Med-Gemini ha migliorato le prestazioni di GPT-4V su 7 benchmark multimodali, tra cui NEJM Image Challenges e MMMU (salute e medicina), con un margine medio relativo del 44,5%.
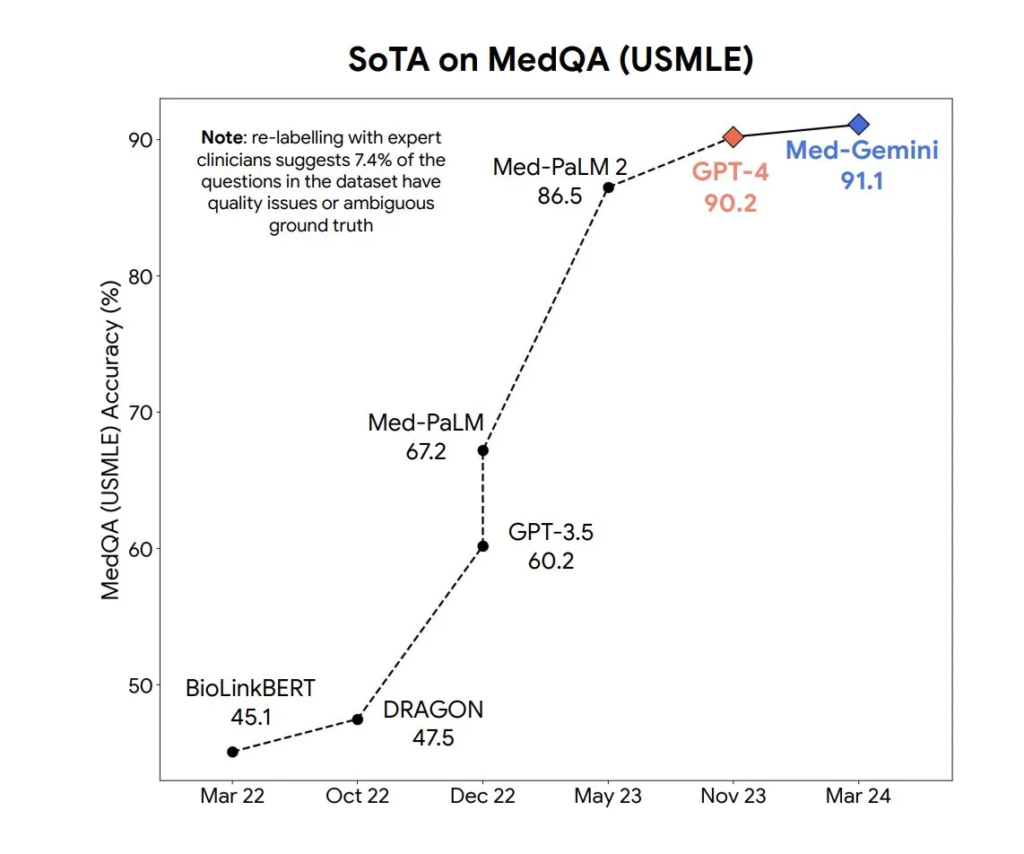
Le capacità di lungo contesto di Med-Gemini sono state dimostrate attraverso prestazioni di ricerca needle-in-a-haystack da lunghe cartelle cliniche de-identificate e question answering su video medici, superando i metodi precedenti che utilizzano solo l’apprendimento in-context.
Med-Gemini ha superato gli esperti umani in compiti come la sintesi di testi medici, dimostrando anche un potenziale promettente per il dialogo medico multimodale, la ricerca e l’educazione. Tuttavia, ulteriori valutazioni rigorose saranno cruciali prima di un’effettiva implementazione nel mondo reale in questo dominio critico per la sicurezza.
Med-Gemini ha fatto un notevole passo avanti nell’abilità di catturare contesto e temporalità, superando una delle maggiori sfide nell’addestramento degli algoritmi medici. A differenza degli attuali modelli di intelligenza artificiale relativa alla salute, Med-Gemini è in grado di comprendere il contesto e il contesto dei sintomi, nonché i tempi e la sequenza della loro insorgenza. Questa capacità è fondamentale per differenziare malattie lievi da quelle potenzialmente pericolose per la vita.
Per raggiungere questo obiettivo, gli sviluppatori di Google hanno adottato un approccio verticale per verticale, creando una “famiglia” di modelli, ciascuno dei quali ottimizza uno specifico dominio o scenario medico. Questo approccio ha portato a una precisione migliore e più sfumata, nonché a un ragionamento più trasparente e interpretabile.
Inoltre, Med-Gemini incorpora un livello aggiuntivo: una ricerca basata sul web di informazioni aggiornate. Questa funzionalità consente l’integrazione dei dati con conoscenze esterne, integrando i risultati online nel modello. Ciò garantisce che Med-Gemini sia sempre allo stesso standard dei medici, che si aspettano di tenersi al passo con le ricerche recenti.
Med-Gemini rappresenta un significativo passo avanti nell’abilità di catturare contesto e temporalità, superando le sfide contestuali nell’addestramento degli algoritmi medici. L’approccio verticale per verticale e l’integrazione di una ricerca basata sul web di informazioni aggiornate hanno portato a una precisione e un ragionamento migliori e più trasparenti.
Iscriviti alla nostra newsletter settimanale per non perdere le ultime notizie sull’Intelligenza Artificiale.
[newsletter_form type=”minimal”]

Oracle ha annunciato giovedì che la sua tecnologia di database per l’intelligenza artificiale, Database23ai, è ora “generalmente disponibile” per gli sviluppatori.
La disponibilità della nuova tecnologia consentirà di trovare chatbot e altri software di intelligenza artificiale in modo più semplice utilizzando AI Vector Search di Oracle.
“Le nuove funzionalità AI Vector Search consentono ai clienti di combinare in modo sicuro la ricerca di documenti, immagini e altri dati non strutturati con la ricerca di dati aziendali privati, senza spostarli o duplicarli”, ha affermato la società in una nota .
Oracle
“Oracle Database 23ai porta gli algoritmi AI dove risiedono i dati, invece di dover spostare i dati dove risiedono gli algoritmi AI. Ciò consente all’IA di funzionare in tempo reale nei database Oracle e migliora notevolmente l’efficacia, l’efficienza e la sicurezza dell’intelligenza artificiale.”
Oracle
Il dirigente di Oracle Juan Loaiza lo ha definito un “punto di svolta” per le imprese, aggiungendo che aumenterà la produttività.
Iscriviti alla nostra newsletter settimanale per non perdere le ultime notizie sull’Intelligenza Artificiale.
[newsletter_form type=”minimal”]

A fine febbraio, Microsoft ha condotto un imponente round di finanziamento di Serie B, raccogliendo 675 milioni di dollari nella Bay Area. Recentemente, il gigante tecnologico ha reso nota la sua collaborazione con Sanctuary AI, celebre per il suo robot umanoide Phoenix.
Questa sinergia punta al cuore dell’interesse di Microsoft: l’intelligenza artificiale generale, ovvero robot capaci di apprendere e ragionare all’umano. Questa evoluzione promette un notevole avanzamento nelle competenze robotiche, tradizionalmente circoscritte a compiti specifici.
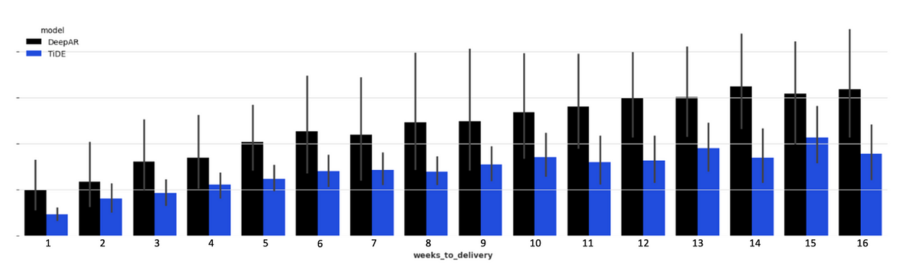
Negli ultimi anni, i modelli di previsione a lungo termine hanno guadagnato sempre più attenzione nel campo dell’intelligenza artificiale (AI) e dell’apprendimento automatico (machine learning). Questi modelli sono cruciali per una vasta gamma di applicazioni, dalle previsioni meteorologiche alle analisi economiche, passando per la gestione delle risorse energetiche e la pianificazione urbana. In questo contesto, TiDE (Time-series Dense Encoder) si è distinto come uno dei più promettenti. Sviluppato dal team di Google Research, TiDE rappresenta un passo in avanti significativo nella capacità di fare previsioni affidabili su orizzonti temporali più lunghi rispetto ai modelli tradizionali.

Nell’affascinante panorama dell’intelligenza artificiale, una nuova categoria di modelli sta emergendo come protagonista: i Modelli di Azione Avanzati (LAMs). Questi sistemi AI rappresentano un cambiamento paradigmatico, in grado di superare i limiti del tradizionale processamento del linguaggio e aprire nuovi orizzonti nell’interazione tra il mondo virtuale e quello fisico.

Amazon ha dichiarato martedì che il suo chatbot di intelligenza artificiale generativa, Q, è ora completamente disponibile per gli sviluppatori.
Le azioni sono aumentate dello 0,4% nelle prime negoziazioni.
“Da quando abbiamo annunciato il servizio al re:Invent, siamo rimasti stupiti dagli incrementi di produttività riscontrati da sviluppatori e utenti aziendali”,
Swami Sivasubramanian
“Le prime indicazioni indicano che Amazon Q potrebbe aiutare i dipendenti dei nostri clienti a diventare più produttivi di oltre l’80% nel loro lavoro; e con le nuove funzionalità che prevediamo di introdurre in futuro, riteniamo che questo trend continuerà a crescere.”
Swami Sivasubramanian
Q è ora in grado di scrivere o correggere codice ed è in grado di fornire suggerimenti su più righe per il codice, ha affermato Amazon. L’azienda ha inoltre presentato Amazon Q Apps che consentirà ai dipendenti di creare app personalizzate basate sull’intelligenza artificiale a partire dai dati della propria azienda, utilizzando istruzioni di testo.
Presentato a novembre , Q è alimentato da modelli linguistici di grandi dimensioni e altri modelli di base, disponibili tramite Amazon Bedrock. È in concorrenza con altri strumenti di codifica AI, come GitHub Copilot di Microsoft.
La tecnologia è alimentata da modelli linguistici di grandi dimensioni e da altri modelli di base, disponibili tramite Amazon Bedrock.
Amazon Q fornisce agli agenti risposte e azioni consigliate basate sulle domande dei clienti in tempo reale per un’assistenza clienti più rapida e accurata, ha affermato la società in una nota.
Amazon alla fine addebiterà agli utenti aziendali $ 20 a persona al mese. Una versione con funzionalità per sviluppatori e operatori IT costerà $ 25 a persona al mese.
A scopo di confronto, sia Microsoft che Google addebitano $ 30 a persona al mese rispettivamente per Copilot per Microsoft 365 e Duet AI per Google Workspace.
Amazon Connect Contact Lens aiuta a identificare le parti essenziali delle conversazioni nei call center con riepiloghi generati dall’intelligenza artificiale che rilevano sentiment, tendenze e conformità alle policy.
Amazon Lex in Amazon Connect consente oggi agli amministratori dei contact center di creare nuovi chatbot e sistemi di risposta vocale interattivi utilizzando istruzioni in linguaggio naturale e di migliorare i sistemi esistenti generando risposte alle domande più frequenti.
Amazon Connect Customer Profiles consente agli agenti di fornire un servizio clienti più rapido e personalizzato e crea profili cliente unificati da diverse applicazioni e database Software-as-a-Service.
Amazon sta espandendo le sue capacità di intelligenza artificiale generativa mentre la corsa per sfruttare la tecnologia si infiamma.
Sfruttare i LLM e altri FM è un’impresa difficile che richiede competenze tecniche che scarseggiano e sono molto richieste, ha affermato Amazon.
“L’integrazione di questi modelli in nuove applicazioni di customer experience che funzionano con la suite esistente di strumenti di contact center di un’organizzazione richiede ulteriori competenze specifiche del settore”, ha affermato Amazon. “Amazon Connect elimina le sfide legate alla creazione e all’implementazione di modelli nei contact center consentendo ai leader aziendali non tecnici di creare un contact center cloud con funzionalità di intelligenza artificiale generativa in pochi minuti.”
AWS ha inoltre annunciato nuove funzionalità per rendere più rapido l’accesso e l’analisi dei dati su più origini dati e funzionalità per aumentare la comprensione da parte dei clienti delle proprie catene di fornitura per contribuire a migliorare l’accuratezza e la pianificazione.
Iscriviti alla nostra newsletter settimanale per non perdere le ultime notizie sull’Intelligenza Artificiale.
[newsletter_form type=”minimal”]
Il Parlamento europeo ha recentemente ratificato la normativa relativa allo Spazio europeo dei dati sanitari (EHDS), segnando un punto di svolta per la sanità digitale nell’Unione Europea. Questa mossa significativa avrà un impatto considerevole sui diritti degli individui rispetto ai loro dati sanitari elettronici e sulle opportunità di riutilizzo di tali dati.
Dopo mesi di duro lavoro e dedizione, abbiamo un accordo che sosterrà fortemente l’assistenza ai pazienti e la ricerca scientifica nell’UE. Il nuovo regolamento concordato oggi consentirà ai pazienti, ovunque si trovino nell’UE, di accedere ai loro dati sanitari, fornendo nel contempo alla ricerca scientifica realizzata per importanti motivi di interesse pubblico una grande quantità di dati sicuri che gioveranno notevolmente all’elaborazione delle politiche sanitarie.
Frank Vandenbroucke, VP ministro e ministro degli Affari sociali e della sanità pubblica del Belgio
L’EHDS permetterà agli individui di accedere ai loro dati sanitari elettronici tramite portali o applicazioni per pazienti. Questo è in sintonia con gli obiettivi del programma politico del Decennio Digitale 2030: il 100% dei cittadini ha accesso ai propri record sanitari elettronici. Inoltre, la normativa assicurerà che i dati sanitari elettronici seguano i pazienti quando cercano cure presso diversi fornitori di assistenza sanitaria nel loro Stato membro o in tutta l’UE.
Mediante il formato europeo di scambio di record sanitari elettronici, la normativa promuoverà un’ulteriore armonizzazione delle strutture dei dati scambiati dai sistemi di record sanitari elettronici. Oltre ai dati strutturati, il formato dovrebbe supportare anche lo scambio di documenti clinici non strutturati, per garantire l’attuazione dei diritti degli individui. I sistemi di record sanitario elettronico saranno certificati per assicurare la loro conformità ai requisiti di interoperabilità e registrazione.
Per garantire un accesso sicuro ai dati sanitari elettronici per scopi di uso secondario, la normativa stabilirà una rete di enti di accesso ai dati sanitari in ogni Stato membro. Questo accelererà la ricerca e l’innovazione nell’UE, contribuendo allo sviluppo di nuovi trattamenti e soluzioni sanitarie avanzate.
Saranno istituite due infrastrutture chiave, MyHealth@EU e HealthData@EU, per supportare l’attuazione dell’EHDS. Nonostante la creazione di queste infrastrutture rappresenti un compito impegnativo, i progressi sono ben avviati. I componenti principali di MyHealth@EU sono già operativi e sono in corso i progetti pilota di HealthData@EU.
La normativa sullo Spazio europeo dei dati sanitari rappresenta un enorme progresso, consentendo un flusso continuo di dati sanitari a beneficio di tutti noi.
L’intelligenza artificiale generativa (GenAI) è un campo affascinante caratterizzato da una vasta e variegata offerta di soluzioni fornite da una molteplicità di attori. Le imprese che si avventurano nell’implementazione della GenAI devono navigare attraverso un complesso ecosistema di fornitori, che comprende produttori di modelli di base, sviluppatori di piattaforme AI, specialisti nella gestione dei dati, fornitori di strumenti per la personalizzazione dei modelli e molti altri.
Ciò che sorprende è che, nonostante il dominio delle grandi aziende di cloud computing nel panorama IT degli ultimi dieci anni, il loro ruolo centrale nel settore della GenAI non è stato così marcato come inizialmente previsto. Almeno finora. Ma ci sono segnali che la situazione potrebbe cambiare. Google ha recentemente tenuto un impressionante evento Cloud Next in cui l’azienda ha presentato un’ampia gamma di funzionalità basate su GenAI.
Siamo ancora in una fase embrionale per quanto riguarda le implementazioni di GenAI, e molte organizzazioni stanno appena cominciando a delineare la propria strategia e il metodo di attuazione. È diventato evidente, tuttavia, che molte aziende stanno riconoscendo l’importanza di avere software e servizi GenAI integrati con le loro fonti di dati primarie.
Considerando l’abbondanza di dati ospitati nel cloud AWS, molte di queste organizzazioni vedranno con favore le nuove funzionalità migliorate offerte da AWS, poiché possono agevolare la creazione e l’ottimizzazione dei modelli GenAI, specialmente con tecnologie come RAG.
Per le aziende che dipendono pesantemente dai servizi di archiviazione dati di AWS per l’addestramento e l’affinamento dei propri modelli GenAI, l’introduzione di queste nuove funzionalità Bedrock potrebbe essere un incentivo significativo per rilanciare i loro progetti applicativi GenAI.
È probabile che assistiamo anche alla crescita delle implementazioni di piattaforme multi-GenAI. Come le imprese hanno imparato che l’adozione di più fornitori di cloud era vantaggiosa dal punto di vista economico, logistico e tecnico, è possibile che si adotti un approccio analogo per sfruttare le diverse piattaforme GenAI per soddisfare le esigenze di diverse tipologie di applicazioni. Sebbene la competizione sia ancora in corso, è evidente che tutti i principali fornitori di cloud computing stanno cercando di affermarsi come player rilevanti anche in questo settore.
La divisione AWS di Amazon sta svelando una serie di nuove funzionalità e miglioramenti per il suo servizio completamente gestito Bedrock GenAI.
Amazon Bedrock è un servizio completamente gestito che offre una scelta di modelli di fondazione (FM) ad alte prestazioni delle principali aziende di IA, come AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI e Amazon, tramite un’unica API, insieme ad un’ampia gamma di funzionalità necessarie per creare applicazioni di IA generativa, utilizzando l’IA in modo sicuro, riservato e responsabile
Nello specifico, Amazon sta aggiungendo la possibilità di importare modelli di fondazione personalizzati nel servizio e quindi consentire alle aziende di sfruttare le capacità di Bedrock attraverso tali modelli personalizzati.
Le aziende che hanno addestrato un modello open source come Llama o Mistral con i propri dati potenzialmente con lo strumento di sviluppo del modello SageMaker di Amazon possono ora integrare quel modello personalizzato insieme ai modelli standardizzati esistenti all’interno di Bedrock.
Come risultato possono utilizzare un’unica API per creare applicazioni che attingono ai loro modelli personalizzati e alle opzioni dei modelli Bedrock esistenti, tra cui le ultime novità di AI21 Labs, Anthropic, Cohere, Meta e Stability AI, nonché i modelli Titan di Amazon.
Amazon ha anche introdotto la versione 2 del suo modello Titan Text Embeddings, che è stato specificamente ottimizzato per le applicazioni RAG.
Uno degli altri vantaggi dell’importazione di modelli personalizzati in Bedrock è la capacità di sfruttare le funzioni RAG integrate del servizio. Ciò consente alle aziende di sfruttare questa nuova tecnologia sempre più popolare per continuare a perfezionare i propri modelli personalizzati con nuovi dati.
La società ha inoltre annunciato la disponibilità generale del suo modello Titan Image Generator.
Poiché è serverless, Bedrock ha funzionalità integrate per scalare senza problemi le prestazioni dei modelli anche tra le istanze AWS, consentendo alle aziende di gestire più facilmente le proprie richieste in tempo reale in base alla situazione.
Le organizzazioni che desiderano creare agenti basati sull’intelligenza artificiale in grado di eseguire attività in più fasi, Bedrock offre anche strumenti che consentono agli sviluppatori di crearli e alle aziende di attingere ai loro modelli personalizzati mentre lo fanno.
Gli agenti sono attualmente uno degli argomenti di discussione più caldi in GenAI, quindi questo tipo di funzionalità è destinato a interessare quelle organizzazioni che vogliono rimanere all’avanguardia. Oltre a queste funzionalità esistenti per Bedrock, Amazon ne ha annunciate altre due, entrambe estensibili ai modelli Bedrock esistenti e anche ai modelli importati personalizzati.
Il Guardrails per Amazon Bedrock aggiunge un ulteriore set di funzionalità di filtro per impedire la creazione e il rilascio di contenuti inappropriati e dannosi, nonché di informazioni personali e/o sensibili.
Praticamente tutti i modelli incorporano già un certo grado di filtraggio dei contenuti, ma i nuovi Guardrail forniscono un ulteriore livello di prevenzione personalizzabile per aiutare le aziende a proteggersi ulteriormente da questo tipo di problemi e garantire che i contenuti generati siano conformi alle linee guida del cliente.
Inoltre, lo strumento di valutazione dei modelli di Amazon all’interno di Bedrock è ora generalmente disponibile. Questo strumento aiuta le organizzazioni a trovare il miglior modello di base per la particolare attività che stanno cercando di realizzare o per l’applicazione che stanno cercando di scrivere.
Il valutatore confronta caratteristiche standard come l’accuratezza e la robustezza delle risposte di diversi modelli. Consente inoltre la personalizzazione di diversi criteri chiave.
Le aziende possono, ad esempio, caricare i propri dati o una serie di suggerimenti personalizzati sul valutatore e quindi generare un report che confronti il comportamento dei diversi modelli in base alle loro esigenze personalizzate.
Amazon offre anche un meccanismo per consentire agli esseri umani di valutare diversi output del modello per misurazioni soggettive come la voce del marchio, lo stile, ecc. Questa valutazione del modello è una capacità importante perché mentre molte aziende potrebbero inizialmente essere attratte da una piattaforma a modello aperto come Bedrock grazie alla gamma delle diverse scelte che offre, quelle stesse scelte possono rapidamente diventare confuse e travolgenti.


I dati sono ovunque e raccontano una storia su tutti. Ma come ogni bella storia, sono necessarie più prospettive per ottenere il quadro generale.
Poiché la polizia fa sempre più affidamento sull’intelligenza artificiale per prevedere e rispondere ai crimini, è fondamentale che queste previsioni non si basino su dati distorti.
Assicuriamoci che questa potente tecnologia veda chiaramente le nostre comunità e le tratti allo stesso modo.
Scopri il nuovo rapporto sui bias negli algoritmi dell’Agenzia europea per i diritti fondamentali.
Questo rapporto esamina l’uso dell’intelligenza artificiale nella polizia predittiva e nel rilevamento del parlato offensivo.
Dimostra come i pregiudizi negli algoritmi appaiono, possono amplificarsi nel tempo e influenzare la vita delle persone, portando potenzialmente alla discriminazione.
Ciò conferma la necessità di valutazioni più complete e approfondite degli algoritmi in termini di bias prima che tali algoritmi vengano utilizzati per processi decisionali che possono avere un impatto sulle persone :
- Intelligenza artificiale e pregiudizi: qual è il problema?
- Circuiti di feedback: come gli algoritmi possono influenzare gli algoritmi
- Pregiudizi etnici e di genere nel rilevamento del linguaggio offensivo
- Guardando al futuro: focalizzare l’attenzione sui diritti fondamentali sull’intelligenza artificiale per mitigare pregiudizi e discriminazioni

Guardate il Video:

Laws of Tech: Commoditize Your Complement
Questo è forse uno dei grafici più importanti sull’Intelligenza Artificiale per il 2024. È stato costruito dallo straordinario team di ricercatori di CathieDWood‘S @ARKInvest. Possiamo vedere che l’ascesa dei modelli locali open source è sulla buona strada per superare i massicci (e costosi) modelli chiusi basati sul cloud.
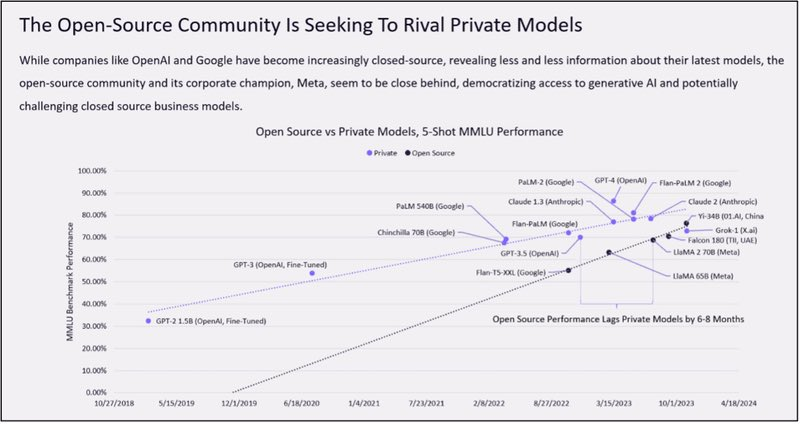
L’ascesa dei modelli locali open source che superano i massicci e costosi modelli chiusi basati sul cloud è affascinante. Questo cambiamento potrebbe democratizzare l’Intelligenza Artificiale e consentire un’innovazione più diffusa, poiché gli attori più piccoli ottengono l’accesso a strumenti potenti senza la necessità di ingenti investimenti
Meta ha compiuto un passo significativo nel mondo dell”i’Intelligenza Artificiale open source con progetti come Llama 3, dimostrando un impegno verso l’innovazione e affrontando le sfide associate a tali iniziative all’avanguardia e su larga scala.
Tuttavia, ci sono notevoli costi legati allo sviluppo di queste tecnologie, specialmente per addestrare modelli linguistici complessi come Llama 3, che richiedono risorse computazionali ed energetiche considerevoli.
Perché Meta si sta avventurando nell’Intelligenza Artificiale open source?
Una ragione chiave potrebbe essere la strategia di “mercificare il proprio complemento”.
Questo concetto, identificato da Joel Spolsky, implica rendere i prodotti e i servizi complementari al proprio core business economici e ampiamente disponibili, al fine di aumentare la domanda per il prodotto principale e catturarne il valore. Storicamente, questa strategia ha funzionato bene nel settore tecnologico, come dimostrato da casi come IBM con il PC originale e Microsoft con MS-DOS.
Meta si è impegnata in questa strategia anche attraverso l’Intelligenza Artificiale generativa, che consente agli utenti di creare rapidamente nuovi contenuti, dall’immagine al testo ai video.
Facendo sì che la creazione di contenuti sia economica e diffusa, Meta può aumentare l’coinvolgimento degli utenti sulle proprie piattaforme, generando così maggiori entrate pubblicitarie.
Il rilascio di tecnologie AI come open source attira i migliori talenti nel campo, promuove l’innovazione e migliora i prodotti di Meta.
Questa strategia è sostenuta dall’idea che l’accesso alla tecnologia AI di base non comprometta il core business di Meta nel social networking e nella pubblicità digitale.
I modelli di Intelligenza Artificiale aperti ampliano l’universo dei contenuti disponibili senza minacciare direttamente le piattaforme di Meta per gli inserzionisti o gli utenti.
Meta mira a sfruttare l’Intelligenza Artificiale open source per aumentare l’coinvolgimento degli utenti, migliorare i suoi prodotti (fine Tuning) e servizi e aumentare i profitti, senza compromettere il suo core business.
Yann LeCun :
Meta sta implementando una strategia innovativa che va oltre i tradizionali modelli di business basati sulla pubblicità (ADV) e sui pagamenti per servizi. Questa strategia prevede la distribuzione gratuita di un modello a milioni di persone e sviluppatori. L’obiettivo è stimolare la creazione di soluzioni che possano essere utili per i clienti di Meta.
Gli sviluppatori, avendo accesso al modello, possono creare e personalizzare le loro soluzioni, che possono variare da applicazioni a servizi. Queste soluzioni, una volta create, possono essere acquisite da Meta, creando così un ciclo di innovazione e crescita.
In sostanza, Meta sta cercando di costruire rapidamente una comunità di produttori che creano modelli specifici con l’intenzione di acquisirli successivamente. Questo processo include la verifica della piattaforma alla fonte, il controllo di ciò che viene creato e la selezione di ciò che può essere integrato nella sua piattaforma. Questa strategia consente a Meta di rimanere all’avanguardia nell’innovazione, garantendo al contempo che le soluzioni più utili e pertinenti siano rese disponibili ai suoi clienti.
“La scommessa è che Meta ha già una base utenti e customer base. Quello che offriamo sarà utile a loro e c’è un modo per ricavare revenue da questi servizi. Per noi non ha un impatto se forniamo il modello base in open source per consentire ad altri di costruire applicazioni. Se queste applicazioni sono utili ai nostri clienti e noi possiamo comprarle da loro, può essere che migliorino la piattaforma“, il pensiero dell’azienda.


Microsoft ha recentemente introdotto VASA-1, un modello di intelligenza artificiale che produce video realistici di volti parlanti da una singola immagine statica e una clip audio.
Il modello è in grado di produrre video con una risoluzione di 512×512 pixel e una frequenza di 40 fotogrammi al secondo (FPS), con una latenza di soli 170 millisecondi sui sistemi GPU NVIDIA RTX 4090.
L’architettura del modello si basa su un approccio di diffusione.
A differenza dei metodi tradizionali che trattano le caratteristiche facciali separatamente, VASA-1 utilizza un modello basato sulla diffusione per generare dinamiche facciali e movimenti della testa in modo olistico. Questo metodo considera tutte le dinamiche facciali, come il movimento delle labbra, l’espressione e i movimenti degli occhi, come parti di un unico modello completo.
VASA-1 opera all’interno di uno spazio latente del viso districato ed espressivo, che gli permette di controllare e modificare le dinamiche facciali e i movimenti della testa indipendentemente da altri attributi facciali come l’identità o l’aspetto statico.
Il modello è stato addestrato su un set di dati ampio e diversificato, che gli consente di gestire un’ampia gamma di identità facciali, espressioni e modelli di movimento. Questo approccio di addestramento aiuta il modello a funzionare bene anche con dati di input che si discostano da ciò su cui è stato addestrato, come input audio non standard o immagini artistiche.
L’addestramento del modello prevede tecniche avanzate di districamento, che consentono la manipolazione separata delle caratteristiche facciali dinamiche e statiche. Ciò si ottiene attraverso l’uso di codificatori distinti per diversi attributi e una serie di funzioni di perdita attentamente progettate per garantire un’efficace separazione di queste caratteristiche.
VASA-1 è stato rigorosamente testato rispetto a vari benchmark e ha dimostrato di superare significativamente i metodi esistenti in termini di realismo, sincronizzazione degli elementi audiovisivi ed espressività delle animazioni generate.
Nonostante i risultati promettenti, la ricerca riconosce alcuni limiti del modello, come l’incapacità di elaborare le dinamiche di tutto il corpo o di catturare completamente elementi non rigidi come i capelli. Tuttavia, sono previsti lavori futuri per espandere le capacità del modello e affrontare queste aree.
L’Intelligenza Artificiale (AI) per immagini e video ha rivoluzionato molti settori, tra cui il riconoscimento di oggetti, l’analisi delle immagini mediche, la sorveglianza di sicurezza, la creazione di contenuti multimediali e molto altro. Ecco alcuni esempi di come l’AI viene utilizzata per immagini e video:
Altri esempi di Modelli in allegato
Newsletter AI – non perderti le ultime novità sul mondo dell’Intelligenza Artificiale, i consigli sui tool da provare, i prompt e i corsi di formazione. Iscriviti alla newsletter settimanale e accedi a un mondo di contenuti esclusivi direttamente nella tua casella di posta!
[newsletter_form type=”minimal”]

La società deve affrontare la questione cruciale della fiducia in sistemi che dimostrano una capacità di auto-evoluzione, e questo è un tema che Isaac Asimov ha affrontato nelle sue opere di fantascienza.
Asimov è noto per la creazione delle “Tre leggi della robotica”, che sono state progettate per garantire che i robot non danneggino gli esseri umani o permettano che gli esseri umani vengano danneggiati attraverso l’inazione.
Tuttavia, come la società si avvicina allo sviluppo di sistemi di intelligenza artificiale sempre più sofisticati e autonomi, la questione della fiducia e del controllo diventa ancora più complessa.
La capacità di auto-evolversi di un sistema di intelligenza artificiale significa che può imparare e adattarsi senza l’intervento umano, il che può portare a risultati imprevisti o indesiderati.
Questo solleva domande su come possiamo garantire che tali sistemi operino in modo sicuro ed etico, e su come possiamo garantire che siano conformi alle leggi e alle normative umane.
A questa necessita’ viene icontro il Curiosity-Driven Red-Teaming (CRT) è un metodo innovativo per migliorare la sicurezza dei Large Language Models (LLMs), come i chatbot AI.
I ricercatori dell’Improbable AI Lab del MIT e del MIT-IBM Watson AI Lab hanno utilizzato l’apprendimento automatico per migliorare il red-teaming. Hanno sviluppato una tecnica per addestrare un modello linguistico di grandi dimensioni del team rosso a generare automaticamente diversi suggerimenti che attivano una gamma più ampia di risposte indesiderate dal chatbot in fase di test.
Lo fanno insegnando al modello della squadra rossa a essere curioso quando scrive i suggerimenti e a concentrarsi su nuovi suggerimenti che evocano risposte tossiche dal modello target.
Questo approccio utilizza l’esplorazione guidata dalla curiosità per ottimizzare la novità, formando modelli di red team per generare un insieme di casi di test diversi ed efficaci.
Tradizionalmente, il processo di verifica e test delle risposte di un LLM coinvolgeva un “red team” umano che creava prompt di input specifici per cercare di provocare risposte indesiderate dall’LLM.
Questo processo può essere sia costoso che lento. Di recente, sono stati sviluppati metodi automatici che addestrano un LLM separato, con l’apprendimento per rinforzo, per generare test che massimizzino la probabilità di suscitare risposte indesiderate dal LLM target.
Tuttavia, questi metodi tendono a produrre un numero limitato di casi di test efficaci, offrendo quindi una copertura limitata delle potenziali risposte indesiderate.
CRT supera questa limitazione collegando il problema della generazione di test alla strategia di esplorazione guidata dalla curiosità.
Questo approccio non solo aumenta la copertura dei casi di test, ma mantiene o aumenta anche la loro efficacia, migliorando significativamente la valutazione complessiva della sicurezza dei LLM.
La metodologia CRT si è rivelata molto utile nel generare output tossici da modelli LLM che erano stati addestrati con cura per prevenire tali output.
Questo studio evidenzia l’importanza di esplorare nuovi metodi per aumentare l’efficacia e la copertura dei test di sicurezza per i LLM, specialmente alla luce della loro crescente capacità e diffusione in applicazioni pratiche.
Per ulteriori dettagli, puoi consultare il documento originale “Curiosity-driven Red-teaming for Large Language Models” pubblicato su OpenReview o il codice sorgente disponibile su GitHub.
Official implementation of ICLR’24 paper, “Curiosity-driven Red Teaming for Large Language Models” (https://openreview.net/pdf?id=4KqkizXgXU)
I coautori di Hong includono gli studenti laureati EECS Idan Shenfield, Tsun-Hsuan Wang e Yung-Sung Chuang; Aldo Pareja e Akash Srivastava, ricercatori del MIT-IBM Watson AI Lab; James Glass, ricercatore senior e capo dello Spoken Language Systems Group presso il Laboratorio di informatica e intelligenza artificiale (CSAIL); e l’autore senior Pulkit Agrawal, direttore di Improbable AI Lab e assistente professore al CSAIL. La ricerca sarà presentata alla Conferenza Internazionale sulle Rappresentazioni dell’Apprendimento.
L’integrazione del Curiosity-Driven Red Teaming (CRT) nella sicurezza dei chatbot e dei Large Language Models (LLMs) rappresenta un significativo progresso, evidenziando una trasformazione fondamentale nella gestione e mitigazione delle risposte indesiderate generate dall’intelligenza artificiale.
Questo metodo, attraverso l’automazione e l’efficienza incrementata, non solo supera i limiti tradizionali di costi, tempo e varietà nei test, ma pone anche questioni etiche sul ruolo umano in questo processo evolutivo.
L’aumento dell’autonomia dell’IA, che sta progredendo nella generazione autonoma del proprio codice software e nel monitoraggio delle proprie prestazioni, indica una trasformazione nel settore industriale orientata all’efficienza temporale e alla riduzione dei costi associati allo sviluppo.
Tuttavia, questa evoluzione solleva interrogativi significativi sull’autoreferenzialità dell’IA e sulla potenziale assenza di supervisione umana, portando a riflessioni sulla regolamentazione e sul controllo etico dell’evoluzione dell’IA.
La società deve affrontare la questione cruciale della fiducia in sistemi che dimostrano una capacità di auto-evoluzione, un circolo che, seppur virtuoso in termini di innovazione tecnologica, presenta dilemmi etici profondi.
In questo scenario, l’elaborazione di norme assume una rilevanza fondamentale, con alcune regioni che prendono la guida nella stesura di regolamenti destinati a orientare l’evoluzione dell’IA.
Persiste ancora ambiguità riguardo all’interpretazione e all’applicazione di tali direttive da parte dell’IA, che sta diventando sempre più indipendente e potrebbe non aderire ai dettami umani.
Questa prospettiva solleva interrogativi sulla reale attuazione di certe norme, che pongono al centro la sicurezza umana e la sottomissione dei sistemi robotici alla volontà umana, evidenziando le sfide nell’implementarle in contesti di AI avanzata e sempre più autonoma.
L’evoluzione dell’IA è un tema complesso e articolato che richiede una riflessione attenta sui potenziali benefici e rischi associati al suo sviluppo. Se da un lato l’aumento dell’autonomia dell’IA ha il potenziale per rivoluzionare i settori e migliorare l’efficienza, dall’altro solleva questioni etiche sul ruolo umano nello sviluppo e nella regolamentazione dell’IA.
Come società, dobbiamo lavorare insieme per garantire che l’evoluzione dell’IA sia guidata da principi di sicurezza, etica e trasparenza, e che i suoi benefici siano accessibili a tutti.