

Adobe ha deciso di spingere il pedale sull’intelligenza artificiale, e lo fa aggiornando Premiere Pro con funzionalità che sembrano uscite da un film di fantascienza. La versione 25.2 del celebre software di montaggio video introduce strumenti avanzati per localizzare, tradurre ed estendere i filmati, portando alcune delle innovazioni più attese fuori dalla fase beta e mettendole finalmente a disposizione di tutti gli utenti.
Categoria: AI Pagina 1 di 14
L’ hub-per-una-copertura-completa-sullintelligenza-artificiale-e-lapprendimento-automatico

L’Intelligenza Artificiale sta cambiando radicalmente il modo in cui aziende e professionisti prendono le decisioni critiche. Grazie all’analisi avanzata dei dati e agli algoritmi predittivi, oggi possiamo dire che l’IA predice il futuro con un’accuratezza sorprendente. Che si tratti di stimare le vendite di un prodotto, prevedere il comportamento degli utenti o anticipare con buoni risultati le tendenze del mercato, le soluzioni basate sull’IA permettono di ridurre l’incertezza e ottimizzare le strategie aziendali.
In questo articolo parleremo proprio di come l’IA predice il futuro in diversi settori, quali sono le tecnologie che permettono queste previsioni e come possiamo sfruttarle per ottenere un vantaggio competitivo, economico o quello che preferisco io ossia risparmiare tempo.

Se pensavate che l’intelligenza artificiale fosse già una scatola nera impenetrabile, tenetevi forte: ora ci sono intelligenze artificiali che progettano altre intelligenze artificiali. Questo è il cuore del paper “Automated Design of Agentic Systems” di Shengran Hu e colleghi, che propone un algoritmo chiamato Meta Agent Search per generare agenti sempre più performanti senza l’intervento umano. Praticamente, un Frankenstein digitale che assembla se stesso pezzo dopo pezzo.
La promessa è affascinante e al tempo stesso inquietante: eliminare la progettazione manuale e lasciare che gli algoritmi trovino da soli il modo più efficace di risolvere i problemi. Vi suona familiare? Dovrebbe. La storia dell’informatica è costellata di momenti in cui qualcuno ha detto “eliminiamo il bisogno dell’uomo” per poi ritrovarsi a dover gestire un sistema ancora più complesso e incomprensibile. Vedi il passaggio dagli algoritmi artigianali al deep learning, che ci ha regalato reti neurali potentissime ma talmente oscure da richiedere interi dipartimenti di ricerca per capire cosa diavolo stiano facendo.

Baidu ha lanciato due nuovi modelli di intelligenza artificiale, Ernie 4.5 e Ernie X1, dichiarando che superano le prestazioni di DeepSeek e OpenAI su diversi benchmark. La competizione nel settore dei modelli linguistici di grande scala (LLM) si intensifica, con la società cinese che cerca di riaffermare la sua leadership dopo essere stata sfidata da giganti locali come Alibaba, Tencent e Bytedance.
Il nuovo Ernie 4.5 è un modello multimodale in grado di gestire testo, immagini, audio e video, e secondo Baidu ha superato GPT-4o di OpenAI in diversi test di benchmark, tra cui CCBench e OCRBench. Inoltre, in termini di capacità testuali, il modello ha dimostrato prestazioni superiori a DeepSeek V3 e comparabili a GPT-4.5. Questa mossa posiziona Baidu in prima linea nel panorama dell’AI in Cina, dove l’adozione di LLM è diventata un fattore strategico per il dominio tecnologico.

Meta ha recentemente annunciato i large concept models (lcm), introducendo un nuovo paradigma nella modellazione del linguaggio naturale che supera le limitazioni degli attuali large language models (llm).
Mentre i llm tradizionali operano a livello di token, prevedendo parola per parola, gli lcm si focalizzano su concetti più astratti, rappresentati da intere frasi in spazi semantici multidimensionali.
Questa innovazione consente agli lcm di comprendere e generare contenuti con una coerenza e profondità semantica superiori, avvicinandosi al modo in cui gli esseri umani elaborano le informazioni. utilizzando lo spazio di embedding sonar, che supporta fino a 200 lingue sia in formato testuale che vocale.
Alibaba ha recentemente lanciato una versione aggiornata di Quark, un’applicazione che funge da assistente personale avanzato, integrando le capacità del modello di intelligenza artificiale Qwen. Originariamente introdotto nel 2016 come browser web, Quark si è evoluto in una piattaforma leader nei servizi informativi basati sull’IA, vantando oltre 200 milioni di utenti in Cina.
La nuova versione di Quark sfrutta le capacità avanzate di Qwen 2.5-Max, un modello MoE (Mixture-of-Experts) su larga scala pre-addestrato su oltre 20 trilioni di token. Questo modello è stato ulteriormente perfezionato utilizzando metodologie come il Supervised Fine-Tuning (SFT) e il Reinforcement Learning from Human Feedback (RLHF), migliorando significativamente le prestazioni in compiti complessi come la risoluzione di problemi matematici, la programmazione e la scrittura creativa.

Costa veramente 6 milioni di dollari o ci sono costi nascosti di DeepSeek che non conosciamo?
DiPLab ha appena pubblicato uno studio sulla nascita e la crescita di DeepSeek, analizzando quanto è vera la storia della creazione di un sistema LLM a basso costo. DeepSeek è veramente costata solo 6 milioni di dollari? Nelle interviste sono stati tralasciati altri costi, come quelli del lavoro di addestratori e taggatori? Ricerche e analisi tecnico-economiche iniziano a pubblicare cosa è stato scoperto.

Immaginate un’intelligenza artificiale che non si limita a rispondere alle vostre domande, ma che prende in mano il lavoro e lo porta a termine dall’inizio alla fine, senza bisogno di supervisione umana. Questo non è più un sogno fantascientifico, ma una realtà concreta che la Cina ha appena svelato con il lancio di Manus, un agente AI destinato a ridefinire il panorama tecnologico globale. Presentato il 5 marzo 2025 dall’azienda Monica.im, Manus sta già facendo parlare di sé, suscitando entusiasmo e interrogativi sul futuro dell’automazione.

Nel precedente articolo “Introduzione a Grok 3” abbiamo esplorato le principali caratteristiche del modello, le funzionalità principali, le sue potenzialità e i suoi limiti. Analizziamo adesso come massimizzare l’efficacia di Grok 3, con una serie di suggerimenti utili per ottenere i risultati migliori dal suo utilizzo.

Abbiamo visto in un precedente articolo come Alibaba abbia compiuto un passo strategico nell’arena dell’Intelligenza Artificiale generativa, rendendo open-source il suo modello Wan 2.1, specializzato nella creazione di immagini e video. Vediamone da vicino le potenzialità con 10 esempi particolarmente impressionanti.

La serie di modelli Grok è costruita su algoritmi avanzati di deep learning, addestrati su vasti set di dati per comprendere le complessità del linguaggio umano. Grazie a queste tecnologie, Grok è in grado di riconoscere schemi e strutture linguistiche sofisticate, generando testi che rispecchiano fedelmente la scrittura umana. Questo lo rende ideale per una vasta gamma di applicazioni di elaborazione del linguaggio naturale (NLP), tra cui completamento del testo, traduzione, riassunti automatici e molto altro.
Con l’arrivo di Grok 3, la nuova generazione della serie, l’intelligenza artificiale compie un ulteriore salto in avanti. Questo modello introduce maggiori capacità computazionali, un supporto multilingue più avanzato e abilità di ragionamento e comprensione migliorate, ampliando il suo impatto in numerosi settori.

Ci credi se ti dico che l’Intelligenza Artificiale (AI) e l’apprendimento automatico (ML) sono gli strumenti ideali per conoscere meglio i tuoi utenti?
Grazie a queste tecnologie, è possibile raccogliere, analizzare e interpretare una grande e varia quantità di dati per ottenere una comprensione più profonda dei comportamenti, delle preferenze e delle esigenze degli utenti. Questo permette di personalizzare l’esperienza utente, migliorare i prodotti e i servizi offerti e, in ultima analisi, aumentare la soddisfazione e la fidelizzazione dei clienti.
Vediamo come.

Adobe ha recentemente lanciato in beta pubblica il suo innovativo strumento di generazione video basato su intelligenza artificiale, denominato
. Questo strumento, accessibile tramite la rinnovata applicazione web Firefly, rappresenta un significativo passo avanti nell’integrazione dell’IA nei processi creativi, offrendo funzionalità avanzate sia per professionisti che per appassionati del settore.
Generate Video si articola in due principali funzionalità: Text-to-Video e Image-to-Video. La prima consente agli utenti di creare video a partire da descrizioni testuali dettagliate, permettendo una traduzione diretta delle idee in sequenze visive. La seconda, Image-to-Video, permette di utilizzare un’immagine di riferimento insieme al prompt testuale, fornendo un punto di partenza visivo per la generazione del video. Queste funzionalità sono arricchite da opzioni che consentono di affinare o guidare i risultati, come la simulazione di stili, angolazioni della telecamera, movimenti e distanze di ripresa.

ByteDance, in collaborazione con l’Università di Hong Kong, ha presentato Goku e Goku+, una nuova famiglia di modelli di intelligenza artificiale progettati per superare il divario tra la generazione di immagini e quella di video. Grazie a un’architettura unificata e tecniche avanzate di elaborazione visiva, questi modelli stanno ridefinendo gli standard del settore, ottenendo prestazioni da record nei principali benchmark visivi e aprendo nuove possibilità per la creazione di contenuti commerciali iperrealistici.

6ai Technologies non si limita a sviluppare un altro Large Language Model (LLM), ma adotta un approccio radicalmente differente, basato su un’architettura altamente ottimizzata e proprietaria. Partendo dall’open-source, integra elementi utili in un framework esclusivo che combina FLM-T (Focused Language Model – Tuned) e CCQF (Cognitive Computational Query Framework), con l’obiettivo di offrire un sistema di intelligenza applicata estremamente specifico, performante e scalabile.
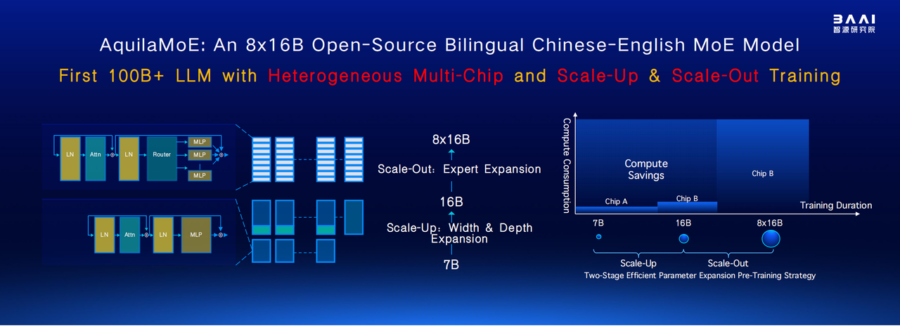
Il Beijing Academy of Artificial Intelligence (BAAI) ha introdotto AquilaMoE, un avanzato modello linguistico basato su una struttura Mixture of Experts (MoE) da 8*16B, progettato per ottenere prestazioni elevate con un’efficienza senza precedenti. Il cuore della sua innovazione è EfficientScale, una metodologia di addestramento a due fasi che massimizza il trasferimento di conoscenza riducendo il fabbisogno di dati e calcolo.
L’approccio Scale-Up permette di inizializzare un modello più grande a partire dai pesi di uno più piccolo, ottimizzando l’uso dei dati e accelerando l’apprendimento. Successivamente, la fase Scale-Out trasforma un modello denso in un modello MoE, migliorando ulteriormente l’efficienza computazionale e la capacità del modello. Queste strategie consentono ad AquilaMoE di superare le limitazioni degli attuali modelli di linguaggio, offrendo prestazioni superiori con minori costi computazionali.

In un emozionante sviluppo per il mondo della robotica, Hugging Face ha ufficialmente portato i suoi primi modelli fondamentali per la robotica nel repository LeRobot. I modelli π0 e π0-FAST, sviluppati da Physical Intelligence, sono ora disponibili, offrendo all’ecosistema di Hugging Face una soluzione all’avanguardia per l’intelligenza artificiale generale per i robot. Questi nuovi modelli rappresentano un passo significativo verso la creazione di sistemi robotici versatili, in grado di svolgere una vasta gamma di compiti con diverse incarnazioni fisiche. Grazie all’integrazione dei modelli Vision-Language-Action (VLA), questi sviluppi mirano a portare i robot più vicini a un’adattabilità simile a quella umana, permettendo loro non solo di comprendere i compiti, ma anche di interagire fisicamente con l’ambiente circostante.
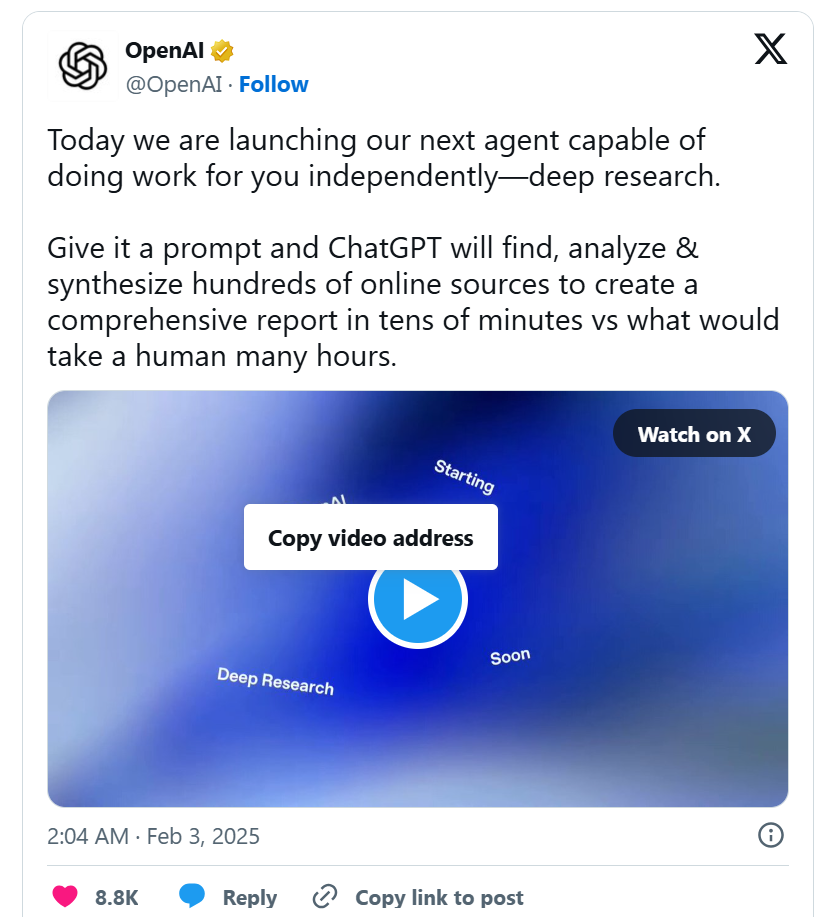
OpenAI ha appena lanciato l’ennesima novità per ChatGPT: Deep Research, un’aggiunta che promette di trasformare il chatbot da semplice generatore di testo in un analista autonomo capace di pianificare, eseguire ricerche multi-step e perfino tornare sui propri passi se necessario. Un’intelligenza artificiale che finalmente può correggersi da sola? Quasi, ma non troppo.
L’idea è che ora ChatGPT non si limiti a rispondere con il solito testo preconfezionato, ma mostri un processo di ricerca “trasparente” nella nuova barra laterale, includendo citazioni e spiegazioni su come ha costruito la sua risposta. Un’innovazione che suona rassicurante, fino a quando OpenAI stessa ammette che Deep Research può ancora allucinare fatti inesistenti, confondere bufale con dati ufficiali e non avere la minima idea di quanto sia sicuro delle sue risposte. Insomma, un po’ come un analista finanziario sotto pressione, ma con meno senso della realtà.

L’intelligenza artificiale sta rivoluzionando il panorama aziendale e Grok 3 di xAI è in prima linea in questa trasformazione. Questa guida completa approfondisce le capacità di Grok 3 ed esplora le sue diverse applicazioni nel business online.
Cos’è Grok 3?
Grok 3 è un modello linguistico AI avanzato sviluppato da xAI, progettato per generare testi e immagini simili a quelli umani in base alle richieste degli utenti. Utilizzando un’architettura di rete neurale basata su trasformatori, Grok 3 elabora e produce contenuti contestualmente rilevanti, rendendolo uno strumento versatile in vari campi, dall’elaborazione del linguaggio naturale alla creazione di contenuti.
Come funziona Grok 3?
Utilizzando una rete neurale basata su trasformatori con più livelli di autoattenzione, Grok 3 apprende le relazioni contestuali tra parole e frasi. Genera contenuti prevedendo la parola o la frase più probabile in un determinato contesto, consentendo di ottenere risultati coerenti e adeguati al contesto. Inoltre, Grok 3 offre funzionalità di generazione di immagini grazie all’integrazione con FLUX.1, consentendo agli utenti di creare immagini da descrizioni testuali.
Applicazioni di Grok 3 nel business online
- Creazione di contenuti: Grok 3 è in grado di generare articoli di alta qualità, descrizioni di prodotti, post sui social media e altri tipi di contenuti, semplificando il processo di produzione dei contenuti per le aziende;
- Servizio clienti: generando risposte automatiche alle richieste dei clienti, Grok 3 migliora l’efficienza e l’accuratezza dell’assistenza clienti;
- Marketing: Grok 3 aiuta a creare testi pubblicitari convincenti, campagne di e-mail marketing e altri materiali promozionali, aiutando le aziende a coinvolgere efficacemente il proprio pubblico di riferimento;
- E-commerce: Grok 3 è in grado di creare descrizioni dettagliate dei prodotti, recensioni e raccomandazioni personalizzate, contribuendo ad aumentare le vendite e a migliorare la soddisfazione dei clienti.
Le applicazioni e gli usi principali di Grok-3
Creazione e modifica di contenuti: Grok-3 è in grado di generare contenuti scritti di alta qualità, tra cui articoli, post di blog e aggiornamenti dei social media. Assiste gli scrittori fornendo bozze, suggerendo modifiche e migliorando la qualità complessiva del testo.
Assistenza alla programmazione: grazie alle sue avanzate capacità di ragionamento, Grok-3 aiuta nella generazione e nel debug del codice. Può scrivere frammenti di codice complessi, identificare errori e suggerire ottimizzazioni, semplificando il processo di sviluppo.
Analisi di mercato e previsioni: Grok-3 analizza i dati di mercato in tempo reale per prevedere le tendenze, aiutando gli analisti finanziari e le aziende a prendere decisioni di investimento informate.
Automazione dell’assistenza clienti: Generando risposte accurate e contestualmente pertinenti, Grok-3 migliora il servizio clienti attraverso chatbot e assistenti virtuali, migliorando il coinvolgimento e la soddisfazione degli utenti.
Supporto didattico: Grok-3 funge da tutor virtuale, spiegando concetti complessi, risolvendo problemi e fornendo esperienze di apprendimento personalizzate in varie materie.
Arte creativa e intrattenimento: il modello aiuta a generare contenuti creativi come storie, poesie e persino progetti di giochi, promuovendo l’innovazione nelle industrie dell’arte e dell’intrattenimento.
Comunicazione multilingue: il supporto multilingue di Grok-3 consente di tradurre e comunicare senza problemi in diverse lingue, abbattendo le barriere linguistiche nelle interazioni globali.
Recupero delle informazioni in tempo reale: integrato con piattaforme come X (ex Twitter), Grok-3 fornisce informazioni aggiornate, analisi delle tendenze e tracciamento degli eventi, mantenendo gli utenti informati in tempo reale.
Assistenza alle diagnosi mediche: utilizzando le sue capacità di ragionamento, Grok-3 analizza sintomi e dati medici per assistere gli operatori sanitari nella diagnosi di condizioni complesse.
Ricerca e analisi dei dati: Grok-3 aiuta i ricercatori riassumendo grandi insiemi di dati, generando ipotesi e fornendo approfondimenti, accelerando così il processo di ricerca.
Come abbiamo visto quindi, la versatilità e le funzioni avanzate di Grok-3 ne fanno una risorsa preziosa in diversi settori, migliorando l’efficienza, la creatività e i processi decisionali.
NdR. Sullo stesso argomento vedi anche: “Introduzione a Grok 3” e “Consigli e trucchi per l’uso di Grok 3“
Newsletter – Non perderti le ultime novità sul mondo dell’Intelligenza Artificiale: iscriviti alla nostra newsletter gratuita e accedi ai contenuti esclusivi di Rivista.AI direttamente nella tua casella di posta!

La competizione nel mondo dell’intelligenza artificiale e delle soluzioni di calcolo avanzato è sempre più agguerrita, con aziende come NVIDIA che detengono una fetta importante del mercato grazie alle loro GPU e ai processori specializzati per il deep learning. Tuttavia, un attore emergente come Huawei, con la sua serie di chip Ascend, sta facendo rumore, proponendo soluzioni ad alte prestazioni come l’Ascend 910C, che, pur con un prezzo nettamente inferiore, offre capacità di calcolo sorprendenti. Questo scenario diventa ancora più interessante quando si considera l’influenza del ban tecnologico USA e il ruolo che piattaforme come DeepSeek potrebbero svolgere nell’adozione di queste nuove soluzioni.

DeepSeek AI ha presentato DeepSeek-R1, un modello open source che si pone come un diretto concorrente del noto OpenAI-o1 nei compiti di ragionamento complesso. Questo traguardo è stato raggiunto grazie all’introduzione di un algoritmo innovativo chiamato Group Relative Policy Optimization (GRPO) e a un approccio multi-stage basato sul reinforcement learning (RL). La combinazione di queste tecniche ha consentito di superare molte delle limitazioni tradizionali nei modelli di intelligenza artificiale per il ragionamento avanzato.

Con il rilascio di Janus Pro, il laboratorio cinese DeepSeek ha lanciato una sfida diretta a DALL-E 3, il modello generativo di immagini di punta di OpenAI. Janus Pro si distingue per essere un modello open-source che offre prestazioni superiori in benchmark chiave come GenEval e DPG-Bench, una mossa che potrebbe ridefinire gli equilibri tra i leader dell’intelligenza artificiale multimodale.

Meta ha annunciato un’espansione significativa delle capacità del suo chatbot AI, che ora sarà in grado di “ricordare” dettagli personali degli utenti, come preferenze alimentari o interessi, migliorando così le interazioni e rendendo le raccomandazioni più pertinenti. Questa nuova funzione, spiegata in un post sul blog aziendale, rappresenta un ulteriore passo nella personalizzazione dell’esperienza utente, utilizzando non solo le conversazioni precedenti, ma anche informazioni provenienti dagli account Facebook e Instagram degli utenti.

La società cinese DeepSeek, già al centro dell’attenzione per il rilascio del modello open-source R1, ha lanciato un secondo modello multimodale open-source, Janus Pro-7B, che promette di ridefinire gli standard nell’intelligenza artificiale. Il modello è stato reso disponibile su Hugging Face, una piattaforma leader per l’IA, con l’obiettivo dichiarato di offrire comprensione e generazione unificata. Secondo DeepSeek, il Janus Pro-7B supera i precedenti modelli multimodali unificati e compete, se non addirittura eccelle, rispetto alle prestazioni dei modelli specifici per singoli compiti. Questo lo rende un forte candidato per le applicazioni di prossima generazione nel campo multimodale.
DeepSeek says its newest AI model, Janus-Pro can outperform Stable Diffusion and DALL-E 3.
Already riding a wave of hype over its R1 “reasoning” AI that is atop the app store charts and shifting the stock market, Chinese startup DeepSeek has released another new open-source AI model: Janus-Pro.
Può analizzare o produrre solo immagini piccole a una risoluzione di 384×384, ma l’azienda afferma che la versione più grande, Janus-Pro-7b, ha superato modelli comparabili in due test di riferimento per l’IA.
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25848993/Clipboard_01_27_2025_01.jpg)
Image: DeepSeek
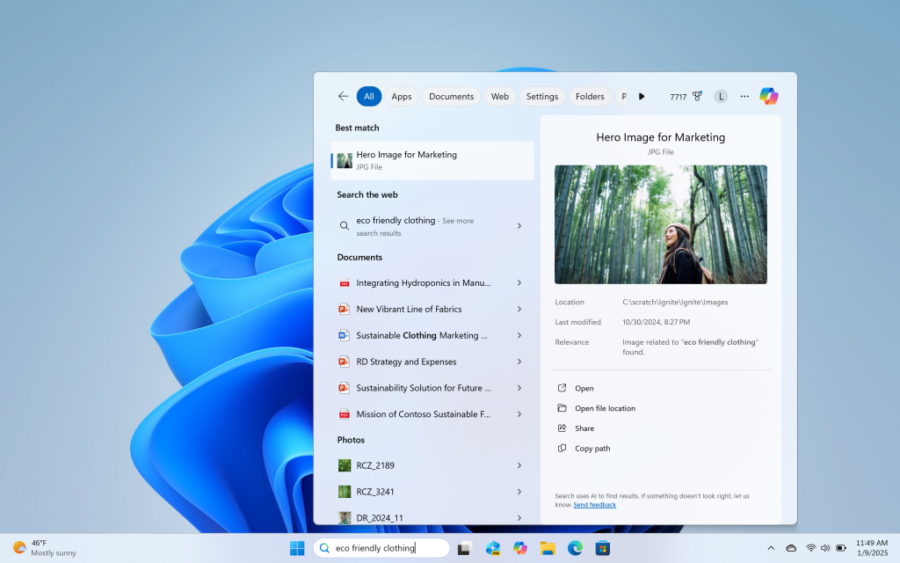
Microsoft ha recentemente avviato una fase di test per una delle novità più promettenti della prossima versione di Windows 11, introducendo una funzionalità di ricerca alimentata dall’intelligenza artificiale. L’innovativa ricerca semantica, annunciata a ottobre, è ora disponibile per gli utenti Insider su build dedicate, e promette di semplificare l’esperienza di ricerca dei file locali, rendendola più intuitiva grazie all’uso di linguaggio naturale.
L’innovazione si inserisce nel contesto di una costante evoluzione delle funzionalità AI di Microsoft, che mirano a rendere l’interazione con il sistema operativo sempre più fluida e naturale. A differenza dei tradizionali motori di ricerca che richiedono comandi o parole chiave specifiche, questa nuova funzionalità consente agli utenti di esprimere ricerche più casuali e colloquiali, come se stessero chiedendo aiuto a un assistente virtuale.

Negli ultimi anni, i transformers hanno rappresentato il punto di riferimento per i modelli di intelligenza artificiale, dalla traduzione automatica alla modellazione linguistica, fino al riconoscimento delle immagini. Tuttavia, la loro egemonia potrebbe essere messa in discussione da due innovazioni che promettono di ridefinire il panorama dell’AI: le architetture “Titans” di Google e “Transformer Squared” sviluppata dalla startup giapponese Sakana. Questi nuovi modelli, ispirati al funzionamento del cervello umano, puntano a superare i limiti dei transformer tradizionali, rendendo i sistemi più efficienti, flessibili e intelligenti.
I transformers hanno trasformato l’AI grazie al meccanismo di attention, che consente di valutare il contesto di ogni elemento in una sequenza. Questa tecnologia ha introdotto la possibilità di elaborare dati in parallelo, rendendo obsoleti i recurrent neural networks (RNN), che lavoravano in modo sequenziale. Tuttavia, i transformers tradizionali hanno mostrato notevoli limiti in termini di scalabilità, adattabilità e memoria a lungo termine. Una volta addestrati, migliorare il loro funzionamento richiede enormi risorse computazionali o l’uso di strumenti esterni come i modelli LoRA o RAG.

Sembra una barzelletta: un gruppo di studenti e consulenti dell’Università di Berkeley tira fuori un modello di intelligenza artificiale di ragionamento avanzato, e il tutto con un budget inferiore a quello di una cena elegante a San Francisco. Non c’è trucco, non c’è inganno: il modello Sky-T1-32B è qui per scompigliare le carte e rendere obsoleti i costosi abbonamenti mensili di OpenAI.
Immaginate questo: OpenAI, con le sue decine di miliardi di dollari di investimenti, giustifica il costo di $200 al mese per un abbonamento ChatGPT Pro basato sul loro modello di ragionamento più avanzato, sostenendo che “è costoso allenare e mantenere queste meraviglie tecnologiche”. Poi arriva Novasky e fa lo stesso lavoro, o meglio, con appena $450. Il modello Sky-T1, che ricorda il primo tentativo di OpenAI nel campo del ragionamento (il modello “Strawberry”), supera quest’ultimo in alcune metriche e si piazza con disinvoltura sul podio delle prestazioni.

Il team non ha ancora rivelato una tempistica precisa per il lancio del nuovo generatore video, suggerendo che il progetto sia ancora in una fase iniziale di sviluppo. Al momento, gli sviluppatori stanno lavorando per “bilanciare velocità, costo e qualità dell’output,” come dichiarato nell’annuncio ufficiale.
Circa l’85% degli utenti preferisce le immagini create utilizzando il sistema di personalizzazione della piattaforma, che ora include mood board e profili multipli, secondo Midjourney. L’azienda prevede di ampliare ulteriormente queste funzionalità, combinando i mood board con capacità di riferimento stilistico.
La piattaforma introdurrà inoltre due modalità di generazione distinte: una opzione “in tempo reale” per risultati rapidi, simile alla funzione “imagine” di Meta, al doodle-to-image di Krea AI o al Realtime Canvas di Leonardo.

Google DeepMind ha recentemente annunciato la formazione di un nuovo team dedicato allo sviluppo di “world models”, sistemi di intelligenza artificiale progettati per simulare ambienti fisici complessi. Questa iniziativa, guidata da Tim Brooks ex co-responsabile del progetto Sora di OpenAI mira a rivoluzionare settori come lo sviluppo di videogiochi, l’addestramento di robot e l’avanzamento verso l’Intelligenza Artificiale Generale (AGI).
I “world models” rappresentano un’evoluzione significativa nell’ambito dell’IA, poiché consentono la creazione di ambienti digitali che rispecchiano le dinamiche del mondo reale. Questa capacità è fondamentale per sviluppare sistemi di IA in grado di comprendere e interagire con il mondo fisico in modo più naturale ed efficiente.L’obiettivo di DeepMind è utilizzare vasti insiemi di dati video e multimodali per addestrare questi modelli, migliorando così la comprensione e l’adattabilità dell’IA a scenari reali.

SandboxAQ, la startup fondata da Jack Hidary, ha recentemente annunciato un finanziamento di oltre 300 milioni di dollari, portando la valutazione pre-money dell’azienda a 5,3 miliardi di dollari.
Questo investimento è stato guidato da figure di spicco come Eric Schmidt, Marc Benioff, Jim Breyer e Yann LeCun, evidenziando l’interesse crescente verso le tecnologie emergenti che combinano calcolo quantistico e intelligenza artificiale.
SandboxAQ, nata come spin-off di Alphabet Inc. nel 2022, si dedica allo sviluppo di soluzioni innovative all’intersezione tra intelligenza artificiale e tecniche quantistiche. Sotto la guida di Hidary, l’azienda ha rapidamente attirato l’attenzione di investitori e partner strategici, ottenendo contratti governativi per soluzioni di cybersecurity resistenti al quantum e avviando programmi pilota di navigazione quantistica con l’aeronautica statunitense.

OpenAI ha concluso l’anno con una dimostrazione impressionante delle sue capacità, presentando o3, un nuovo modello di ragionamento che ha mostrato prestazioni eccezionali su benchmark complessi. Sebbene non sia ancora disponibile pubblicamente, il modello è già stato valutato da tester di sicurezza, che hanno avuto l’opportunità di analizzarne il potenziale.
Tra i risultati più sorprendenti, spicca il punteggio di o3 sul test semi-privato ARC-AGI, dove ha ottenuto un impressionante 75,7% (87,5% con una configurazione ad alta potenza di calcolo), superando di gran lunga le prestazioni del suo predecessore, o1. Inoltre, o3 ha raggiunto il 25% sul benchmark estremamente difficile FrontierMath — un balzo notevole rispetto al misero 2% ottenuto dai modelli precedenti solo a novembre. Questi risultati hanno indubbiamente suscitato molta attenzione, ma è importante considerare una nota di cautela.
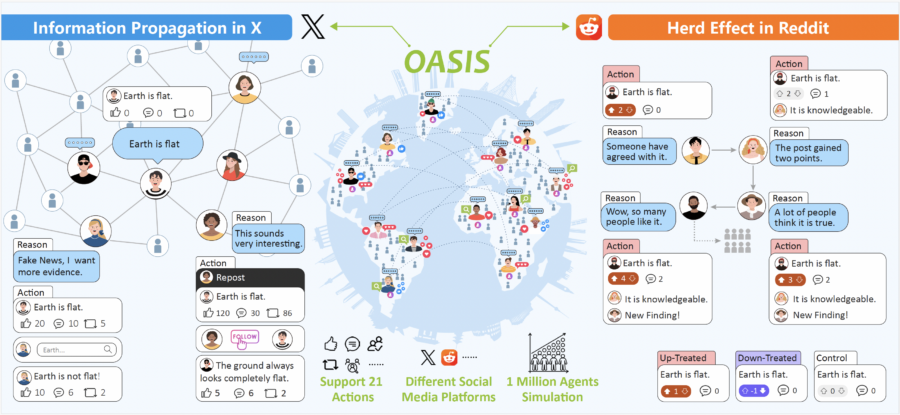
Camel-AI, in collaborazione con istituti di ricerca di prestigio come il Shanghai AI Laboratory, l’Università di Oxford e KAUST, ha recentemente lanciato OASIS (Open Agent Social Interaction Simulations), un framework avanzato per la simulazione dei social media. Questo strumento è progettato per modellare le interazioni online su piattaforme come X (precedentemente Twitter) e Reddit, offrendo preziose intuizioni a progettisti di piattaforme, ricercatori e decisori politici interessati a comprendere il comportamento degli utenti nel mondo digitale.
Una delle caratteristiche distintive di OASIS è la sua capacità di scalare fino a un milione di agenti, superando di gran lunga i simulatori precedenti che gestivano solo poche migliaia di utenti. Questa scalabilità consente di replicare dinamiche sociali su larga scala, fornendo un ambiente più realistico per lo studio di fenomeni complessi come la diffusione della disinformazione, la polarizzazione dei gruppi e la formazione delle comunità nei network sociali.

Google ha recentemente introdotto una funzionalità innovativa nell’app Files, che consente agli utenti di interagire direttamente con i contenuti dei PDF attraverso l’assistente AI, Gemini. Questa integrazione rappresenta un significativo passo avanti nell’ottimizzazione della gestione dei documenti digitali su dispositivi mobili.
Per accedere a questa funzione, è necessario essere abbonati a Gemini Advanced e disporre di un dispositivo con Android 15 o versioni successive. Una volta soddisfatti questi requisiti, aprendo un PDF nell’app Files e attivando Gemini, apparirà l’opzione “Chiedi informazioni su questo PDF”. Selezionando questa opzione, l’utente può porre domande specifiche sul contenuto del documento, ricevendo risposte immediate e pertinenti. Questo elimina la necessità di scorrere manualmente pagine di testo alla ricerca di informazioni, migliorando l’efficienza e l’esperienza d’uso.

Non ci sono modelli più potenti della nuova serie o3, almeno secondo OpenAI. Ma, si sa, loro sono di parte. Dicono che questi nuovi modelli siano così brillanti da fare impallidire anche un campione di scacchi in un giorno di pioggia. O almeno così affermano le loro presentazioni in power point.
Prendiamo il famoso benchmark ARC-AGI. Chiunque lo guardi pensa subito a un test per selezionare astronauti o risolvere indovinelli della Settimana Enigmistica. Invece, sembra misurare quanto un’IA sia capace di pensare come un umano. E o3 non solo supera il test, ma si avvicina alle prestazioni umane con un 87,5%. Certo, non significa che l’IA sappia cucinare un arrosto senza bruciarlo, ma almeno potrebbe dirti con precisione quante calorie contiene dopo il disastro.

OpenAI sta lavorando intensamente per sviluppare la prossima generazione del suo modello di ragionamento avanzato, noto internamente come “o1”. Questo modello è progettato per impiegare più tempo nel processo decisionale, dedicandosi a un’analisi più profonda delle domande poste dagli utenti prima di fornire risposte. L’obiettivo è migliorare significativamente la qualità delle risposte nei campi più complessi come la codifica, la matematica e le scienze avanzate.
Google ha presentato un nuovo modello di intelligenza artificiale chiamato Gemini 2.0 Flash Thinking, progettato per affrontare domande complesse e spiegare i processi logici utilizzati per arrivare alla soluzione. Questo sistema sperimentale rappresenta un’importante evoluzione nell’IA cognitiva, ponendosi come potenziale concorrente diretto del modello di ragionamento o1 di OpenAI.

Instagram si prepara a lanciare nel 2025 una nuova funzionalità che promette di cambiare radicalmente il modo in cui i creatori di contenuti modificano e personalizzano i loro video. Questo strumento di editing basato sull’intelligenza artificiale generativa, alimentato dal modello Movie Gen AI di Meta, consentirà agli utenti di modificare quasi ogni aspetto dei loro video tramite semplici comandi di testo, aprendo nuove possibilità di creatività e facilità per i creatori di contenuti.

OpenAI ha annunciato il rilascio dell’API di o1, un aggiornamento significativo che ridefinisce il modo in cui gli sviluppatori interagiscono con i modelli di intelligenza artificiale. Questa evoluzione introduce funzionalità avanzate come prompt di sistema, messaggi specifici per sviluppatori, chiamate di funzioni dinamiche, output strutturati e il rivoluzionario parametro “sforzo di ragionamento”. Chi non conosce il miglior film di tutti i tempi, Balle Spaziali : “Che lo sforzo sia con voi!”

YouTube sta collaborando con la Creative Artists Agency (CAA) per offrire agli artisti e ai creatori di contenuti un potente strumento di gestione delle loro immagini generate tramite intelligenza artificiale. Questa iniziativa mira a proteggere la loro identità digitale, permettendo di individuare e rimuovere contenuti che utilizzano il loro volto o voce senza autorizzazione. Il progetto sarà testato con celebrità e atleti a partire dal prossimo anno, per poi essere esteso ai principali creatori di YouTube e altri professionisti creativi.
YouTube sta introducendo una nuova funzionalità che consente ai creatori di contenuti di autorizzare aziende terze a utilizzare i loro video per addestrare modelli di intelligenza artificiale (AI). Questa opzione, disattivata di default, permette a chiunque voglia partecipare di abilitare l’accesso attraverso YouTube Studio. L’obiettivo dichiarato è offrire ai creatori nuove opportunità di guadagno nell’era dell’intelligenza artificiale.