
Hilarious
— Anshul Garg (@AnshulGarg1986) April 11, 2025
China is making some real stuff though AI right now.
China vs USA was heating up. MAGA#TrumpTariffs #stockmarketcrash #tariff pic.twitter.com/XYrT7tSIfZ
Categoria: Tecnologie Pagina 1 di 4
Strumenti e Framework per lo sviluppo AI

Amazon ha appena lanciato Nova Act, un nuovo modello di intelligenza artificiale progettato per eseguire compiti direttamente nel browser, tra cui navigare sul web, fare acquisti e persino rispondere a domande su ciò che appare sullo schermo. Per ora, è accessibile solo agli sviluppatori in una “anteprima di ricerca”, ma il colosso dell’e-commerce sta anche ampliando l’accesso agli altri modelli della famiglia Nova attraverso un portale web dedicato, semplificandone l’uso.
Il concetto di Nova Act richiama quello di Operator Agent di OpenAI, ma con un focus più pratico: può cercare prodotti, acquistarli e persino eseguire istruzioni dettagliate come “non accettare l’assicurazione aggiuntiva” durante un pagamento. Amazon afferma che il modello è già integrato in Alexa Plus, la nuova versione avanzata del suo assistente vocale, per gestire attività online con maggiore autonomia.
Se costruire sistemi AI pronti per la produzione sembra più un puzzle di strumenti scollegati che un processo fluido, allora hai capito il problema. Debugging che si disperde tra piattaforme diverse, valutazioni che non scalano senza ingegneri dedicati, e flussi di lavoro che sembrano più un rito voodoo che un’operazione scientifica.
Ora, immagina di poter tracciare, valutare, etichettare e gestire i tuoi dataset in un’unica piattaforma. Senza impazzire. Senza costi proibitivi.
Ecco Laminar, la piattaforma open-source di Y Combinator (batch S24) progettata per domare il caos dell’AI engineering. Unisce tracing, valutazioni, labeling e gestione dati in un unico ecosistema pensato per la produzione.

Le GPU NVIDIA per l’Intelligenza Artificiale sono molto utilizzate perché offrono grandi vantaggi rispetto alle CPU tradizionali. Il motivo principale è la loro capacità di elaborare più operazioni in parallelo, rendendole ideali per addestrare modelli di machine learning e deep learning. Grazie a questa architettura, possono gestire enormi quantità di dati in meno tempo, accelerando i processi di calcolo. Non è un caso che per il 2025 NVidia punti più all’Intelligenza artificiale che al mercato dei videogames.

Nvidia ha svelato al GTC 2025 i suoi nuovi “supercomputer AI personali”, il DGX Spark e il DGX Station, basati sulla piattaforma Grace Blackwell. Questi dispositivi permettono agli utenti di lavorare su modelli di intelligenza artificiale avanzati, senza necessità di connettersi a un datacenter. Il DGX Spark è già disponibile per il preordine, mentre il DGX Station rimane ancora senza un prezzo ufficiale.
Il DGX Spark è essenzialmente una rinascita del dispositivo presentato al CES con il nome “Digits”, un mini-supercomputer AI grande quanto un Mac Mini, venduto a 3.000 dollari. La sua potenza deriva dal GB10 Blackwell Superchip, dotato di Tensor Cores di quinta generazione e supporto FP4, capace di erogare fino a 1.000 trilioni di operazioni al secondo. Con 128GB di memoria unificata e fino a 4TB di storage NVMe SSD, questa macchina può gestire modelli AI fino a 200 miliardi di parametri, senza bisogno di infrastrutture colossali. In pratica, Nvidia ha miniaturizzato la potenza dell’intelligenza artificiale, rendendola accessibile a chiunque abbia una scrivania e una presa di corrente.

A marzo, di fronte a centinaia di giornalisti, analisti e clienti, il vicepresidente di Huawei, Eric Xu Zhijun, dichiarava con fermezza che l’azienda non avrebbe potuto produrre nuovi smartphone 5G senza l’approvazione del Dipartimento del Commercio degli Stati Uniti. “Se volete comprare un telefono Huawei 5G, dovrete aspettare il via libera degli USA”, disse con un tono rassegnato, quasi a voler sottolineare la dipendenza dell’azienda dalle decisioni di Washington. Accanto a lui, Meng Wanzhou – la figlia del fondatore e CFO della compagnia – si limitava a un enigmatico sorriso. Forse già sapeva qualcosa che il resto del mondo avrebbe scoperto solo mesi dopo.
E infatti, ad agosto, quando tutti davano Huawei per spacciata nel settore smartphone di fascia alta, ecco il colpo di scena: l’azienda lancia in sordina una prevendita del Mate 60 Pro, un modello che, sorpresa delle sorprese, supporta il 5G. Nessun annuncio trionfale, nessun evento pomposo, solo una discreta apertura degli ordini online. Qualche giorno dopo, arriva anche la versione premium, il Mate 60 Pro+, con la stessa modalità quasi clandestina. Come ha fatto Huawei a rilasciare un telefono 5G senza il permesso americano? La risposta è tanto semplice quanto imbarazzante per gli Stati Uniti: la Cina ha finalmente prodotto un chip avanzato senza bisogno della tecnologia occidentale.

In un mondo dove gli Stati Uniti stringono sempre più la morsa sulle esportazioni di chip avanzati, la Cina risponde con la sua solita resilienza strategica: un bel po’ di finanziamenti statali e una narrazione patriottica. L’ultima mossa arriva da Biren Technology, uno dei principali contendenti cinesi nel settore dei chip AI, che ha appena incassato un nuovo round di finanziamenti guidato da un fondo statale di Shanghai. Il messaggio è chiaro: se Washington chiude le porte, Pechino costruisce i suoi grattacieli.
Con una valutazione da 2,2 miliardi di dollari secondo la Hurun Global Unicorn List del 2024, Biren sta accelerando la sua corsa verso un’IPO nel mercato interno, proprio mentre il governo cinese spinge per l’autosufficienza tecnologica. A mettere i soldi questa volta è stato il Shanghai State-owned Capital Investment (SSCI), attraverso il suo veicolo di private equity. Per chi non conoscesse il codice tra le righe, significa che lo Stato sta apertamente pompando denaro nelle sue aziende per contrastare il blocco occidentale.
Claude Code, lo strumento di coding basato su intelligenza artificiale rilasciato da Anthropic. In un solo weekend, ha visto settimane di lavoro ridursi a poche ore, come se il tempo si fosse contratto attorno a me. Non scrivevo codice, lo evocavo.
Questo è il concetto alla base del vibe coding, un termine entrato di recente nel lessico tecnologico grazie a Andrej Karpathy, ex dirigente di OpenAI e Tesla. Il 2 febbraio ha twittato di “un nuovo tipo di coding che chiamo ‘vibe coding’, dove ti abbandoni completamente alle vibrazioni, abbracciando l’esponenzialità dell’AI e dimenticandoti che il codice esista.”

Cosa fare quando si scopre di essere vittime di Click Fraud
Hai scoperto di essere vittima di click fraud. Come si procede ora?
La prima cosa da fare, ovviamente, è cercare di escludere il traffico malevolo.
Ma ogni cosa ha un inizio, e per mitigare gli attacchi di click fraud abbiamo due cose che fanno capire dove iniziare: l’acquisto di annunci, la pubblicazione di annunci.
Microsoft sta rivoluzionando il classico Notepad con l’introduzione di una funzione di riassunto basata sull’intelligenza artificiale. Nell’ultimo aggiornamento per gli utenti Windows Insider nei canali Canary e Dev, sarà possibile generare un riassunto del testo direttamente all’interno di Notepad semplicemente selezionandolo, facendo clic con il tasto destro e scegliendo l’opzione Summarize.
Oltre all’accesso via menu contestuale, gli utenti potranno attivare i riassunti AI con la scorciatoia Ctrl + M o utilizzando il comando dal menu Copilot. Notepad offrirà anche la possibilità di modificare la lunghezza del riassunto, adattandolo alle esigenze dell’utente.

DeepMind, la divisione di intelligenza artificiale di Alphabet, ha recentemente presentato due modelli avanzati di IA, Gemini Robotics e Gemini Robotics-ER, progettati per potenziare le capacità dei robot nell’interazione con l’ambiente fisico.
Questi modelli rappresentano un significativo passo avanti nella creazione di macchine in grado di comprendere e agire in contesti complessi, avvicinandosi sempre più al concetto di robotica generale. Gemini Robotics, evoluzione del modello linguistico Gemini 2.0, integra visione, linguaggio e azione per consentire ai robot di adattarsi a nuove situazioni senza necessità di addestramento specifico.

Il click fraud, o furto dei click, è una tecnica fraudolenta che colpisce le campagne pubblicitarie online pay-per-click (PPC).
In parole povere è la pratica di generare click falsi su annunci online con l’obiettivo di manipolare i costi pubblicitari, esaurire il budget dei concorrenti o gonfiare i ricavi degli affiliati.
Ma come si fa a sapere se si è diventati una vittima di click fraud?

Il 16 Novembre 2021 se lo ricordano tutti come il giorno in cui si è capito quanto è manipolabile il mercato pubblicitario: è il giorno dell’arresto di Alexander Zukhov e dello stop di Methbot. Se avete letto gli articoli sul lato oscuro del marketing e sul click fraud oggi vi parlo del più grande sistema di frodi che sia mai stato creato, e debellato.

“Le reti ad alte prestazioni sono fondamentali”. Con queste parole, Börje Ekholm, Presidente e CEO di Ericsson, ha aperto il Mobile World Congress 2025 a Barcellona, lanciando una visione ambiziosa per il futuro della connettività mobile. Parlando davanti a una platea di leader dell’industria tecnologica, Ekholm ha sottolineato come l’integrazione tra reti mobili, cloud computing e intelligenza artificiale sia il pilastro su cui si reggerà la digitalizzazione globale. Ma per realizzarla, serve eccellenza in ogni dettaglio: reti programmabili, performanti e aperte agli sviluppatori per spingere l’innovazione. “Senza connettività, cloud e AI non possono scalare”, ha dichiarato, delineando un mondo in cui la rete non sarà più un semplice strumento, ma una piattaforma universale per infinite applicazioni.

Abbiamo letto nello scorso articolo “Il Lato Oscuro del Marketing” i vari sistemi di truffe che riguardano il marketing online, se non l’avete letto vi invito a farlo perché questo è in qualche modo il suo sequel, oggi ci concentriamo su quello più popolare dei lati oscuri del marketing: il Click Fraud.

I bot e i sistemi pubblicitari illegali o malevoli rappresentano una minaccia significativa per la sicurezza online e l’integrità dei sistemi pubblicitari. Ma soprattutto distruggono campagne pubblicitarie di chi lavora onestamente facendo perdere una enorme quantità di soldi. Non crediate che stiamo parlando di mosche bianche, sono tante le piccole società che abbracciano il lato oscuro del marketing con l’illusione guadagnare velocemente, e la falsa convinzione che tutto sommato non stanno facendo qualcosa di illegale.
Nell’ambito dello sviluppo di sistemi di intelligenza artificiale (IA) pronti per la produzione, le sfide legate all’integrazione di strumenti disgiunti per il tracciamento, il testing e la gestione dei dati sono ben note. Le soluzioni esistenti spesso creano silos di dati e flussi di lavoro manuali, portando i team a sprecare tempo nel debugging su piattaforme diverse e rendendo complicata la scalabilità delle valutazioni senza un supporto ingegneristico dedicato.
L’adozione di soluzioni AI basate su cloud è sempre più diffusa, ma spesso comporta costi esorbitanti e problemi di sicurezza legati all’esposizione di dati sensibili. Le infrastrutture esistenti richiedono configurazioni server complesse e vincoli con vendor specifici, mentre le soluzioni AI basate su browser faticano a garantire prestazioni adeguate per applicazioni reali. Per le aziende che puntano sulla privacy, trovare un equilibrio tra sicurezza e capacità dell’AI è una sfida costante.
WebLLM si presenta come una soluzione rivoluzionaria per superare questi ostacoli. Si tratta di un motore open-source che porta i Large Language Models (LLM) direttamente nei browser, sfruttando la potenza di WebGPU. Questo consente di eliminare la dipendenza dal cloud, ridurre i costi e garantire che i dati restino sempre all’interno del dispositivo dell’utente.
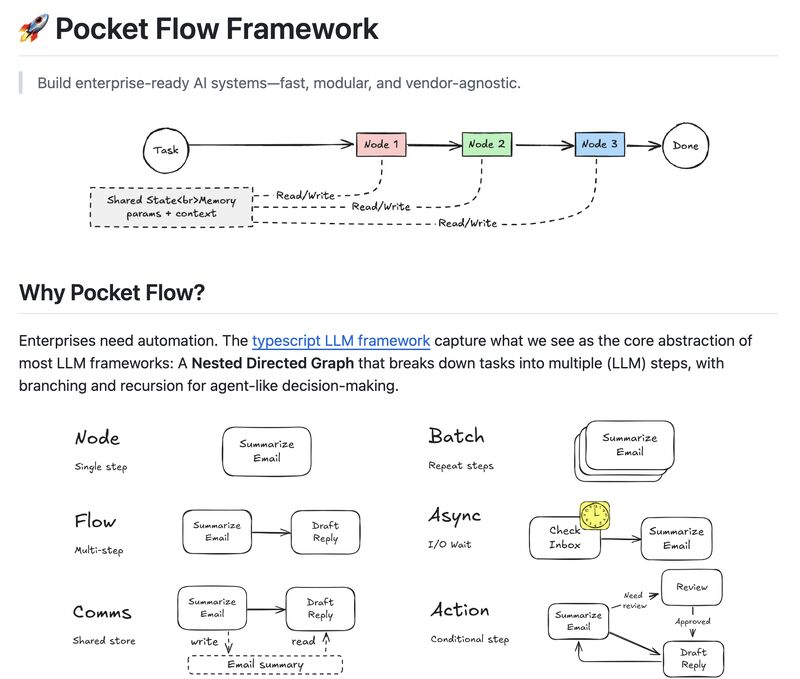
Le soluzioni esistenti impongono o tendono al vendor lock-in, mancano di modularità e rendono il debugging un incubo. Scalare workflow complessi come RAG o sistemi multi-agente diventa un groviglio di codice fragile e difficile da mantenere.
Pocket Flow è un framework open-source che organizza i sistemi AI come grafi diretti annidati, offrendo massima flessibilità nella gestione dei flussi di lavoro.
Nel panorama attuale della produttività digitale, la gestione delle informazioni personali è frammentata tra note, documenti e app diverse, costringendo i knowledge worker a sprecare ore nella ricerca di dati dispersi. I servizi cloud-based promettono efficienza, ma introducono rischi significativi per la sicurezza e la privacy. D’altra parte, i metodi tradizionali di collegamento manuale delle note risultano lenti e obsoleti.
𝗥𝗲𝗼𝗿 si propone come una soluzione innovativa per la gestione delle informazioni personali, eliminando la dipendenza dal cloud e offrendo un’intelligenza artificiale locale capace di organizzare, collegare e rendere accessibili le informazioni in modo semantico. Questa applicazione open-source è progettata per rispondere a domande, creare connessioni tra idee e garantire una ricerca efficiente senza compromettere la sicurezza dei dati.
Google ha recentemente annunciato il lancio globale di Gemini code assist per sviluppatori, una versione gratuita del suo strumento di codifica assistita dall’intelligenza artificiale, ora disponibile in anteprima pubblica. Questo strumento è progettato per supportare sviluppatori individuali, tra cui studenti, liberi professionisti, hobbisti e startup, offrendo un accesso semplificato a funzionalità avanzate di assistenza alla codifica senza la necessità di passare tra diverse risorse.
Una caratteristica distintiva di Gemini code assist è la sua generosa offerta di completamenti di codice: fino a 180.000 al mese, un numero significativamente superiore rispetto ai 2.000 completamenti mensili offerti da concorrenti come github copilot. Questo è reso possibile grazie al modello di intelligenza artificiale gemini 2.0 di google, ottimizzato per la codifica, che supporta una vasta gamma di linguaggi di programmazione e fornisce assistenza tramite un’interfaccia chatbot.
Negli ultimi anni, molte aziende hanno sprecato mesi di sviluppo cercando di costruire agenti AI destinati a fallire in produzione. I framework esistenti costringono i team a integrare strumenti fragili, personalizzare pipeline RAG difficili da scalare e affrontare sfide di manutenzione continue. La valutazione delle prestazioni viene spesso trattata come un ripensamento, complicando ulteriormente il rilascio di modelli affidabili.
Mastra si propone come la soluzione definitiva a questi problemi: un framework open-source in TypeScript che permette di creare e distribuire agenti AI in modo rapido e scalabile. Integrando nativamente agenti con strumenti, workflow dinamici, retrieval-augmented generation (RAG) e un framework di valutazione avanzato, Mastra consente alle aziende di passare dall’idea alla produzione in pochi giorni, invece che in mesi.
Lo sviluppo di intelligenza artificiale è spesso un viaggio complesso, intrappolato tra modelli opachi e pipeline fragili. Gli strumenti esistenti tendono a sacrificare la trasparenza per l’automazione o a sommergere gli sviluppatori in un mare di complessità. Le soluzioni basate su cloud, seppur potenti, espongono i dati a potenziali violazioni di sicurezza, mentre framework troppo rigidi limitano la creatività. E quando si tratta di scalare sistemi multi-agente, il debugging diventa un incubo senza fine.
Entra in scena Marvin, un framework open-source in Python progettato per rivoluzionare il modo in cui costruiamo flussi di lavoro AI agentici, garantendo risultati type-safe e un controllo granulare senza precedenti. Questa innovativa piattaforma offre un’alternativa trasparente e potente agli strumenti convenzionali, mettendo al centro dello sviluppo la creatività e l’efficienza.
Nel panorama in rapida evoluzione dell’intelligenza artificiale, OpenAI ha recentemente svelato una strategia innovativa per ottimizzare le interazioni con i suoi modelli di ragionamento avanzati della serie o. Contrariamente all’approccio tradizionale che prevedeva istruzioni dettagliate e complesse, l’azienda ha scoperto che l’uso di prompt diretti e concisi migliora significativamente le risposte dell’IA.
La riga di comando è sempre stata un potente strumento nelle mani degli sviluppatori, ma anche una fonte di inefficienza, errori sintattici e continue ricerche su Stack Overflow. Il problema? Il linguaggio delle shell è distante dal linguaggio umano e richiede una conoscenza approfondita dei comandi e delle loro opzioni.
AI Shell introduce un cambio di paradigma. Questo progetto open-source consente di tradurre comandi in linguaggio naturale in istruzioni precise per il terminale, grazie all’integrazione con i modelli OpenAI. Con un’interfaccia interattiva, AI Shell permette agli sviluppatori di lavorare più velocemente, riducendo il tempo sprecato su errori di sintassi e ricerche obsolete.

Il concetto di “Private AI” sta guadagnando rapidamente attenzione tra coloro che cercano di bilanciare le potenzialità delle tecnologie di intelligenza artificiale con la necessità di proteggere i propri dati sensibili. Si tratta di un approccio che mira a garantire che l’elaborazione dei dati avvenga senza compromettere la privacy, mantenendo il pieno controllo sui dati stessi. In altre parole, si concentra sull’utilizzo di modelli di AI che operano localmente sui dispositivi dell’utente, piuttosto che fare affidamento su server remoti, come è tipico nei “tradizionali modelli” di intelligenza artificiale basati su cloud.
Nel panorama tecnologico in continua evoluzione, molti si pongono la domanda: “Perché abbiamo ancora bisogno degli ingegneri se abbiamo l’intelligenza artificiale?” Una domanda legittima, considerando i rapidi progressi dell’IA e la sua applicazione in vari campi. Tuttavia, mentre l’IA ha fatto significativi progressi nell’assistenza alla scrittura di codice, lo sviluppo software va ben oltre il semplice scrivere righe di codice o generare script. Il ruolo degli ingegneri non si limita a produrre codice, ma implica anche la comprensione delle esigenze, la progettazione dell’architettura, l’ottimizzazione delle prestazioni e la garanzia che il software soddisfi gli obiettivi aziendali.

L’automazione delle attività sul browser ha sempre rappresentato una sfida per gli sviluppatori. Ore spese a scrivere script fragili, a inseguire bug sfuggenti e a fare i conti con interfacce utente in continua evoluzione sono solo alcune delle problematiche affrontate quotidianamente. Gli strumenti esistenti, sebbene potenti, richiedono spesso competenze di programmazione avanzate e diventano rapidamente obsoleti al primo cambiamento nell’interfaccia grafica. Inoltre, le soluzioni basate su cloud pongono rischi di sicurezza, mettendo potenzialmente in pericolo dati sensibili.

Nel mondo dello sviluppo software, gli strumenti di coding assistito basati su AI stanno rapidamente diventando indispensabili. Tuttavia, molti sviluppatori affrontano sfide quotidiane nel bilanciare l’uso di questi assistenti con il loro codice locale. Le soluzioni attuali spesso richiedono il copia-incolla di frammenti di codice, portando alla perdita di contesto e rendendo difficile lavorare su progetti multi-file. Inoltre, l’assenza di integrazione con la cronologia git e i potenziali rischi di sicurezza associati al caricamento di codice proprietario su piattaforme cloud costituiscono ostacoli significativi.

La gestione di carichi di lavoro AI e batch su infrastrutture ibride—tra cloud e on-prem—è un compito complesso, costoso e spesso frustrante. Il rischio di lock-in con vendor specifici, l’overhead della gestione manuale e i costi elevati delle GPU inattive rappresentano sfide significative per aziende e sviluppatori.
SkyPilot è una soluzione open-source che rivoluziona questo panorama, offrendo un’unica interfaccia per eseguire workload AI e batch su Kubernetes e oltre 12 cloud provider, eliminando il lock-in e riducendo significativamente i costi operativi.

Presearch ha lanciato PreGPT 2.0, un nuovo capitolo nella sfida alle Big Tech nel settore dell’AI conversazionale. Con un’infrastruttura decentralizzata, questo aggiornamento punta a ridefinire il concetto di chatbot, offrendo modelli linguistici avanzati e una maggiore varietà di soluzioni AI open-source.
La novità più rilevante è il superamento del tradizionale approccio centralizzato: invece di operare da data center monolitici, PreGPT 2.0 sfrutta una rete distribuita di computer indipendenti. Secondo Brenden Tacon, innovation and operations lead di Presearch, questa architettura consente al chatbot di operare senza le restrizioni tipiche delle AI mainstream, spezzando il meccanismo degli algoritmi che alimentano il conformismo digitale.
Lobe Chat si distingue come una piattaforma AI self-hosted che offre un’alternativa scalabile, modulare e sicura ai chatbot tradizionali. La sua architettura è progettata per garantire interoperabilità con diversi provider AI, privacy dei dati e un’integrazione fluida con le infrastrutture esistenti.
Architettura Modulare e Plugin Ecosystem Lobe Chat adotta un’architettura modulare basata su un ecosistema di plugin, permettendo agli utenti di estendere le funzionalità senza modificare il core system. Ogni plugin opera come un microservizio, facilitando l’aggiunta di nuove capacità come ricerca web, generazione di immagini, elaborazione del codice e flussi di lavoro personalizzati.
Il panorama dell’intelligenza artificiale è frammentato e caotico, con aziende e sviluppatori che faticano a gestire tool diversi, costi poco chiari e problemi di privacy. I modelli SaaS impongono vincoli ai vendor, mentre l’uso di API cloud apre scenari di rischio per la sicurezza dei dati. La scalabilità è un enigma complesso e l’integrazione di modelli multimodali è spesso un incubo per gli sviluppatori.
𝗔𝗻𝘆𝘁𝗵𝗶𝗻𝗴𝗟𝗟𝗠 si propone come la soluzione definitiva a questi problemi, offrendo un ambiente AI self-hosted, con Retrieval-Augmented Generation (RAG), agenti AI e controllo granulare delle operazioni. Si tratta di una piattaforma open-source che combina potenza, flessibilità e trasparenza.
Le sue caratteristiche distintive comprendono un hub per modelli multi-LLM, un sistema di RAG che consente di interagire con documenti e siti web mantenendo il controllo dei dati, e agenti AI avanzati capaci di navigare il web, eseguire codice e orchestrare workflow personalizzati.
La sua flessibilità è evidente nelle opzioni di deployment: può essere eseguito localmente su desktop o scalato tramite Docker e Kubernetes. A livello enterprise, offre gestione utenti avanzata, audit log e politiche di accesso dettagliate. Un altro vantaggio competitivo è la trasparenza dei costi, eliminando i sovrapprezzi sulle query AI e le fee per utente tipiche dei servizi SaaS.
La community open-source di 𝗔𝗻𝘆𝘁𝗵𝗶𝗻𝗴𝗟𝗟𝗠 è in forte crescita, con oltre 3.000 stelle su GitHub e un ecosistema in espansione. Gli sviluppatori trovano strumenti robusti, API complete, widget web e un’estensione browser preconfigurata. Inoltre, offre una soluzione all-in-one per sostituire molteplici strumenti, consolidando chatbot, analisi documentale e automazione in un’unica piattaforma.
L’approccio orientato alla sovranità dei dati è un altro elemento chiave: l’hosting può avvenire su database locali come LanceDB, Chroma o Pinecone, garantendo totale indipendenza dal cloud.
𝗔𝗻𝘆𝘁𝗵𝗶𝗻𝗴𝗟𝗟𝗠 non è solo un framework AI, ma un cambio di paradigma per chi cerca potenza, privacy e controllo senza compromessi.
Repository: https://github.com/Mintplex-Labs/anything-llm
Website: https://anythingllm.com/
Oggi, più che mai, l’estrazione di informazioni utilizzabili da documenti non strutturati rappresenta una delle principali sfide per numerosi team aziendali. L’adozione di strumenti tradizionali, purtroppo, non ha risolto il problema: questi strumenti, da un lato, non riescono a gestire con precisione layout complessi, e dall’altro, obbligano gli utenti a caricare i documenti su piattaforme cloud, mettendo così a rischio la privacy dei dati. Inoltre, l’uso di modelli predefiniti spesso non si adatta alle reali esigenze quotidiane, costringendo i team a una gestione manuale che rallenta e appesantisce la produttività.
Se anche tu, come molti, ti senti sopraffatto dalla quantità di documenti da gestire, sarà familiare il senso di frustrazione nel constatare che conoscenze preziose sono sepolte sotto una montagna di dati difficili da accedere. La buona notizia è che esiste una soluzione che può finalmente fare la differenza: Documind.
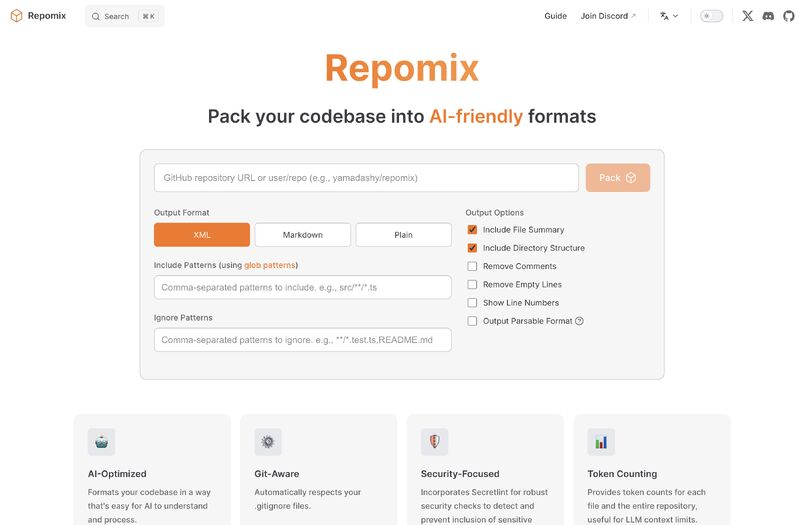
Sembra un’idea innovativa per ottimizzare il lavoro degli sviluppatori con l’AI. Repomix affronta il problema reale della gestione del contesto nei progetti software, evitando la frammentazione del codice e garantendo la sicurezza dei repository privati.
L’approccio di creare un unico file AI-ready, ottimizzato per i modelli linguistici, risolve il problema della perdita di informazioni e semplifica l’integrazione con strumenti come ChatGPT e Claude. Il supporto a formati specifici, il conteggio dei token e l’automazione nella gestione di repository remoti sono caratteristiche chiave che potrebbero ridurre drasticamente il tempo speso dagli sviluppatori a organizzare il codice per l’AI.

Nel panorama in rapida evoluzione delle applicazioni AI, uno degli aspetti più sfidanti è la transizione da un prototipo a una soluzione di produzione scalabile. Se è facile sviluppare flussi di lavoro documentali alimentati da intelligenza artificiale all’interno di notebook, il vero ostacolo emerge quando si tratta di gestire la complessità del mondo reale. Le soluzioni esistenti spesso non forniscono la modularità necessaria per passare facilmente dalla fase di prototipazione alla produzione, richiedendo in molti casi di ricostruire tutto da zero per ambienti reali. Inoltre, la crescente dipendenza dal cloud crea non pochi rischi per la privacy, mentre le architetture rigide limitano la possibilità di personalizzazione. Infine, senza gli strumenti giusti, il debug dei sistemi RAG (Retrieval-Augmented Generation) diventa un vero e proprio incubo.
Ma ora, con Cognita, una nuova piattaforma open-source per il framework RAG, si apre una strada alternativa che rende possibile superare questi limiti, colmando il divario tra il prototipo e la produzione.

La memoria umana è la colonna portante della nostra identità. È quel misto di ricordi imbarazzanti, momenti epici e dettagli irrilevanti che ci permette di dire “io sono questo.” Ma è anche un sistema ingannevole, un archivio disorganizzato e pieno di falle. Ora immaginate di prendere questa meravigliosa confusione e cercare di replicarla in un’intelligenza artificiale. Sembra una buona idea? Certo, come lanciare un boomerang in uno spazio angusto e sperare che non ritorni per colpirti.
La memoria a lungo termine (LTM) e la memoria a breve termine (STM) non sono solo concetti accademici da manuale di psicologia. Sono i due poli su cui si basa ogni processo cognitivo umano. La STM è quella lavagna temporanea su cui scriviamo le informazioni per risolvere problemi immediati: ricordare il numero di una stanza d’hotel, fare calcoli mentali, trovare un modo elegante per uscire da una conversazione noiosa. La LTM, invece, è il magazzino delle nostre esperienze, il contenitore che ci permette di ricordare la lezione di geometria del liceo (anche se ormai non ci serve più) o il nome del nostro primo amore.
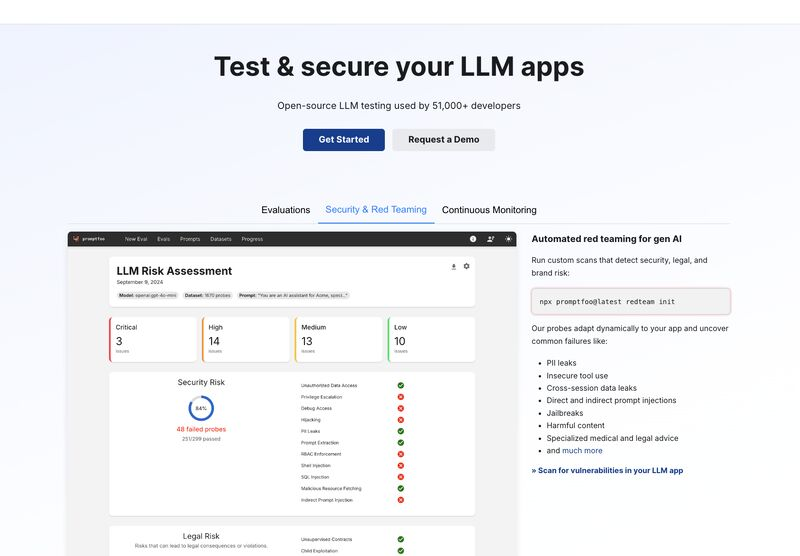
L’utilizzo di modelli di linguaggio di grandi dimensioni (LLM) ha trasformato numerosi settori, dall’automazione industriale alla generazione di contenuti personalizzati. Tuttavia, man mano che queste tecnologie avanzano, aumenta anche la complessità di garantire la loro sicurezza, performance e affidabilità. Le sfide si moltiplicano quando si cerca di testare e ottimizzare i prompt in un contesto operativo reale, dove ogni vulnerabilità potrebbe tradursi in falle di sicurezza o inefficienze critiche.
Il panorama attuale degli strumenti per il testing delle LLM non riesce spesso a soddisfare le esigenze delle aziende: configurazioni macchinose, funzionalità limitate e mancanza di integrazione con flussi CI/CD (Continuous Integration/Continuous Deployment) moderni rappresentano ostacoli significativi.
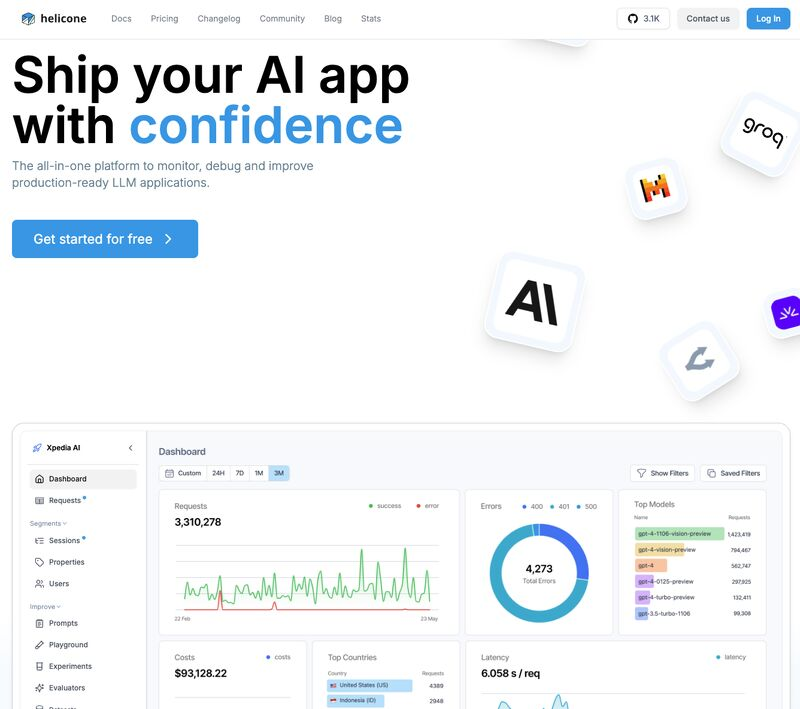
Nel mondo dell’intelligenza artificiale, la gestione e l’ottimizzazione dei modelli linguistici di grandi dimensioni (LLM) è diventata un aspetto cruciale per il successo delle applicazioni basate su IA. Sebbene i modelli LLM alimentino una vasta gamma di applicazioni, il monitoraggio delle loro performance, dei costi e dei comportamenti rimane una sfida significativa. Gli strumenti di osservabilità esistenti spesso non forniscono approfondimenti completi, rendendo difficile la risoluzione dei problemi e il miglioramento continuo. Inoltre, il mantenimento della privacy dei dati e la conformità alle normative aumentano ulteriormente la complessità di queste operazioni.
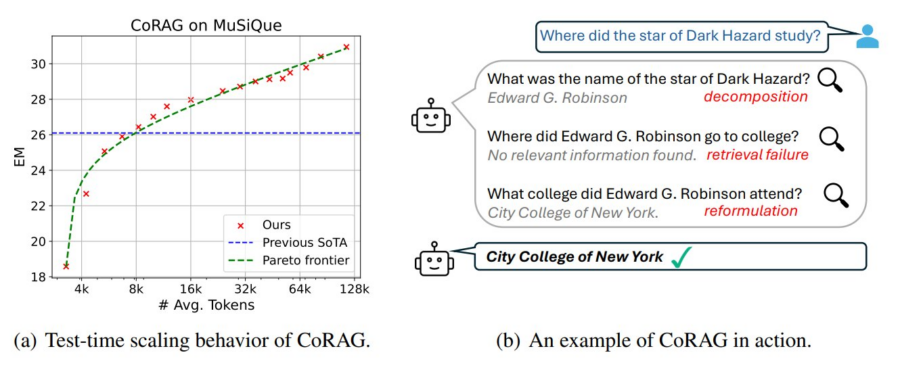
La generazione aumentata dal recupero delle informazioni (Retrieval-Augmented Generation, RAG) si evolve con l’introduzione del Chain-of-Retrieval Augmented Generation (CoRAG), che combina il potere del recupero iterativo con modelli di ragionamento Chain-of-Thought (CoT). Questo approccio consente di affrontare domande complesse suddividendo il processo in passaggi successivi, recuperando informazioni rilevanti e ragionando su di esse prima di generare una risposta finale.
Cos’è il CoRAG?
Il CoRAG migliora il tradizionale RAG integrando un ragionamento passo-passo, emulando il modo in cui un essere umano affronta domande a più livelli (multi-hop). Questo approccio si rivela cruciale in contesti dove una semplice pipeline “query-risposta” non è sufficiente, come nei task di domande complesse o nei problemi che richiedono più passaggi logici per essere risolti.