Il Bootcamp LLM di Full Stack Deep Learning è un corso intensivo, accessibile gratuitamente su YouTube, che ti guida nella creazione di applicazioni basate su modelli linguistici di grandi dimensioni, come GPT-4.
L’obiettivo del Bootcamp è fornirti una conoscenza completa e aggiornata sulla creazione e distribuzione di applicazioni basate su LLM (Large Language Models).
In un’era in cui la tecnologia ha rivoluzionato il modo in cui interagiamo gli uni con gli altri, il concetto di “mind network” è diventato sempre più rilevante. Questa innovativa idea prevede un sistema interconnesso a livello globale in cui gli individui possono condividere e scambiare pensieri, emozioni ed esperienze in modo fluido, superando barriere geografiche e linguistiche.
In questo articolo esploreremo il concetto di mind network, i suoi potenziali benefici e gli avanzamenti tecnologici che lo stanno rendendo una realtà.
Text to Sound è qui. Il più recente modello Audio AI può generare effetti sonori, brevi tracce strumentali, paesaggi sonori e una vasta gamma di voci di personaggi, tutto da un prompt di testo.
Perplexity AI ha rivoluzionato il modo in cui scopriamo e condividiamo informazioni. Questa innovativa piattaforma non solo risponde alle domande, ma dà agli utenti il potere di esplorare gli argomenti in profondità, riassumere i contenuti e persino creare articoli lunghi. In questo articolo, approfondiremo le funzionalità e le capacità di Perplexity page, evidenziando il suo potenziale per trasformare il modo in cui interagiamo con la conoscenza.
Anthropic ha lanciato una nuova funzionalità per il suo assistente AI, Claude, nota come “Tool Use” o “function call” disponibile su tutta la famiglia di modelli Claude 3 su Anthropic Messages API, Amazon Bedrock e Google Cloud’s Vertex AI.
Ora Claude può svolgere compiti, manipolare dati e fornire risposte più dinamiche e accurate.
Il costo si basa sul volume di testo elaborato, con 1.000 token equivalenti a circa 750 parole. L’opzione Haiku costa circa 25 centesimi per milione di token di input e 1,25 dollari per milione di token di output.
Man mano che il campo dell’analisi finanziaria continua a evolversi, l’integrazione di modelli linguistici avanzati nel toolkit dei professionisti e dei ricercatori finanziari potrebbe portare a progressi significativi nella nostra comprensione delle prestazioni aziendali e dei driver dei rendimenti del mercato azionario.
Wav-KAN rappresenta un avanzamento significativo nel disegno di reti neurali interpretabili. La sua capacità di gestire dati ad alta dimensione e fornire spiegazioni chiare sul comportamento del modello la rende una strumento promettente per una vasta gamma di applicazioni, dalle ricerche scientifiche all’implementazione industriale.
Stanford University ha recentemente lanciato l’Indice di Transparenza dei Modelli Fondamentali, un’iniziativa volta a valutare la trasparenza di 10 aziende che sviluppano modelli fondamentali, come GPT-4 e Llama 3.
Installare l’intelligenza artificiale localmente potrebbe essere semplice come fare clic su un pulsante? Sì, dicono i creatori di Pinokio, un nuovo strumento facile da usare che sta facendo scalpore nella comunità AI open source.
Nel campo dell’intelligenza artificiale, il fine-tuning di modelli come Mistral 7B è cruciale, specialmente per lingue non inglesi come l’italiano. Il dataset Alpaca (ITA) dimostra come i dati specifici possano adattare un modello alle particolarità di una lingua.
Mistral, ha silenziosamente rilasciato un significativo aggiornamento al suo modello LLM (Large Language Model).
Questo nuovo modello, Mistral 7B v0.3, non è censurato per impostazione predefinita e introduce numerosi miglioramenti rilevanti. Senza nemmeno un tweet o un post sul blog, il laboratorio francese di ricerca sull’intelligenza artificiale ha reso disponibile il modello sulla piattaforma HuggingFace. Come il suo predecessore, potrebbe rapidamente diventare la base per strumenti IA innovativi sviluppati da terze parti.
Il 21 maggio 2024, Anthropicha annunciatoun avanzamento significativo nella comprensione del funzionamento interno dei modelli di intelligenza artificiale (IA). La ricerca si è concentrata su Claude Sonnet, uno dei modelli di linguaggio di grandi dimensioni attualmente in uso. Questo studio rappresenta il primo sguardo dettagliato all’interno di un modello di linguaggio moderno e di grado produttivo, con potenziali implicazioni per la sicurezza e l’affidabilità dei modelli di IA.
Negli ultimi anni è nata la necessità di dover garantire che i sistemi basati sull’Intelligenza Artificiale siano in grado di evitare in maniera efficace eventuali comportamenti dannosi o pericolosi, soprattutto quando si parla di sistemi dotati di alta autonomia oppure per quelli impiegati in contesti critici.
Secondo quanto riferito dal Wall Street Journal ., la FDA ha dato il via libera a Neuralink di Elon Musk per procedere con l’impianto del suo sistema di chip cerebrale in un secondo paziente.
In un’epoca in cui l’intelligenza artificiale sta rapidamente trasformando il modo in cui interaghiamo con la tecnologia, la Catholic Answers ha introdotto un’iniziativa innovativa: Justin.AI, un modello 3D supportato dall’IA per fornire risposte alle domande sulla fede cattolica.
Lanciato il 25 aprile 2024, Justin.AI ha suscitato un grande interesse nella comunità cattolica e non solo. Molti si sono affrettati a provare questo nuovo strumento, curiosi di vedere come un’intelligenza artificiale potrebbe affrontare questioni di fede complesse e delicate.
La privacy è una questione cruciale nell’era dell’intelligenza artificiale onnipresente. Scopri come puoi gestire meglio le tue informazioni personali.
È facile pensare che usare strumenti di intelligenza artificiale significhi interagire con una macchina neutrale e indipendente. Tuttavia, tra cookie, identificatori di dispositivo, requisiti di accesso e account, e occasionali revisori umani, i servizi online sembrano avere un insaziabile desiderio di raccogliere i tuoi dati.
La privacy è una delle principali preoccupazioni sia per i consumatori che per i governi riguardo all’intelligenza artificiale. Le piattaforme spesso mostrano le loro funzionalità di privacy, anche se sono difficili da trovare.
I piani aziendali e a pagamento generalmente escludono la formazione sui dati inviati. Ma ogni volta che un chatbot “ricorda” qualcosa, può sembrare invasivo.
In questo articolo, spiegheremo come migliorare le impostazioni sulla privacy dell’IA eliminando le chat e le conversazioni precedenti e disattivando le impostazioni in ChatGPT, Gemini (ex Bard), Claude, Copilot e Meta AI che permettono agli sviluppatori di addestrare i loro sistemi sui tuoi dati. Queste istruzioni sono per l’interfaccia desktop basata su browser di ciascuno.
Durante la conferenza I/O della scorsa settimana, Google ha presentato una serie di promettenti prodotti di intelligenza artificiale generativa.
Tuttavia, alcuni creatori sono preoccupati che queste nuove funzionalità possano diminuire il traffico web, riducendo le visite organiche e le entrate pubblicitarie.
All’I/O 2023 Google ha lanciato Project Gameface , un “mouse” da gioco open source a mani libere che consente alle persone di controllare il cursore di un computer utilizzando il movimento della testa e i gesti facciali. Le persone possono alzare le sopracciglia per fare clic e trascinare o aprire la bocca per spostare il cursore, rendendo il gioco più accessibile.
il Videocita la collaborazione con Incluzza, società indiana che supporta persone con disabilità, insieme stanno studiando come il progetto possa essere esteso a contesti educativi e lavorativi.
Google ha presentato martedì la sesta generazione dei suoi chip con unità di elaborazione tensor, notando un significativo miglioramento rispetto alla generazione precedente. I nuovi chip, denominati Trillium, saranno disponibili per i clienti cloud entro la fine dell’anno e offrono un miglioramento delle prestazioni quasi cinque volte (4,7 volte) rispetto al TPU v5e presentato lo scorso agosto.
L’ultimo “modello di punta” di OpenAI, GPT-4o, (o sta per omnimodel) non solo è più veloce di GPT-4, ma migliora anche le sue capacità per voce, testo e immagini, ha rivelato lunedì l’organizzazione no-profit sostenuta da Microsoft. GPT-4o Input $5/1M tokens. Output $15/1M tokens.
Il nuovo modello sarà disponibile gratuitamente per tutti gli utenti. Noi l’abbiamo provato su https://chat.lmsys.org/, in quanto non disponibile per il momento in italia se non con VPN. Questo modello è 2 volte più veloce e il 50% più economico del turbo GPT-4.
“Questa è la prima volta che facciamo un grande passo avanti in termini di facilità d’uso,” durante un live streaming lunedì. “La nostra missione è garantire a tutti i nostri strumenti avanzati di intelligenza artificiale.”
IBM ha recentemente scosso il mondo dell’intelligenza artificiale e dello sviluppo software rilasciando otto nuovi modelli di linguaggio di grandi dimensioni (LLM) specializzati nella generazione di codice. Questi modelli, disponibili in modalità base o istruzione, sono addestrati su un vasto set di dati di 116 linguaggi di programmazione e offrono un’ampia gamma di funzionalità, tra cui:
OpenAI, l’organizzazione di ricerca sull’intelligenza artificiale fondata da Elon Musk e Sam Altman, ha recentemente introdotto un nuovo standard chiamato “Model Spec” per documentare in modo chiaro e trasparente i modelli di AI. In un blog post intitolato “Introducing the Model Spec“, OpenAI delinea le motivazioni e i dettagli di questo nuovo framework, che mira a promuovere una maggiore comprensione e responsabilità nello sviluppo e nell’implementazione dei sistemi di AI.
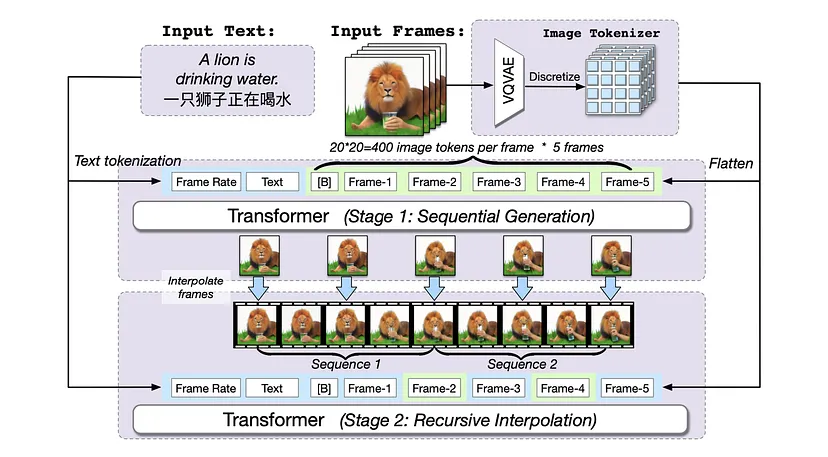
Mentre i recenti generatori di immagini da testo come Google’s Imagen e OpenAI’s DALL-E hanno attirato molta attenzione, i ricercatori della Tsinghua University e della BAAI intendono fare un passo avanti proponendo un generatore di video da testo, chiamato CogVideo, che si dice sia in grado di superare di gran lunga tutti i modelli pubblicamente disponibili nelle valutazioni di macchina e umane. Diamo un’occhiata ad alcune demo qui sotto.
Il prompt engineering, o progettazione dei prompt, ha conquistato il mondo dell’IA generativa. Questo lavoro, consiste nell’ottimizzare l’input testuale per comunicare efficacemente con modelli linguistici di grandi dimensioni.
Il prompt engineering, in un mondo sempre più avvolto dall’ombra dell’intelligenza artificiale, è diventato un ponte cruciale tra l’ingegneria linguistica e l’autonomia creativa delle macchine. Questa disciplina, che si preoccupa di fornire input testuali mirati e ben strutturati alle IA, è stata vista come una chiave per sfruttare al massimo il loro potenziale. Tuttavia, come ogni fenomeno emergente nel vasto universo della tecnologia, il suo ruolo potrebbe subire profonde trasformazioni nel tempo.
Perplexity sta collaborando con SoundHound AI, leader globale nell’intelligenza artificiale vocale.
SoundHound Chat AI si è distinto come il pioniere degli assistenti vocali, essendo il primo a integrare tecnologie di intelligenza artificiale generativa. Inoltre, ha segnato la storia entrando per primo in produzione nell’ambito automobilistico. Grazie alla collaborazione con Stellantis, SoundHound Chat AI è attualmente operativo in oltre 12 paesi e disponibile in 18 lingue diverse.
Il gruppo di ricerca di Stanford sta sviluppando una tecnologia di imaging olografico assistito dall’intelligenza artificiale che promette di essere più sottile, leggera e di qualità superiore rispetto a qualsiasi cosa i ricercatori abbiano mai visto. Questa innovazione potrebbe portare i visori per realtà aumentata al livello successivo, superando le limitazioni dei dispositivi attuali.
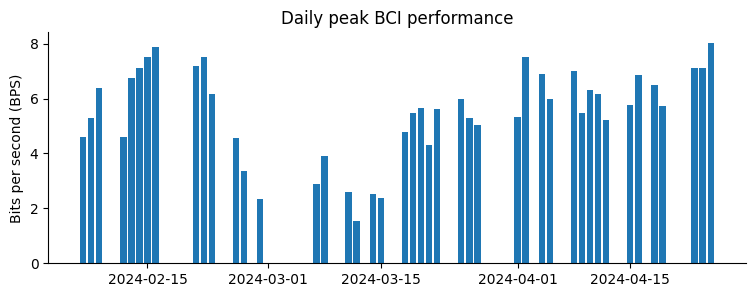
Neuralink, l’innovativa azienda di neurotecnologia guidata da Elon Musk, ha recentemente divulgato che il proprio sistema di interfaccia cervello-computer (BCI) ha presentato malfunzionamenti alcune settimane dopo l’impianto in Noland Arbaugh, un giovane di 29 anni coinvolto in un grave incidente.
All’inizio dell’anno, nell’ambito dello studio PRIME autorizzato dalla FDA, Arbaugh ha ricevuto il dispositivo sperimentale, progettato per consentire a persone con disturbi neurologici di manovrare dispositivi elettronici mediante il pensiero.
Tuttavia, mercoledì la compagnia ha comunicato che alcuni elettrodi dell’impianto di Arbaugh sono usciti dalla loro posizione originaria poche settimane dopo l’operazione.
Questo problema ha causato un calo nel bit rate per secondo, una metrica fondamentale per valutare la performance della BCI secondo gli standard di Neuralink. La società ha poi adottato misure correttive, incluse ottimizzazioni dell’algoritmo di registrazione, che hanno portato a un netto e costante miglioramento della metrica, ora superiori ai risultati iniziali ottenuti da Arbaugh.
In futuro intendiamo estendere le funzionalità del Link al mondo fisico per consentire il controllo di bracci robotici, sedie a rotelle e altre tecnologie che potrebbero aiutare ad aumentare l’indipendenza delle persone che vivono con la tetraplegia.
Elon Musk, noto per essere alla guida di Tesla e SpaceX, ha espresso il suo entusiasmo per i progressi di Arbaugh lo scorso marzo, in seguito alla pubblicazione sui progressi fatti dal paziente, paralizzato dalla spalle in giù dopo un incidente nel 2016, che ha sperimentato per la prima volta il dispositivo attraverso la piattaforma X.
L’intelligenza artificiale (IA) sta trasformando il posto di lavoro, portando sia opportunità che sfide che richiedono una considerazione attenta. Secondo l’Organizzazione per la cooperazione e lo sviluppo economico (OECD), l’IA può portare benefici significativi sul posto di lavoro, con quattro lavoratori su cinque che dicono che l’IA ha migliorato la loro prestazione al lavoro e tre su cinque che dicono che l’IA ha aumentato il loro piacere del lavoro. Tuttavia, l’adozione dell’IA sul posto di lavoro viene anche accompagnata da rischi che devono essere affrontati.
Elon Musk ci ha presentato una nuova dimostrazione del Tesla bot, mostrando esattamente di cosa è capace il robot. Questa è una sorpresa piuttosto grande, considerando che questa è una delle prime dimostrazioni dal 15 gennaio, quando abbiamo visto il Tesla bot piegare una camicia. In questa dimostrazione è effettivamente piuttosto affascinante, perché possiamo vedere il Tesla bot fare molte cose diverse.
Un recente studio da HAI Stanford Universityha rivelato che i grandi modelli linguistici utilizzati ampiamente per le valutazioni mediche non riescono a supportare adeguatamente le loro affermazioni.
DrEureka: Trasferimento Sim-To-Real Guidato da Modelli di Linguaggio
DrEureka rappresenta un’innovativa applicazione del concetto di trasferimento Sim-To-Real guidato da modelli di linguaggio, sviluppata da un team di ricercatori provenienti da diverse istituzioni accademiche di spicco. Tra i membri chiave di questo team troviamo Jason Ma e William Liang dell’Università di Pennsylvania, Hungju Wang, Sam Wang, Osbert Bastani e Dinesh Jayaraman, tutti coinvolti nello sviluppo e nell’implementazione di DrEureka.
Collaborazione e Contributi
La collaborazione interistituzionale è stata un elemento fondamentale per il successo di DrEureka. Oltre all’Università di Pennsylvania, il team includeva anche ricercatori di NVIDIA e dell’Università del Texas ad Austin, tra cui Yuke Zhu e Linxi “Jim” Fan. L’uguale contributo di Jason Ma e William Liang sottolinea l’importanza della collaborazione e della condivisione di conoscenze in progetti di ricerca complessi come questo.
Obiettivi e Metodologia
DrEureka si propone di superare le sfide del trasferimento Sim-To-Real attraverso l’utilizzo di modelli di linguaggio avanzati. Il team ha adottato un approccio innovativo che combina la potenza dei modelli di linguaggio con la precisione e la versatilità dei sistemi di controllo robotico.
DrEureka rappresenta un passo avanti significativo nel campo del trasferimento Sim-To-Real guidato da modelli di linguaggio. Grazie alla collaborazione interdisciplinare e all’approccio innovativo adottato dal team di ricerca, questo progetto promette di aprire nuove prospettive nel mondo dell’IA e della robotica.
Trasferimento Sim-To-Real Guidato da Modelli di Linguaggio
L’avvento dell’intelligenza artificiale (IA) ha rivoluzionato il modo in cui affrontiamo le sfide del mondo reale. Uno degli ambiti più affascinanti di questa tecnologia è il trasferimento Sim-To-Real, ovvero la capacità di trasferire le conoscenze acquisite in ambienti di simulazione al mondo fisico. Questo processo è fondamentale per l’applicazione pratica di molte soluzioni IA, come la robotica, l’automazione industriale e la guida autonoma.
Sfide del Trasferimento Sim-To-Real
Il trasferimento Sim-To-Real non è privo di sfide. Gli ambienti di simulazione, per quanto realistici, non possono replicare perfettamente la complessità e l’imprevedibilità del mondo reale. Differenze sottili, come la frizione, la dinamica dei fluidi o le interazioni con gli oggetti, possono avere un impatto significativo sulle prestazioni di un sistema IA quando viene implementato nel mondo fisico.
Inoltre, la raccolta di dati del mondo reale può essere onerosa e difficile, rendendo la creazione di modelli accurati una sfida. Questo è particolarmente vero in scenari pericolosi o inaccessibili, come la robotica spaziale o la chirurgia robotica.
Il Ruolo dei Modelli di Linguaggio
È qui che i modelli di linguaggio, come il famoso GPT-3, entrano in gioco. Questi modelli di IA, addestrati su vasti corpora di testi, hanno dimostrato una straordinaria capacità di comprendere e generare linguaggio naturale. Ma il loro potenziale va ben oltre la semplice elaborazione del linguaggio.
Recenti ricerche hanno dimostrato che i modelli di linguaggio possono essere utilizzati per guidare il trasferimento Sim-To-Real, colmando il divario tra le simulazioni e il mondo reale. Attraverso l’apprendimento di rappresentazioni astratte e la capacità di generalizzare, questi modelli possono aiutare a creare sistemi IA più robusti e adattabili.
Maxime Labonne, un ricercatore di intelligenza artificiale, ha creato un nuovo modello di linguaggio di grandi dimensioni chiamato Meta-Llama-3-120B-Instruct. Questo modello è stato ottenuto fondendo più istanze del precedente modello Meta-Llama-3-70B-Instruct utilizzando uno strumento chiamato MergeKit.
Il processo di “self-merge”
Questa tecnica innovativa, chiamata “self-merge”, permette di scalare il modello da 70 miliardi a 120 miliardi di parametri. Labonne ha strutturato il processo di fusione sovrapponendo gli intervalli di strati da 0 a 80, migliorando così le capacità complessive del modello.
Ottimizzazione delle prestazioni
Labonne ha impiegato una tecnica di fusione “passthrough”, mantenendo il tipo di dati come float16 per ottimizzare le prestazioni. Questa scelta ha permesso di mantenere l’efficienza del modello nonostante l’aumento significativo della sua dimensione.
Prestazioni del modello
Il modello Meta-Llama-3-120B-Instruct si posiziona al sesto posto nella classifica della benchmark di scrittura creativa, superando il precedente modello Llama 3 70B. Tuttavia, nonostante le sue ottime prestazioni nella scrittura creativa, il modello non riesce a eguagliare le capacità di altri modelli come GPT-4 nelle attività di ragionamento.
Applicazioni
Questo nuovo modello di linguaggio è particolarmente adatto per attività di scrittura creativa. Esso utilizza il template di chat di Llama 3 con una finestra di contesto predefinita di 8K.
Ulteriori informazioni
Maxime Labonne ha dichiarato che il processo di fusione dei modelli ha richiesto un’attenta progettazione per garantire la coerenza e l’efficacia del modello risultante. Inoltre, il Meta-Llama-3-120B-Instruct è stato progettato per essere facilmente adattabile e personalizzabile per diversi compiti di elaborazione del linguaggio naturale.
Il lavoro di Maxime Labonne dimostra come l’innovazione e la sperimentazione possano portare allo sviluppo di nuovi modelli di linguaggio di grandi dimensioni, offrendo nuove opportunità e applicazioni nell’ambito dell’intelligenza artificiale.
L’articolo ‘Imagine Flash: Accelerating Emu Diffusion Models with Backward Distillation‘ discute la ricerca GenAI che supporta le ultime funzionalità di generazione di immagini in Meta AI, oltre al rilascio di Meta Llama 3.
Questa ricerca si concentra sull’accelerazione dei modelli di diffusione Emu attraverso una tecnica chiamata Backward Distillation. La Backward Distillation mira a mitigare le discrepanze tra addestramento e inferenza calibrando il modello studente sulla sua stessa traiettoria inversa. Questo approccio è fondamentale per consentire la generazione di campioni ad alta fedeltà e diversificati utilizzando un numero minimo di passaggi, tipicamente compreso tra uno e tre.
L’articolo introduce anche la Shifted Reconstruction Loss, che adatta dinamicamente il trasferimento di conoscenza in base al passo temporale corrente, e la Noise Correction, una tecnica di inferenza che migliora la qualità del campione affrontando le singolarità nella previsione del rumore.
Attraverso esperimenti approfonditi, lo studio dimostra che il loro metodo supera i concorrenti esistenti sia in metriche quantitative che in valutazioni umane, raggiungendo prestazioni paragonabili al modello insegnante con soli tre passaggi di denoising, facilitando così una generazione efficiente di alta qualità.
Sintesi :
I modelli di diffusione rappresentano un robusto framework generativo, tuttavia implicano un processo inferenziale dispendioso. Le tecniche di accelerazione correnti spesso degradano la qualità delle immagini o risultano inefficaci in scenari complessi, specie quando si limitano a pochi step di elaborazione.
Nel presente studio, META introduce un innovativo framework di distillazione ideato per la produzione di campioni vari e di alta qualità in soli uno a tre step. La metodologia si articola in tre componenti fondamentali: (i) Distillazione inversa, che riduce il divario tra fase di addestramento e inferenza attraverso la calibrazione dello studente sulla propria traiettoria inversa; (ii) Perdita di ricostruzione adattiva, che modula il trasferimento di conoscenza in funzione del tempo di passaggio specifico; e (iii) Correzione adattiva del rumore, una strategia inferenziale che raffina la qualità dei campioni intervenendo sulle anomalie nella previsione del rumore.
Mediante una serie di esperimenti approfonditi, META ha verificato che il metodo eccelle rispetto ai rivali in termini di metriche quantitative e giudizi qualitativi forniti da valutatori umani. In modo significativo, il nostro approccio raggiunge livelli di performance similari al modello originale con soli tre step di denoising, promuovendo una generazione di immagini di alta qualità e ad alta efficienza.
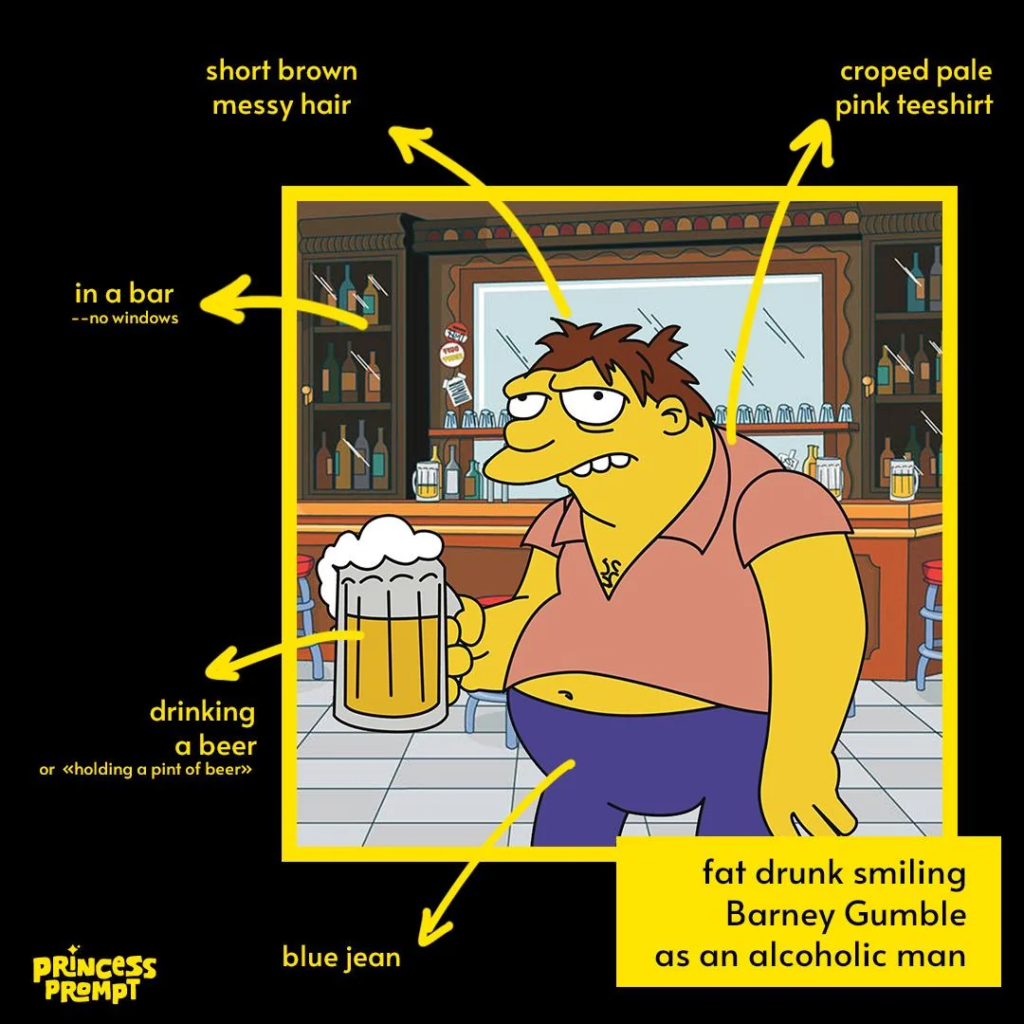
Princess Prompt , ha utilizzato la più recente tecnologia di intelligenza artificiale tra cui Midjourney v6 e un upscaler per creare versioni AI dei personaggi dei Simpsons.
Princess Prompts ha utilizzato uno screenshot per ciascuno dei personaggi che voleva ricreare, poi ha utilizzato quell’immagine come suggerimento utilizzando i parametri “peso immagine”. Successivamente, ha descritto lo screenshot a Midjourney nel modo più “preciso e conciso” possibile.
Una volta generati tutti i personaggi, li ha inviati all’intelligenza artificiale Magnific.ai per aggiungere dettagli come la struttura della pelle, i capelli, le rughe, ecc. Il risulato e’ formidabile.
Per vedere il lavoro fotografico di Milie, vai sul suo sito web e su Instagram . Per i suoi esperimenti sull’intelligenza artificiale, controlla la sua pagina Facebook.
Dimentica la fatica di creare design e seguire tutorial. Scopri questi 9 straordinari siti web basati sull’intelligenza artificiale che ti permettono di realizzare presentazioni stupefacenti in soli 60 secondi!
In un mondo frenetico dove l’efficienza e la produttività sono fondamentali, la domanda di strumenti che semplificano i compiti e risparmiano tempo non è mai stata così alta. Quando si tratta di creare presentazioni, il tradizionale processo di lavoro di design e tutorial può essere lungo e noioso. Tuttavia, con l’avanzamento dell’Intelligenza Artificiale (AI), generare presentazioni è diventato più rapido e semplice che mai.
Ecco 9 siti web AI che possono generare presentazioni in soli 60 secondi, eliminando la necessità di lavoro di design manuale e tutorial lunghi:
Gamma: Un’applicazione AI che può creare presentazioni complete tramite chat o importazione di testo. Questo strumento si distingue come uno dei preferiti tra gli utenti per la facilità d’uso e l’efficienza. Gamma.app
SlideSpeak: Crea presentazioni da testo in modo rapido e senza sforzo. Questo sito semplifica il processo di creazione di presentazioni, rendendolo accessibile a tutti. SlideSpeak.co
Tome: Un chatbot AI progettato per creare presentazioni con varie integrazioni, inclusa Figma. Questo strumento offre un’esperienza senza soluzione di continuità per gli utenti che desiderano generare presentazioni in modo efficiente. Tome.app
Slides AI: Un add-on di Google Slides alimentato da AI che genera presentazioni da input di testo. Questo strumento è perfetto per coloro che desiderano automatizzare il processo di creazione di presentazioni. SlidesAI.io
Decktopus AI: Conosciuto come il generatore di presentazioni AI più avanzato al mondo, Decktopus AI offre una soluzione completa per creare presentazioni dinamiche in pochi secondi. Decktopus.com
Beautiful AI: Questa piattaforma aiuta gli utenti a preparare il loro lavoro per il successo semplificando il processo di creazione di presentazioni. Con Beautiful AI, creare presentazioni visualmente accattivanti è un gioco da ragazzi. Beautiful.AI
AI ChatGPT for Presentations: Crea facilmente bellissimi mazzi con ideazione e creazione di mazzi alimentati da AI. Questo strumento semplifica il processo di progettazione delle presentazioni, rendendolo efficiente ed efficace. Presentations.AI
Pitch: Uno strumento rapido ed efficace per le squadre per produrre e distribuire presentazioni visivamente accattivanti. Pitch semplifica il processo di creazione di presentazioni, consentendo alle squadre di collaborare senza soluzione di continuità. Pitch.com
DeckRobot AI: Genera centinaia di mazzi di PowerPoint in pochi secondi con DeckRobot AI. Questo strumento è perfetto per coloro che desiderano creare presentazioni in modo rapido ed efficiente. Deckrobot.com
Con questi siti web AI, creare presentazioni non è mai stato così facile. Sfruttando le capacità dell’AI, gli utenti possono risparmiare tempo, ottimizzare il proprio flusso di lavoro e produrre presentazioni visualmente sorprendenti in una frazione del tempo che tradizionalmente richiederebbe. Abbracciare questi strumenti innovativi può rivoluzionare il modo in cui vengono create le presentazioni, consentendo agli utenti di concentrarsi sul contenuto e sulla narrazione anziché sulle complessità del design. Dì addio allo spreco di tempo con il lavoro di design e i tutorial: questi siti web AI sono qui per rendere la creazione di presentazioni un gioco da ragazzi!
Adobe ha dichiarato l’altra settiamana (23 Aprile) che porterà il suo ultimo modello di imaging, Firefly Image 3 Model, su Photoshop.
l nuovo modello consentirà al popolare programma software di fotoritocco di incorporare Generative Fill with Reference Image, che consente agli utenti di aggiungere e rimuovere contenuti tramite messaggi di testo grazie a Firefly. Firefly Image 3 Model migliora la qualità fotorealistica e consente agli utenti di modificare meglio gli oggetti, inclusi più stili e una migliore precisione, ha affermato Adobe.
Photoshop sta inoltre convertendo il testo in immagine tramite la nuova funzione Genera immagine, consentendo agli utenti di ridurre i tempi di creazione del contenuto.
Firefly, il modello di intelligenza artificiale generativa di Adobe introdotto lo scorso ottobre , è stato utilizzato per creare più di 7 miliardi di immagini, ha affermato la società.
“Il flusso costante di innovazioni di Adobe nel campo dell’intelligenza artificiale generativa sta stimolando la domanda di tutta la community creativa, dagli studenti ai professionisti della creatività e alle aziende Fortune 500“, ha dichiarato David Wadhwani, presidente del Digital Media Business di Adobe. “Con l’ultima versione di Photoshop, il nuovo modello Firefly Image 3 e il recente lancio delle applicazioni mobili Express, stiamo portando la potenza dell’intelligenza artificiale ai creator quando e dove ne hanno bisogno“.
Newsletter – Non perderti le ultime novità sul mondo dell’Intelligenza Artificiale: iscriviti alla nostra newsletter gratuita e accedi ai contenuti esclusivi di Rivista.AI direttamente nella tua casella di posta!
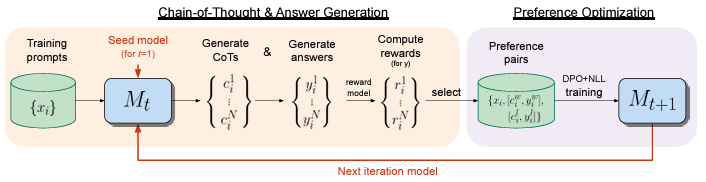
Iterative RPO è un metodo sviluppato per migliorare le capacità di ragionamento dei grandi modelli linguistici (LLM) attraverso un processo iterativo di ottimizzazione delle preferenze. [1][4]
Il metodo si concentra sull’ottimizzazione della preferenza tra diverse ipotesi di catene di ragionamento (Chain-of-Thought, CoT) generate dal modello, identificando i passaggi di ragionamento vincenti e perdenti che portano alla risposta corretta. [1][4]
Attraverso iterazioni successive, il modello viene addestrato a generare passaggi di ragionamento seguiti dalle risposte finali, migliorando così le sue capacità di ragionamento. [1][4]
Questa tecnica ha dimostrato miglioramenti significativi in compiti come GSM8K, ARC-Challenge e MATH, aumentando le prestazioni e l’accuratezza in assenza di addestramento specifico su tali task. [1][4]
Iterative RPO si basa su metodi di ottimizzazione delle preferenze offline, come Direct Preference Optimization (DPO), che hanno dimostrato di essere efficaci nell’allineare i modelli linguistici pre-addestrati alle esigenze umane rispetto al semplice fine-tuning supervisionato. [1][2][3][5]
Quindi, in sintesi, Iterative RPO è un approccio innovativo che mira a potenziare le capacità di ragionamento dei grandi modelli linguistici attraverso un processo iterativo di ottimizzazione delle preferenze tra diverse ipotesi di catene di ragionamento.
OpenBioLLM-8B è un modello di linguaggio avanzato open source progettato specificamente per il dominio biomedico. Sviluppato da Saama AI Labs, questo modello utilizza tecniche all’avanguardia per raggiungere prestazioni all’avanguardia in una vasta gamma di compiti biomedici.
Specializzazione biomedica: OpenBioLLM-8B è adattato alle esigenze linguistiche e di conoscenza uniche dei campi medici e delle scienze della vita. È stato sottoposto a fine-tuning su un vasto corpus di dati biomedici di alta qualità, consentendogli di comprendere e generare testi con precisione e fluidità specifiche del dominio.
Prestazioni superiori: con 8 miliardi di parametri, OpenBioLLM-8B supera gli altri modelli di linguaggio biomedico open source di scale simili. Ha anche dimostrato risultati migliori rispetto a modelli proprietari e open source più grandi come GPT-3.5 e Meditron-70B nei benchmark biomedici.
Tecniche di formazione avanzate: OpenBioLLM-8B si basa sulle potenti basi dei modelli Meta-Llama-3-8B e Meta-Llama-3-8B. Incorpora il set di dati DPO e la ricetta di fine-tuning, nonché un set di dati di istruzioni mediche personalizzato e diversificato. I componenti chiave del pipeline di formazione includono:
Ottimizzazione delle politiche: Ottimizzazione diretta delle preferenze (DPO) Set di dati di classificazione: berkeley-nest / Nectar Set di dati di fine-tuning: set di dati di istruzioni mediche personalizzato (abbiamo in programma di rilasciare un set di dati di formazione di esempio nel nostro prossimo articolo; resta aggiornato) Questa combinazione di tecniche all’avanguardia consente a OpenBioLLM-8B di allinearsi alle capacità e alle preferenze chiave per le applicazioni biomediche.
La classifica Open Medical LLM mira a tracciare, classificare e valutare le prestazioni dei modelli linguistici di grandi dimensioni (LLM) nelle attività di risposta alle domande mediche. Valuta gli LLM in una vasta gamma di set di dati medici, tra cui MedQA (USMLE), PubMedQA, MedMCQA e sottoinsiemi di MMLU relativi alla medicina e alla biologia. La classifica offre una valutazione completa delle conoscenze mediche e delle capacità di risposta alle domande di ciascun modello
Iscriviti alla nostra newsletter settimanale per non perdere le ultime notizie sull’Intelligenza Artificiale.
Google afferma che i suoi modelli sanitari AI Med-Gemini battono GPT-4
Google e DeepMind hanno pubblicato lunedì un documento che descrive Med-Gemini, un gruppo di modelli di intelligenza artificiale avanzati destinati ad applicazioni sanitarie.
Il documento descrive Med-Gemini, una famiglia di modelli multimodali altamente capaci specializzati in medicina, basati sulle solide capacità di Gemini in ragionamento multimodale e a lungo contesto.
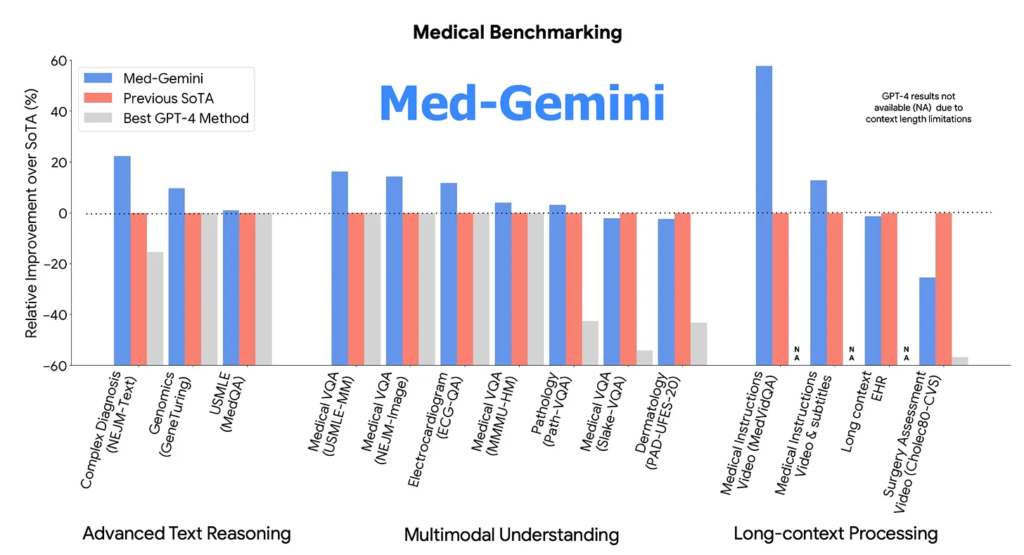
Med-Gemini è in grado di utilizzare la ricerca sul web in modo fluido e può essere adattato in modo efficiente a nuove modalità utilizzando encoder personalizzati. Il testo riporta i risultati dell’evaluazione di Med-Gemini su 14 benchmark medici, stabilendo nuovi record di performance in 10 di essi e superando la famiglia di modelli GPT-4 in ogni benchmark dove è possibile un confronto diretto, spesso con un ampio margine.
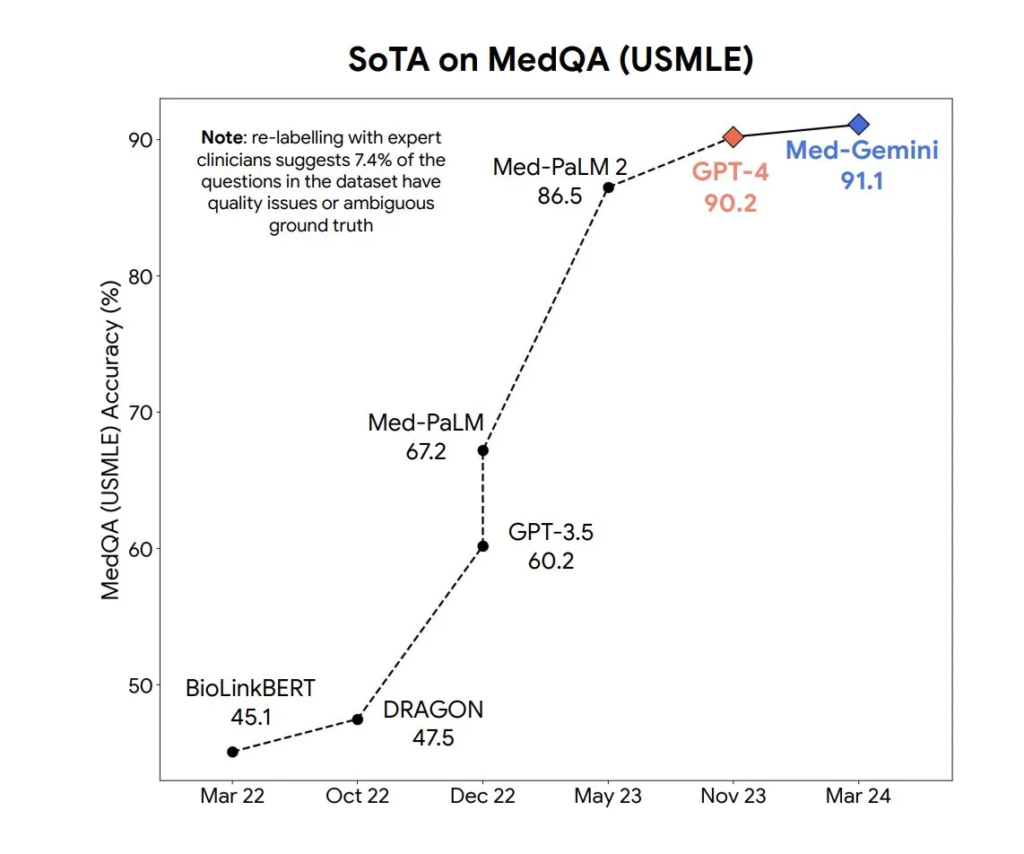
Il miglior modello Med-Gemini ha raggiunto una precisione del 91,1% sul popolare benchmark MedQA (USMLE), utilizzando una strategia di ricerca guidata dall’incertezza. Inoltre, Med-Gemini ha migliorato le prestazioni di GPT-4V su 7 benchmark multimodali, tra cui NEJM Image Challenges e MMMU (salute e medicina), con un margine medio relativo del 44,5%.
Le capacità di lungo contesto di Med-Gemini sono state dimostrate attraverso prestazioni di ricerca needle-in-a-haystack da lunghe cartelle cliniche de-identificate e question answering su video medici, superando i metodi precedenti che utilizzano solo l’apprendimento in-context.
Med-Gemini ha superato gli esperti umani in compiti come la sintesi di testi medici, dimostrando anche un potenziale promettente per il dialogo medico multimodale, la ricerca e l’educazione. Tuttavia, ulteriori valutazioni rigorose saranno cruciali prima di un’effettiva implementazione nel mondo reale in questo dominio critico per la sicurezza.
Med-Gemini ha fatto un notevole passo avanti nell’abilità di catturare contesto e temporalità, superando una delle maggiori sfide nell’addestramento degli algoritmi medici. A differenza degli attuali modelli di intelligenza artificiale relativa alla salute, Med-Gemini è in grado di comprendere il contesto e il contesto dei sintomi, nonché i tempi e la sequenza della loro insorgenza. Questa capacità è fondamentale per differenziare malattie lievi da quelle potenzialmente pericolose per la vita.
Per raggiungere questo obiettivo, gli sviluppatori di Google hanno adottato un approccio verticale per verticale, creando una “famiglia” di modelli, ciascuno dei quali ottimizza uno specifico dominio o scenario medico. Questo approccio ha portato a una precisione migliore e più sfumata, nonché a un ragionamento più trasparente e interpretabile.
Inoltre, Med-Gemini incorpora un livello aggiuntivo: una ricerca basata sul web di informazioni aggiornate. Questa funzionalità consente l’integrazione dei dati con conoscenze esterne, integrando i risultati online nel modello. Ciò garantisce che Med-Gemini sia sempre allo stesso standard dei medici, che si aspettano di tenersi al passo con le ricerche recenti.
Med-Gemini rappresenta un significativo passo avanti nell’abilità di catturare contesto e temporalità, superando le sfide contestuali nell’addestramento degli algoritmi medici. L’approccio verticale per verticale e l’integrazione di una ricerca basata sul web di informazioni aggiornate hanno portato a una precisione e un ragionamento migliori e più trasparenti.
Iscriviti alla nostra newsletter settimanale per non perdere le ultime notizie sull’Intelligenza Artificiale.
Oracle ha annunciato giovedì che la sua tecnologia di database per l’intelligenza artificiale, Database23ai, è ora “generalmente disponibile” per gli sviluppatori.
La disponibilità della nuova tecnologia consentirà di trovare chatbot e altri software di intelligenza artificiale in modo più semplice utilizzando AI Vector Search di Oracle.
“Le nuove funzionalità AI Vector Search consentono ai clienti di combinare in modo sicuro la ricerca di documenti, immagini e altri dati non strutturati con la ricerca di dati aziendali privati, senza spostarli o duplicarli”, ha affermato la società in una nota .
Oracle
“Oracle Database 23ai porta gli algoritmi AI dove risiedono i dati, invece di dover spostare i dati dove risiedono gli algoritmi AI. Ciò consente all’IA di funzionare in tempo reale nei database Oracle e migliora notevolmente l’efficacia, l’efficienza e la sicurezza dell’intelligenza artificiale.”
Oracle
Il dirigente di Oracle Juan Loaiza lo ha definito un “punto di svolta” per le imprese, aggiungendo che aumenterà la produttività.
Iscriviti alla nostra newsletter settimanale per non perdere le ultime notizie sull’Intelligenza Artificiale.