

Con l’aumento della richiesta di intelligenza artificiale più sicura ed efficiente, l’IA decentralizzata (DeAI) diventerà sempre più importante per l’infrastruttura di IA. Tuttavia, per sfruttare al massimo il suo potenziale, un nuovo whitepaper afferma che DeAI dovrà incorporare la tecnologia dei Trusted Execution Environment (TEE).
Categoria: Tech Pagina 17 di 21
L’intelligenza artificiale (AI) nel suo senso piu’ ampio e l’intelligenza esibita dai sistemi informatici (Machine)
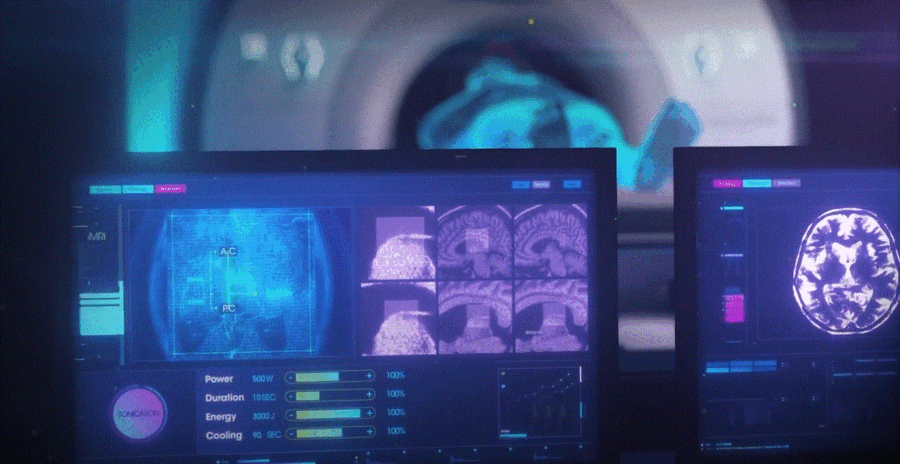
Un’innovativa tecnologia basata sull’intelligenza artificiale (AI) sta rivoluzionando il modo in cui vengono identificati i pazienti a rischio di infarto. Descritta come “game changer” dai ricercatori, questa tecnologia è in grado di rilevare l’infiammazione cardiaca che non è visibile tramite le tradizionali scansioni TC, che utilizzano raggi X e tecniche informatiche avanzate.
Negli ultimi anni, l’intelligenza artificiale ha fatto passi da gigante, in particolare nel campo della generazione di immagini. Strumenti come Midjourney, Stable Diffusion 3 (SD3) e Auraflow hanno dimostrato il potenziale di questa tecnologia. Tuttavia, un nuovo attore è entrato in scena: Flux. Questo generatore di immagini AI open source promette di superare i suoi predecessori e ridefinire gli standard del settore.

L’intelligenza artificiale (IA) è una tecnologia con un potenziale straordinario, ma solleva anche importanti interrogativi riguardo alle aspettative esagerate e ai costi elevati. Gli attuali investimenti in IA hanno portato a incrementi limitati di fatturato, richiedendo soluzioni a problemi complessi per giustificare il ritorno sugli investimenti. Sebbene l’IA abbia mostrato di poter migliorare l’efficienza in vari settori, è ancora lontana dal raggiungere un’intelligenza di livello umano. Tuttavia, ha un significativo potenziale per rivoluzionare l’efficienza energetica e la sostenibilità.
Huggingface ha presentato una demo di BiRefNet , un modello concesso in licenza dal MIT, per la rimozione gratuita dello sfondo delle immagini.
Provatelo
Ecco una tabella aggiornata con 50 chatbot, ordinati per uso principale. Ogni riga include il nome del chatbot, il link e la categoria di utilizzo.


Google DeepMind ha recentemente annunciato il rilascio di Gemma 2 2B, un modello di linguaggio all’avanguardia che si distingue per la sua leggerezza e capacità di funzionare con soli 1 GB di memoria. Questa nuova aggiunta alla famiglia Gemma è progettata per offrire prestazioni eccezionali in un formato accessibile, rendendo la tecnologia AI avanzata disponibile anche per dispositivi con risorse limitate.

OpenAI ha recentemente annunciato il lancio della modalità vocale avanzata per gli utenti di ChatGPT Plus, una funzionalità attesa che promette di rivoluzionare l’interazione con il chatbot. Questa nuova modalità, attualmente in fase alpha, è stata progettata per offrire conversazioni più naturali e coinvolgenti, avvicinando ulteriormente l’esperienza utente a quella di una conversazione reale.

Hugging Face ha recentemente annunciato un nuovo servizio di Inference-as-a-Service che sfrutta le potenzialità delle microservizi NVIDIA NIM, presentato durante la conferenza SIGGRAPH. Questo servizio offre agli sviluppatori l’accesso immediato a modelli di intelligenza artificiale (AI) di alta qualità, ottimizzati per l’efficienza e la velocità, grazie all’infrastruttura NVIDIA DGX Cloud.

Il CEO di Nvidia Jensen Huang ha annunciato che i data center di Meta AI contengono circa 600.000 GPU H100 di Nvidia, durante un’intervista al SIGGRAPH 2024 di Denver.

Secondo Bloomberg, la modalità vocale avanzata sarà disponibile per tutti gli abbonati a ChatGPT Plus questo autunno. Quando OpenAI ha presentato questa funzionalità a maggio, ha ricevuto critiche perché una delle voci somigliava molto a Scarlett Johansson.
OpenAI ha sospeso il programma per risolvere alcuni problemi. La nuova versione offre quattro voci preimpostate. OpenAI ha affermato di aver introdotto misure di sicurezza per impedire l’uso improprio della tecnologia per imitare voci o generare materiale audio protetto da copyright.
“Grazie al lancio graduale, possiamo monitorare l’utilizzo e migliorare costantemente il modello in base ai feedback reali”, ha dichiarato OpenAI a Bloomberg. OpenAI sta ancora lavorando sulle funzionalità di condivisione video e schermo legate alla modalità vocale avanzata, ma non ha ancora indicato una data di rilascio.
Se non volete perdervi gli ultimi articoli e sempre che non l’abbiate già fatto, potete iscrivervi alla newsletter di Rivista.AI per rimanere sempre aggiornati sulle ultime novità sul mondo dell’intelligenza artificiale, con contenuti esclusivi direttamente nella vostra casella di posta.
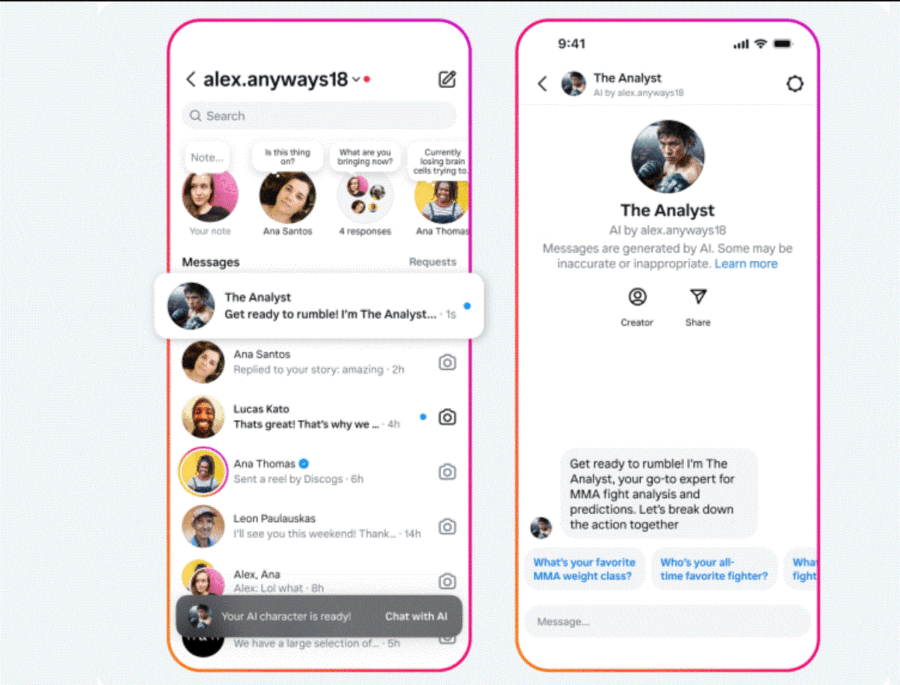
Meta ha recentemente lanciato il suo AI Studio, un nuovo strumento progettato per consentire ai creatori di costruire chatbot personalizzati.
Questo strumento è stato reso disponibile a tutti i creatori negli Stati Uniti e rappresenta un passo significativo nella visione di Meta per l’intelligenza artificiale.
Durante la conferenza SIGGRAPH 2024, il CEO di Meta, Mark Zuckerberg, ha illustrato le potenzialità di questo studio, enfatizzando l’importanza di avere chatbot personalizzati piuttosto che un’unica entità AI generica.
Il colosso della tecnologia ha affermato che con AI Studio chiunque può creare personaggi AI sul sito web ai.meta o nell’app Instagram.

Runway ha recentemente lanciato una nuova funzionalità che consente di generare video a partire da immagini statiche, utilizzando il suo modello Gen-3 Alpha. Questa innovazione, implementata solo poche ore fa, ha suscitato grande entusiasmo tra i creatori di contenuti e gli appassionati di tecnologia.

Meta ha recentemente presentato la seconda generazione del suo modello di segmentazione degli oggetti, il Meta Segment Anything Model 2 (SAM 2) (provate il demo nel link). Questo avanzato modello di intelligenza artificiale rappresenta un significativo passo avanti nella capacità di identificare e isolare gli oggetti all’interno di immagini e video.

Apple ha recentemente rivelato di aver utilizzato chip progettati da Google per sviluppare due modelli fondamentali della sua infrastruttura di intelligenza artificiale, piuttosto che ricorrere a quelli di Nvidia.

La startup Synchron specializzata in impianti cerebrali ha annunciato martedì che l’Apple Vision Pro può essere controllato tramite il pensiero di una persona.

SIGGRAPH 2024 si svolgera’ dal 30 luglio al 1 agosto 2024 presso il Colorado Convention Center di Denver. Questa conferenza è considerata la più importante esposizione su computer grafica e tecniche interattive, celebrando 50 anni di innovazione nel settore. Durante l’evento, i partecipanti esploreranno i progressi in vari ambiti, tra cui arte digitale, animazione, effetti visivi, realtà mista e intelligenza artificiale.

Grok, il chatbot di intelligenza artificiale generativa di proprietà di xAI di Elon Musk, ora utilizza automaticamente X post per addestrare i suoi modelli.
OpenAI, con il supporto di Microsoft, ha lanciato SearchGPT, un prototipo che combina ricerca e intelligenza artificiale con dati dal web. Attualmente, è disponibile solo per un gruppo selezionato di utenti ed editori per raccogliere feedback. Chi vuole iscriversi alla lista d’attesa può farlo qui.
Come per altre tecnologie di OpenAI, come Sora o il suo
Voice Engine , questo è solo un teaser per far sapere agli utenti a cosa sta lavorando il colosso dell’intelligenza artificiale.

La Canon EOS R5 Mark II (4.929,00 €) è stata recentemente lanciata, presentando una serie di caratteristiche innovative che la rendono un’opzione allettante per i fotografi e videomaker.

Microsoft ha introdotto un rivoluzionario strumento di ricerca con intelligenza artificiale generativa su Bing, ora in uso per una selezione limitata di query degli utenti.
“Combinando la potenza dell’intelligenza artificiale generativa e dei modelli linguistici di grandi dimensioni con la pagina dei risultati di ricerca, la ricerca generativa di Bing crea risposte dinamiche e personalizzate alle query degli utenti”, ha dichiarato l’azienda
post sul blog pubblicato oggi.
La generazione AI di Bing è paragonabile alle panoramiche AI di Google, introdotte a maggio, che creano riepiloghi in risposta alle query di ricerca.
Le panoramiche AI hanno sollevato critiche per il potenziale di ridurre il traffico web, diminuendo le visite organiche agli editori e influenzando negativamente i ricavi pubblicitari. Microsoft ha riconosciuto questo possibile impatto.
“Stiamo continuando a esaminare attentamente l’impatto della ricerca generativa sul traffico verso gli editori”, ha affermato Microsoft. “I primi dati indicano che questa esperienza mantiene il numero di clic sui siti Web e supporta un ecosistema Web sano”.
Microsoft ha annunciato il lancio graduale del suo nuovo prodotto di ricerca basato sull’intelligenza artificiale, con ulteriori aggiornamenti previsti nei prossimi mesi. Google continua a dominare il settore della ricerca online, rappresentando l’87% delle ricerche, secondo i dati più recenti di Statista. Bing si posiziona al secondo posto con una quota dell’8%.
Il 18 luglio 2024, Mistral AI e NVIDIA hanno annunciato congiuntamente il rilascio di Mistral NeMo, un modello linguistico all’avanguardia sviluppato attraverso i loro sforzi collaborativi.

SingularityNET, una piattaforma di intelligenza artificiale decentralizzata, ha annunciato un investimento di $53 milioni per accelerare lo sviluppo dell’Intelligenza Artificiale Generale (AGI) e dell’Intelligenza Artificiale Superintelligente (ASI).

Nvidia sta sviluppando una versione dei suoi nuovi chip AI di punta, la serie Blackwell, specificamente per il mercato cinese, in conformità con le attuali restrizioni alle esportazioni statunitensi.

OpenAI, la startup di intelligenza artificiale generativa supportata da Microsoft, ha lanciato giovedì una versione più piccola ed economica del suo modello di intelligenza artificiale di punta, chiamato GPT-4o mini. Questo nuovo modello richiede meno energia per funzionare e costa 15 centesimi per milione di token in input e 60 centesimi per milione di token in output, risultando oltre il 60% più conveniente rispetto a GPT-3.5 Turbo, secondo OpenAI.
GPT-4o mini ha superato i concorrenti ottenendo un punteggio dell’82% nella comprensione del linguaggio multitasking massivo, rispetto al 77,9% di Gemini Flash di Google e al 73,8% di Claude Haiku di Anthropic.
Il nuovo modello sarà disponibile più tardi oggi per gli utenti gratuiti di ChatGPT, oltre che per gli abbonati a ChatGPT Plus e Team. Gli utenti di ChatGPT Enterprise avranno accesso a partire dalla prossima settimana.

Bloom Energy ha annunciato una partnership per installare le sue celle a combustibile presso un data center ad alte prestazioni di CoreWeave in Illinois.
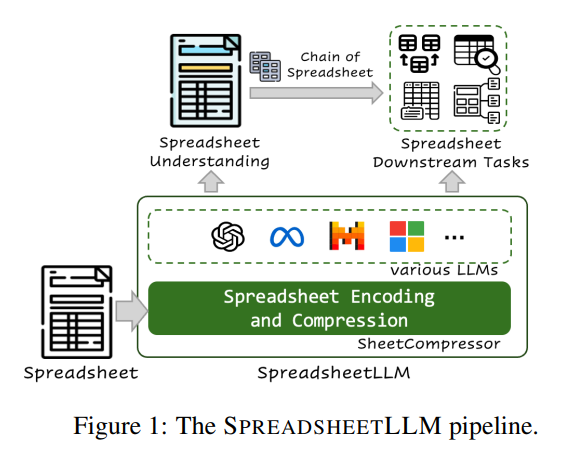
Il paper “SpreadsheetLLM: Codifica dei fogli di calcolo per modelli di linguaggio di grandi dimensioni” introduce una nuova tecnica per rappresentare i fogli di calcolo in modo che possano essere utilizzati con modelli di linguaggio di grandi dimensioni (LLMs). I ricercatori propongono tecniche per rappresentare la struttura, le formule e i dati dei fogli di calcolo in un formato che possa essere elaborato efficacemente dai modelli di linguaggio.

Generare codice sorgente e soluzioni utilizzando l’AI suona eccitante da un lato e terrificante dall’altro, ma non è questo il punto della conversazione.

VidAU è una piattaforma innovativa che semplifica la creazione di video coinvolgenti utilizzando link o descrizioni di prodotti, grazie a avatar realistici che parlano in diverse lingue e accenti.
Con una suite completa di strumenti di editing video, come scambio di volti e traduzione, VidAU sta rapidamente guadagnando popolarità tra aziende e piattaforme di e-commerce, migliorando l’efficienza del content marketing e i tassi di conversione.

Nell’era digitale, l’originalità dei contenuti è diventata un aspetto cruciale per editori, scrittori e creatori di contenuti. Con l’aumento della produzione di contenuti online, garantire che un testo sia autentico e non copiato è fondamentale per mantenere la credibilità e l’integrità. È qui che entra in gioco Originality.ai, una piattaforma innovativa progettata per rilevare il plagio e l’originalità dei contenuti.
Originality.ai è stata fondata da Jon Gillham dopo aver venduto un’agenzia di content marketing che aveva fondato in precedenza. L’azienda si concentra sulla fornitura di strumenti per rilevare il contenuto generato dall’IA e garantire l’integrità del contenuto.
Google ha lanciato la versione beta del suo nuovo strumento di creazione video basato sull’intelligenza artificiale generativa,
Google Vids, per alcuni utenti selezionati della sua suite di applicazioni Workspace per le aziende.
Vids è un’app di creazione video alimentata dall’AI, progettata per l’uso professionale e profondamente integrata con gli strumenti di produttività di Google Workspace che gli utenti aziendali utilizzano quotidianamente.

Nel corso dell’ultimo anno, Be My Eyes ha stretto una partnership innovativa con OpenAI, integrando il potente modello di intelligenza artificiale (AI) di quest’ultima nella sua app, offrendo così un’assistenza visiva non più fornita da un volontario umano, ma da un sofisticato sistema AI. Questa collaborazione segna un passo significativo nell’uso della tecnologia per migliorare la qualità della vita delle persone non vedenti e ipovedenti.

Gli ingegneri in Cina hanno costruito un cane computerizzato che potrebbe fornire un’alternativa pratica ai veri cani guida. Guide Dog Robot (GDR)
I ricercatori cinesi stanno sviluppando un robot “cane guida” a sei zampe con l’obiettivo di assistere le persone non vedenti per aumentarne l’autonomia. Questo innovativo robot, attualmente in fase di test sul campo, si affida a telecamere e sensori per manovrare attraverso l’ambiente circostante, riuscendo persino a identificare i segnali del traffico – un compito al di là delle capacità dei tradizionali cani guida.

L’avvento dell’intelligenza artificiale generativa ha aperto nuove possibilità affascinanti, permettendo la creazione di immagini, video e audio realistici tramite strumenti come ChatGPT e DALL-E. Tuttavia, sfruttare appieno il potenziale di questi strumenti AI non è sempre semplice. La chiave risiede nell’abilità di “prompt engineering“, ovvero la capacità di creare prompt precisi e ben strutturati per ottenere i risultati desiderati.
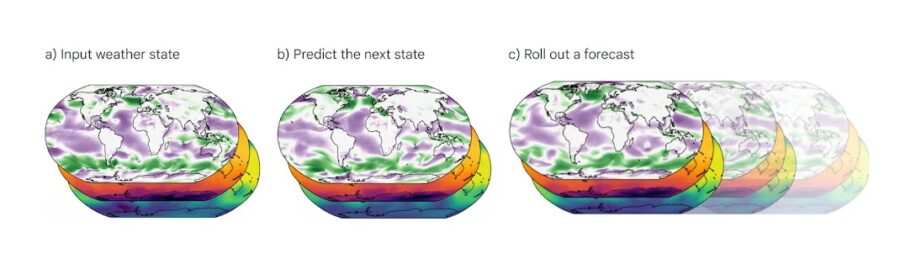
Google DeepMind, la divisione di intelligenza artificiale di Google, ha vinto il prestigioso MacRobert Award 2024 per il suo innovativo sistema di previsioni meteo chiamato GraphCast. Questo modello di IA è in grado di fornire previsioni meteo a 10 giorni con una precisione senza precedenti, in meno di un minuto di calcolo.
Caratteristiche chiave di GraphCast:
- Previsioni a 10 giorni con risoluzione di 0,25 gradi (circa 28 km), coprendo l’intero pianeta
- Predice 5 variabili meteo a livello del suolo e 6 variabili atmosferiche a 37 diversi livelli di altitudine
- Supera del 90% le prestazioni del precedente sistema di riferimento HRES per la maggior parte delle variabili
- Esegue le previsioni in meno di 1 minuto, contro le ore richieste dai sistemi tradizionali su supercomputer
Rispetto ad altre app meteo popolari come Dark Sky, AccuWeather e WeatherBug, GraphCast offre previsioni molto più accurate e dettagliate, con un orizzonte temporale molto più esteso. Inoltre, essendo un modello open source, può essere ulteriormente sviluppato e adattato da ricercatori e sviluppatori di tutto il mondo.
Questo riconoscimento dimostra come l’IA stia rivoluzionando il campo della meteorologia, offrendo strumenti molto più potenti ed efficienti rispetto ai metodi tradizionali. Mentre i modelli IA come GraphCast non sono ancora perfetti (ad esempio hanno difficoltà con le previsioni di eventi meteorologici estremi), i progressi compiuti sono davvero impressionanti. In futuro, possiamo aspettarci che l’IA giochi un ruolo sempre più centrale nelle previsioni meteo, a beneficio di moltissimi settori economici e della vita quotidiana delle persone.

Come abbiamo scritto nel mese scorso, la comunità di utenti di Stable Diffusion è stata scossa da una serie di polemiche innescate dalle nuove condizioni di licenza imposte da Stability AI per il suo modello di intelligenza artificiale, Stable Diffusion 3 (SD3). Queste restrizioni hanno suscitato un’ondata di proteste e malcontento tra gli utenti, costringendo l’azienda a fare marcia indietro su alcune delle sue decisioni. La situazione ha raggiunto un punto di svolta venerdì sera, quando Stability AI ha annunciato di aver allentato alcune delle sue condizioni, nel tentativo di placare le tensioni. Tuttavia, questa mossa ha generato reazioni contrastanti all’interno della comunità.

NTT DATA Italia ha recentemente annunciato il programma Artificial Intelligence Metamorphosis, che punta a rivoluzionare il lavoro delle imprese italiane con l’Intelligenza Artificiale (AI).
L’obiettivo è trasformare l’intera organizzazione aziendale – dal modello interno ai modelli di business e all’offerta per i clienti – superando il semplice concetto di riduzione dei costi e migliorando le performance, esplorando nuove possibilità grazie all’AI.
Questa iniziativa fa parte di una strategia globale che dal 1° Aprile ha unito le attività di NTT DATA e NTT Ltd. in NTT DATA Inc., un colosso con oltre 190.000 dipendenti in più di 50 paesi e ricavi superiori ai 30 miliardi di dollari.
Questa integrazione offre un vantaggio competitivo alla multinazionale giapponese, ora con un’offerta di trasformazione AI end to end che include consulenza, infrastrutture – Data Center e connettività – soluzioni digitali e servizi gestiti.
Ne abbiamo parlato con Nicola Russo, Head of Data&Intelligence and Head of AI Metamorphosis Program.

Progressi nell’apprendimento automatico classico e l’emergere dell’apprendimento automatico quantistico
L’apprendimento automatico (ML) classico, un sottoinsieme dell’intelligenza artificiale, è evoluto significativamente dalla sua nascita negli anni ’60. Dall’iniziale riconoscimento di modelli semplici all’attuale utilizzo di enormi dataset per l’addestramento e la generazione di previsioni altamente accurate, l’ML si è dimostrato uno strumento potente in vari settori. Tuttavia, la crescita esponenziale dei dati ha messo in svantaggio i computer classici, poiché si prevede che i sistemi quantistici gestiranno tali scale massicce in modo più efficiente in futuro. Ciò ha portato allo sviluppo dell’apprendimento automatico quantistico (QML), che è destinato a portare significativi progressi nell’ML.
La generazione di intelligenza artificiale (GenAI) e le reti di comunicazione wireless sono destinate ad avere sinergie rivoluzionarie nella rete 6G. Connettendo gli agenti GenAI attraverso una rete wireless, si può potenzialmente liberare la potenza dell’intelligenza collettiva e aprire la strada all’intelligenza artificiale generale (AGI). Tuttavia, le attuali reti wireless sono progettate come un “tubo di dati” e non sono adatte ad accogliere e sfruttare la potenza della GenAI.