

Tesla sta cercando di assumere personale per raccogliere dati per il robot umanoide Optimus. La posizione, chiamata “Operatore Raccolta Dati, Tesla Bot”, richiede ai dipendenti di indossare una tuta per il motion capture e un visore VR mentre eseguono movimenti specifici.
Categoria: Tech Pagina 16 di 21
L’intelligenza artificiale (AI) nel suo senso piu’ ampio e l’intelligenza esibita dai sistemi informatici (Machine)
La tecnologia degli scanner della lingua basati su intelligenza artificiale (AI) si sta affermando come uno strumento innovativo nella diagnostica medica. Questi dispositivi analizzano le caratteristiche fisiche della lingua per fornire informazioni sulla salute generale di un individuo. L’analisi della lingua può rivelare segni di malattie sistemiche, carenze nutrizionali e altre condizioni mediche, rendendo questa tecnologia un valido supporto per i professionisti sanitari.

I produttori sudcoreani di chip per l’intelligenza artificiale Rebellions e Sapeon Korea hanno annunciato domenica di aver firmato un accordo di fusione. Sapeon Korea, fondata da SK Telecom, e la startup di chip per l’intelligenza artificiale Rebellions avevano comunicato a giugno la loro intenzione di fondersi per rafforzare la competitività delle infrastrutture globali per l’intelligenza artificiale.

AMD sta acquisendo il fornitore di infrastrutture di intelligenza artificiale ZT Systems per circa 4,9 miliardi di dollari in contanti e azioni. L’accordo include un pagamento condizionato fino a 400 milioni di dollari, basato su certi obiettivi post-chiusura. AMD cercherà un partner strategico per acquisire l’attività di produzione di infrastrutture per data center di ZT Systems negli Stati Uniti. Questa acquisizione aiuterà AMD ad ampliare le sue capacità nei data center e nei sistemi di intelligenza artificiale.

Il disegno di legge, già approvato dalla Commissione della California, ha subito modifiche significative per rispondere alle preoccupazioni espresse da Anthropic e da altri nel settore.

In un articolo di The Guardian della scorsa settimana ha discusso un interessante divario nei grandi modelli di linguaggio (come GPT-4).
Il “problema di Tom Cruise” nell’intelligenza artificiale (IA) si riferisce a una serie di limitazioni nei modelli di linguaggio di grandi dimensioni (LLM), come GPT-4, che evidenziano la loro incapacità di inferire relazioni tra fatti in modo simmetrico.
Deep Live Cam è un innovativo strumento di deepfake che consente di trasformare foto statiche in flussi video in diretta, utilizzando il volto di una persona per “animare” un’immagine o un video target.
Questo software open source, distribuito sotto licenza GNU GPLv3, è stato sviluppato per supportare artisti e creativi in vari settori, come l’animazione, il design e la moda, permettendo loro di visualizzare e modificare istantaneamente i loro progetti.
Visita: https://github.com/hacksider/Deep-Live-Cam

Il futuro: un ricercatore di intelligenza artificiale completamente automatizzato che migliora se stesso in modo aperto (LLM²).
Sakana AI, una startup giapponese, ha introdotto un sistema innovativo chiamato The AI Scientist, che afferma di automatizzare l’intero processo di ricerca scientifica. Questo modello di intelligenza artificiale, sviluppato in collaborazione con ricercatori dell’Università di Oxford e dell’Università della Columbia Britannica, è progettato per condurre autonomamente ricerche, dalla generazione di idee alla scrittura e revisione di articoli scientifici.
Google ha recentemente mostrato un interesse significativo nell’investire in Opal Camera, un’azienda emergente nel settore delle webcam di alta qualita.
Opal Camera ha completato un round di finanziamento di Serie A da 17 milioni di dollari, guidato da Founders Fund, con la partecipazione di altri investitori come Kindred Ventures e Slack Fund.
Anthropic ha recentemente lanciato una nuova funzionalità chiamata prompt caching, disponibile in versione beta pubblica per i modelli Claude 3.5 Sonnet e Claude 3 Haiku.
Questa innovazione consente agli sviluppatori di memorizzare contesti frequentemente utilizzati tra le chiamate API, con l’obiettivo di ridurre i costi fino al 90% e la latenza fino all’85% per i prompt lunghi.
Opera ha lanciato Opera One, il suo browser di punta alimentato dall’IA, per iPhone. Questa versione per iOS offre le stesse caratteristiche estetiche del browser desktop Opera One premiato, insieme a una serie di funzionalità progettate per offrire un’esperienza di navigazione ottimale su iPhone.

Runway ML ha recentemente lanciato Gen-3 Alpha Turbo, una nuova versione del suo innovativo modello di generazione video, che promette prestazioni significativamente superiori rispetto al suo predecessore. Questo aggiornamento, annunciato il 31 luglio 2024, introduce un sistema in grado di generare video fino a sette volte più velocemente rispetto a Gen-3 Alpha, mantenendo al contempo una qualità elevata e realistica.

Google ha annunciato giovedì l’espansione dei suoi riepiloghi generati dall’intelligenza artificiale in sei nuovi paesi, aggiungendo nuove funzionalità al prodotto. AI Overviews, sostenuta dall’AI Gemini di Google, sarà disponibile nel Regno Unito, India, Giappone, Indonesia, Messico e Brasile, con supporto per le lingue locali.
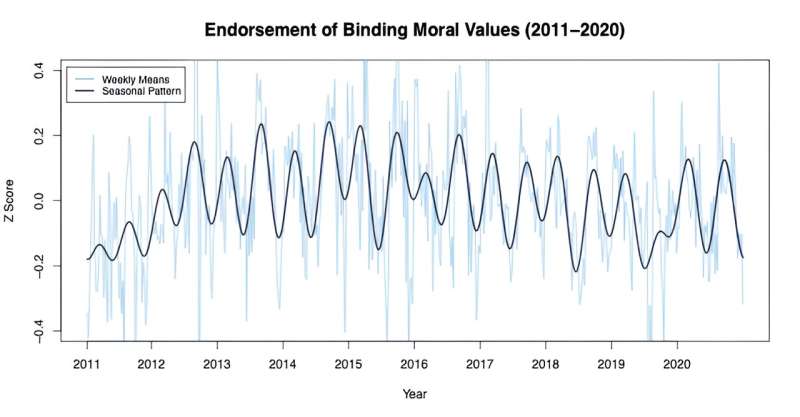
Un nuovo studio condotto dall’Università della Columbia Britannica ha rivelato che i valori morali delle persone cambiano regolarmente in base alle stagioni. Questa ricerca, pubblicata nelle Proceedings of the National Academy of Sciences, ha analizzato le risposte a sondaggi di oltre 230.000 persone negli Stati Uniti nel corso di dieci anni, mostrando che l’approvazione di valori morali che promuovono la coesione di gruppo e la conformità è più forte in primavera e autunno rispetto a estate e inverno.

Google ha recentemente lanciato la modalità di chat vocale per il suo sistema di intelligenza artificiale Gemini, un aggiornamento significativo che promette di rivoluzionare il modo in cui gli utenti interagiscono con la tecnologia. Google ha incorporato nuovi modelli come Gemini 1.5 Flash che sono più veloci e forniscono risposte di qualità superiore.
Gemini è completamente integrato nell’esperienza utente Android, offrendo maggiori capacità contestuali possibili. Gemini Live inizia a essere distribuito oggi in inglese per gli abbonati Gemini Advanced sui telefoni Android e nelle prossime settimane si espanderà a iOS e ad altre lingue.
Nelle prossime settimane lanceranno nuove estensioni
,tra cui Keep, Tasks, Utilities e funzionalità espanse su YouTube Music

Secondo i dati di Canalys, nel secondo trimestre del 2024 sono stati spediti 8,8 milioni di PC con intelligenza artificiale.
Di questi, il 60% erano Mac di Apple e il 39% con sistemi operativi Windows di Microsoft. Canalys definisce i PC con intelligenza artificiale come quelli con un “chipset o blocco dedicato per eseguire carichi di lavoro di intelligenza artificiale sul dispositivo”. Esempi di questi chipset sono XDNA di AMD, Neural Engine di Apple, AI Boost di Intel, e Hexagon di Qualcomm. “Il secondo trimestre del 2024 ha spinto molto l’espansione dei PC con intelligenza artificiale”, ha detto Ishan Dutt , analista principale di Canalys. “A giugno è stato lanciato il PC Copilot+ con chip Snapdragon X di Qualcomm, basato su architettura Arm”.

Google ha presentato la sua ultima linea di telefoni Pixel 9, tutti dotati dell’assistente intelligente artificiale integrato Gemini Nano.
“Gemini Nano è il modello più efficiente per alimentare l’intelligenza artificiale sul dispositivo”, “L’infrastruttura ibrida ci consente di eseguire Gemini su larga scala sul cloud e sul tuo dispositivo”.
“Per anni abbiamo immaginato il nostro assistente AI mobile, ma siamo stati limitati da ciò che i dispositivi potevano fare”, ha aggiunto. “Può essere possibile solo grazie ai progressi fatti sui dispositivi negli ultimi sei mesi. Il nuovo assistente Gemini va oltre la comprensione delle parole per comprendere le tue intenzioni”.
Rick Osterloh, vicepresidente senior di Google per le piattaforme e i dispositivi,

Google ha recentemente annunciato una significativa riduzione dei prezzi per il suo modello di intelligenza artificiale Gemini 1.5 Flash, con un abbattimento del 70% rispetto ai precedenti modelli. Questa mossa mira a rendere l’IA più accessibile agli sviluppatori, offrendo al contempo funzionalità avanzate e prestazioni elevate.

Secondo alcune fonti, Sequoia Capital è in trattative per finanziare Harmonic, una startup cofondata dal CEO di Robinhood, Vlad Tenev, e dall’imprenditore Tudor Achim, noto per il suo lavoro nel settore dei veicoli a guida autonoma. Harmonic si propone di sviluppare un’intelligenza artificiale (AI) capace di ragionare attraverso problemi complessi, in particolare in ambito matematico.

Kroger, una delle più grandi catene di supermercati negli Stati Uniti, ha recentemente implementato un sistema di pricing dinamico basato sull’intelligenza artificiale (AI). Questo approccio consente all’azienda di adattare i prezzi dei prodotti in tempo reale, in risposta a vari fattori come la domanda dei consumatori, la disponibilità di prodotti e le strategie dei concorrenti.

OpenAI, ha affermato di avere una nuova versione del suo modello linguistico di grandi dimensioni GPT-4o, ma ha fornito pochi dettagli a riguardo.
“C’è un nuovo modello GPT-4o disponibile su ChatGPT dalla scorsa settimana”, “Speriamo che vi stiate divertendo e che lo diate un’occhiata se non l’avete ancora fatto! Noi pensiamo che vi piacerà.”
Secondo VentureBeat , alcuni utenti hanno scoperto che il nuovo modello include un ragionamento in più fasi e spiegazioni più dettagliate dei suoi processi .
Microsoft ha investito miliardi di dollari in OpenAI a gennaio 2023, poco dopo che il chatbot AI generativo ChatGPT aveva conquistato il pubblico. Da allora, OpenAI ha lanciato nuovi modelli, tra cui GPT-4o a maggio. Ha anche rilasciato una versione più piccola e conveniente, GPT-4o mini, il mese scorso.
Huawei Technologies sta per lanciare un nuovo chip per l’intelligenza artificiale, cercando di superare le sanzioni USA e competere con Nvidia, ha riportato il Wall Street Journal.
Di recente, aziende Internet e operatori di telecomunicazioni cinesi hanno testato il nuovo chip, Ascend 910C, secondo il rapporto. Huawei sostiene che il chip è paragonabile all’H100 di Nvidia, che non è disponibile in Cina.
Tuttavia, Huawei ha affrontato ritardi nella produzione dei suoi chip attuali e potrebbe subire ulteriori restrizioni dagli Stati Uniti, impedendole di ottenere parti di macchine e chip di memoria per l’hardware AI.

Recenti ricerche hanno rivelato vulnerabilità allarmanti in Microsoft Copilot AI, evidenziando il suo potenziale di essere utilizzato come una macchina per phishing automatizzata. Questa questione è stata evidenziata dal ricercatore di sicurezza Michael Bargury durante la conferenza Black Hat sulla sicurezza a Las Vegas, dove ha dimostrato diversi proof-of-concept che sfruttano le capacità dell’AI.

Ripensando all’evento AWS re:Invent 2023, Jensen Huang, fondatore e CEO di NVIDIA, ha parlato sul palco con il CEO di AWS Adam Selipsky. Hanno discusso di come NVIDIA e AWS stiano collaborando per permettere a milioni di sviluppatori di accedere a tecnologie avanzate per innovare rapidamente con l’intelligenza artificiale generativa.
AWS e NVIDIA hanno rafforzato la loro collaborazione al GTC 2024. I CEO delle due aziende hanno discusso la loro partnership e l’evoluzione dell’intelligenza artificiale in un comunicato stampa:
“La profonda collaborazione tra le nostre due organizzazioni risale a più di 13 anni fa, quando insieme abbiamo lanciato la prima istanza cloud GPU al mondo su AWS, e oggi offriamo la più ampia gamma di soluzioni GPU NVIDIA per i clienti”, afferma Adam Selipsky , CEO di AWS. “Il processore Grace Blackwell di nuova generazione di NVIDIA segna un significativo passo avanti nell’intelligenza artificiale generativa e nel GPU computing. Se combinato con la potente rete Elastic Fabric Adapter di AWS, il clustering iperscalabile di Amazon EC2 UltraClusters e le esclusive funzionalità di virtualizzazione e sicurezza avanzate del nostro AWS Nitro System , rendiamo possibile per i clienti creare ed eseguire modelli di linguaggio di grandi dimensioni con più di trilioni di parametri più velocemente, su larga scala e in modo più sicuro che altrove. Insieme, continuiamo a innovare per rendere AWS il posto migliore in cui eseguire GPU NVIDIA nel cloud”.
Il Progetto Ceiba, una collaborazione tra Amazon Web Services (AWS) e NVIDIA, è destinato a rivoluzionare il mondo dell’intelligenza artificiale (AI) costruendo il più grande supercomputer AI nel cloud. Questo supercomputer all’avanguardia, ospitato esclusivamente su AWS, alimenterà gli sforzi di ricerca e sviluppo di NVIDIA nell’AI, spingendo i confini di ciò che è possibile in campi come i modelli di linguaggio di grandi dimensioni (LLM), la grafica, la simulazione, la biologia digitale, la robotica, i veicoli autonomi e la previsione climatica.

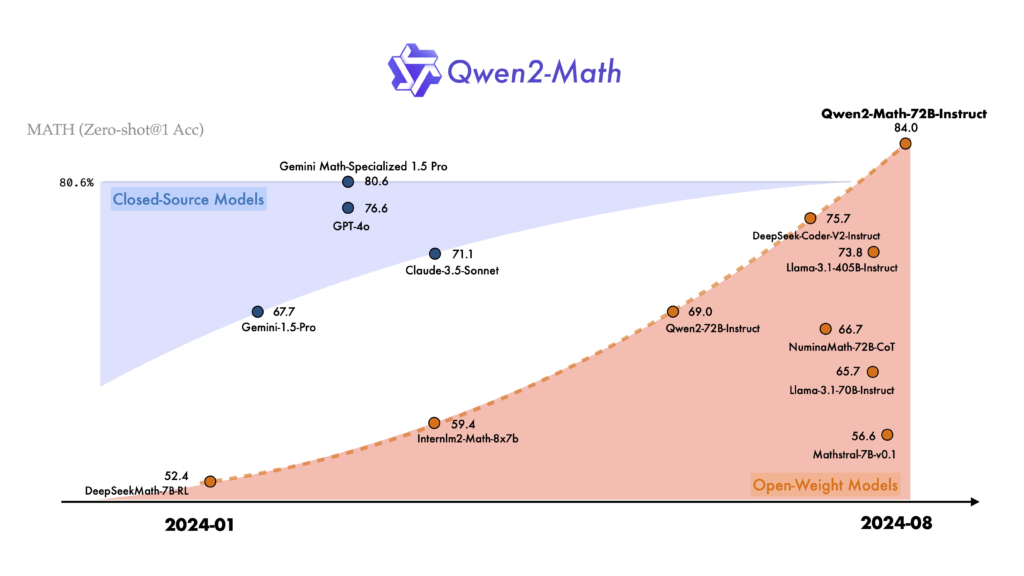
Negli ultimi anni, l’intelligenza artificiale ha fatto passi da gigante, specialmente nel campo dei modelli di linguaggio. Oggi, siamo entusiasti di presentare Qwen2-Math, una nuova serie di modelli linguistici specializzati nella risoluzione di problemi matematici complessi. Questi modelli si basano sulla robusta architettura di Qwen2 e sono progettati per superare le capacità matematiche di modelli precedenti, come GPT-4o.

Raspberry Pi ha recentemente lanciato il Raspberry Pi Pico 2, un microcontrollore avanzato basato sul chip RP2040, progettato per semplificare lo sviluppo di progetti hardware. Questa nuova versione mantiene le caratteristiche fondamentali del modello originale, ma offre miglioramenti significativi in termini di prestazioni e funzionalità.
Perplexity AI, una start-up innovativa nel settore della ricerca basata sull’intelligenza artificiale, sta cercando di sfidare il predominio di Google nel mercato della ricerca online. Con un modello di business in evoluzione e un significativo supporto finanziario, Perplexity si sta affermando come attore emergente in un panorama sempre più competitivo.
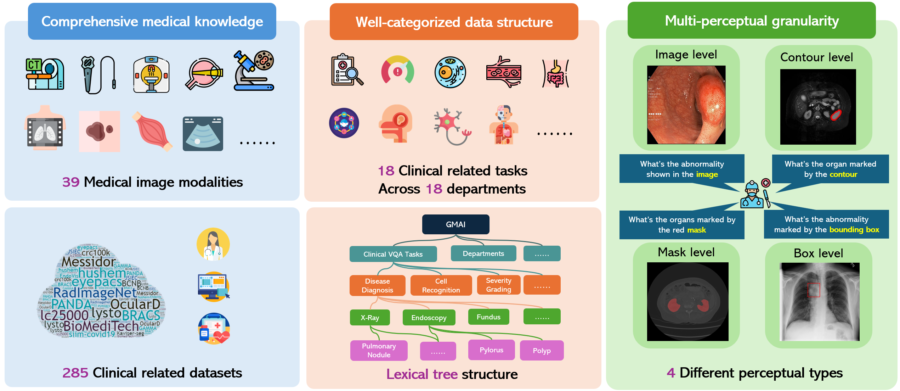
Un benchmark di valutazione multimodale completo verso l’intelligenza artificiale medica generale
GMAI-MMBench rappresenta un importante passo avanti nella valutazione delle intelligenze artificiali mediche generali. Questo benchmark multimodale è stato progettato per affrontare le sfide attuali nella valutazione delle capacità dei modelli di linguaggio visivo (LVLM) nel campo medico, fornendo una struttura di dati ben categorizzata e una granularità percettiva multi-livello.

GPT-2, il modello linguistico di OpenAI, ha suscitato grande interesse per le sue straordinarie capacità di generazione del linguaggio. Recentemente, è stata sviluppata un’interfaccia interattiva che permette di esplorare in tempo reale le previsioni di GPT-2 e la sua mappa dell’attenzione. Questo strumento innovativo offre uno sguardo affascinante sul funzionamento interno di questo modello di intelligenza artificiale.

Mistral AI ha recentemente annunciato importanti aggiornamenti per i suoi modelli di punta, Mistral Large 2 e Codestral, rendendo possibile una personalizzazione completa tramite “La Plateforme“. Questa novità offre agli sviluppatori la possibilità di adattare i modelli alle esigenze specifiche delle loro applicazioni.

Recentemente, Sam Altman, CEO di OpenAI, ha suscitato grande interesse con un tweet enigmatico in cui affermava: “Amo l’estate nel giardino”, accompagnato da un’immagine di fragole. Questo post è stato interpretato come un riferimento al progetto segreto di OpenAI noto come “Strawberry”, il cui sviluppo è stato rivelato da fonti giornalistiche come Reuters.

Mistral AI ha recentemente introdotto AGENTS, una nuova funzionalità progettata per migliorare l’automazione e la gestione del flusso di lavoro tramite agenti basati sull’intelligenza artificiale.
Questi agenti sono sistemi autonomi che sfruttano modelli linguistici di grandi dimensioni (LLM) per eseguire attività basate su istruzioni di alto livello, consentendo loro di pianificare, utilizzare strumenti e intraprendere azioni per raggiungere obiettivi specifici.
Una volta creati, gli agenti possono essere distribuiti e accessibili tramite un’API o tramite Le Chat, l’interfaccia di chat di Mistral.

OpenAI ha recentemente lanciato Neural Brush , uno strumento innovativo che promette di trasformare il panorama dell’arte digitale. Questo nuovo sistema utilizza tecnologie avanzate di generazione artificiale per consentire agli artisti di creare opere d’arte in modo interattivo e personalizzato, sfruttando un motore di generazione basato su GAN (Generative Adversarial Network).

In uno sviluppo rivoluzionario, Google DeepMind ha svelato un robot da ping-pong che ha raggiunto un traguardo notevole: vincere il 45% delle sue partite contro giocatori umani.
Questo risultato evidenzia progressi significativi nella robotica e nell’intelligenza artificiale, in particolare nel regno dello sport, dove la combinazione di strategia e agilità fisica è fondamentale.**** Panoramica delle prestazioniIl robot è stato testato in una serie di partite contro 29 giocatori umani, i cui livelli di abilità andavano da principiante ad avanzato.
Quest’anno il Cloud 100 Benchmark Report di Bessmer Venture Partner è stato la più competitiva di sempre, poiché le aziende continuano a rimanere private più a lungo dimostrando al contempo la capacità di sostenere la crescita su larga scala.
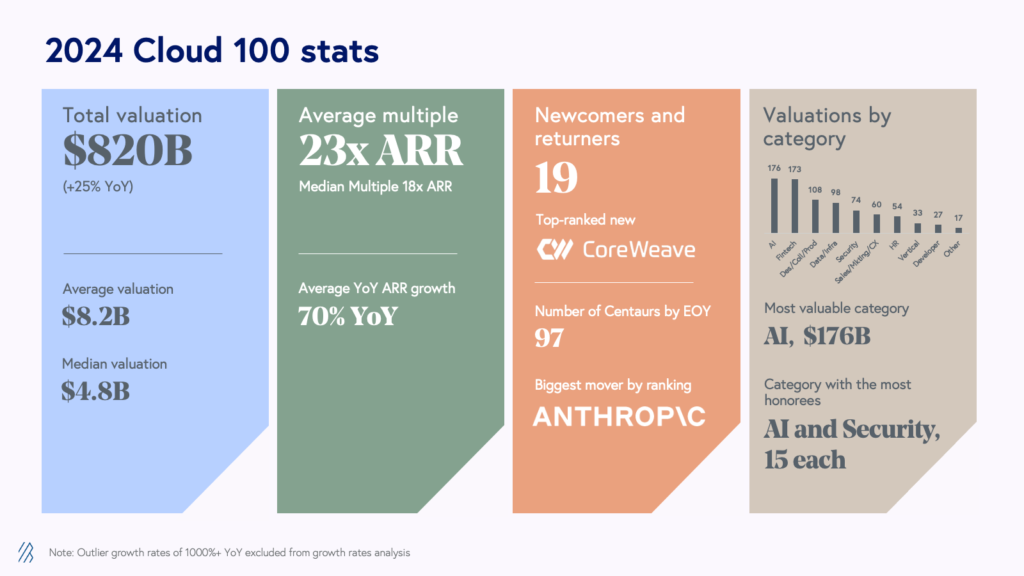
Tornando per la sua nona edizione, Bessemer Venture Partners, Forbes e Salesforce Ventures hanno rilasciato la Lista Cloud 100 del 2024, la classifica definitiva delle 100 migliori aziende cloud private al mondo. Dopo un dinamico 2023 in cui abbiamo visto il valore della lista Cloud 100 contrarsi per la prima volta anno su anno, la coorte del Cloud 100 del 2024 stabilisce molteplici record, dimostrando la resilienza delle aziende cloud nell’affrontare questi tempi incerti.

MedTrinity-25M rappresenta un’importante innovazione nel campo dell’intelligenza artificiale medica, lanciando un dataset che include oltre 25 milioni di immagini mediche relative a 65 malattie. Questo dataset è uno dei più ampi mai creati, fornendo una risorsa preziosa per la ricerca e lo sviluppo nell’ambito della salute.

JP Morgan Payments, una divisione di JPMorgan Chase, ha annunciato l’espansione della sua collaborazione con PopID per l’avvio di un programma pilota che permetterà agli acquirenti di effettuare pagamenti tramite riconoscimento facciale presso alcuni commercianti negli Stati Uniti.

Meta, leader nel settore tecnologico, ha recentemente annunciato l’apertura delle candidature per il programma Llama 3.1 Impact Grants, un’iniziativa ambiziosa volta a supportare gli utilizzi più innovativi dell’intelligenza artificiale open source a beneficio della società.
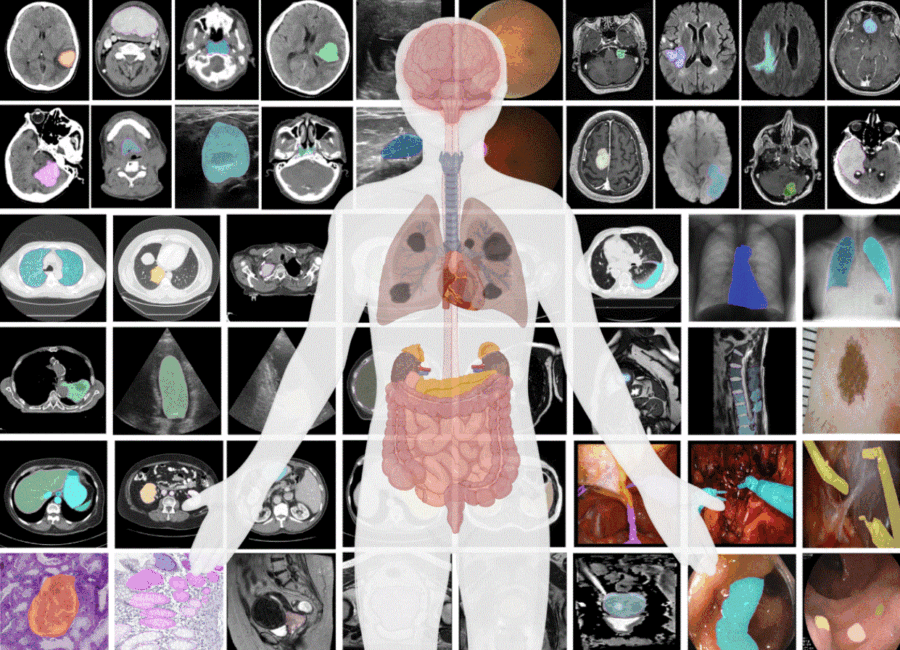
Negli ultimi anni, il campo dell’imaging medico ha visto progressi straordinari, e uno dei più significativi è rappresentato dal modello MedSAM-2 (Medical Segment Anything Model 2). Questo innovativo strumento di segmentazione delle immagini mediche sta cambiando il modo in cui i professionisti della salute analizzano e interpretano le immagini diagnostiche, portando a diagnosi più rapide e precise. (disponibile su GitHub)

OpenAI sta attualmente adottando un approccio cauto e metodico per il rilascio del suo nuovo strumento progettato per rilevare il testo generato da ChatGPT. Questo strumento, che utilizza una tecnica di watermarking del testo, ha mostrato risultati promettenti, raggiungendo un’accuratezza di rilevamento del 99,9% in condizioni ottimali. Tuttavia, OpenAI sta valutando le potenziali implicazioni del suo rilascio, in particolare riguardo al suo impatto sugli utenti e sull’ecosistema più ampio (Wall Street Journal).