VidAU è una piattaforma innovativa che semplifica la creazione di video coinvolgenti utilizzando link o descrizioni di prodotti, grazie a avatar realistici che parlano in diverse lingue e accenti.
Con una suite completa di strumenti di editing video, come scambio di volti e traduzione, VidAU sta rapidamente guadagnando popolarità tra aziende e piattaforme di e-commerce, migliorando l’efficienza del content marketing e i tassi di conversione.
Nell’era digitale, l’originalità dei contenuti è diventata un aspetto cruciale per editori, scrittori e creatori di contenuti. Con l’aumento della produzione di contenuti online, garantire che un testo sia autentico e non copiato è fondamentale per mantenere la credibilità e l’integrità. È qui che entra in gioco Originality.ai, una piattaforma innovativa progettata per rilevare il plagio e l’originalità dei contenuti.
Originality.ai è stata fondata da Jon Gillham dopo aver venduto un’agenzia di content marketing che aveva fondato in precedenza. L’azienda si concentra sulla fornitura di strumenti per rilevare il contenuto generato dall’IA e garantire l’integrità del contenuto.
Google ha lanciato la versione beta del suo nuovo strumento di creazione video basato sull’intelligenza artificiale generativa,
Google Vids, per alcuni utenti selezionati della sua suite di applicazioni Workspace per le aziende.
Vids è un’app di creazione video alimentata dall’AI, progettata per l’uso professionale e profondamente integrata con gli strumenti di produttività di Google Workspace che gli utenti aziendali utilizzano quotidianamente.
Nel corso dell’ultimo anno, Be My Eyes ha stretto una partnership innovativa con OpenAI, integrando il potente modello di intelligenza artificiale (AI) di quest’ultima nella sua app, offrendo così un’assistenza visiva non più fornita da un volontario umano, ma da un sofisticato sistema AI. Questa collaborazione segna un passo significativo nell’uso della tecnologia per migliorare la qualità della vita delle persone non vedenti e ipovedenti.
Gli ingegneri in Cina hanno costruito un cane computerizzato che potrebbe fornire un’alternativa pratica ai veri cani guida. Guide Dog Robot (GDR)
I ricercatori cinesi stanno sviluppando un robot “cane guida” a sei zampe con l’obiettivo di assistere le persone non vedenti per aumentarne l’autonomia. Questo innovativo robot, attualmente in fase di test sul campo, si affida a telecamere e sensori per manovrare attraverso l’ambiente circostante, riuscendo persino a identificare i segnali del traffico – un compito al di là delle capacità dei tradizionali cani guida.
L’avvento dell’intelligenza artificiale generativa ha aperto nuove possibilità affascinanti, permettendo la creazione di immagini, video e audio realistici tramite strumenti come ChatGPT e DALL-E. Tuttavia, sfruttare appieno il potenziale di questi strumenti AI non è sempre semplice. La chiave risiede nell’abilità di “prompt engineering“, ovvero la capacità di creare prompt precisi e ben strutturati per ottenere i risultati desiderati.
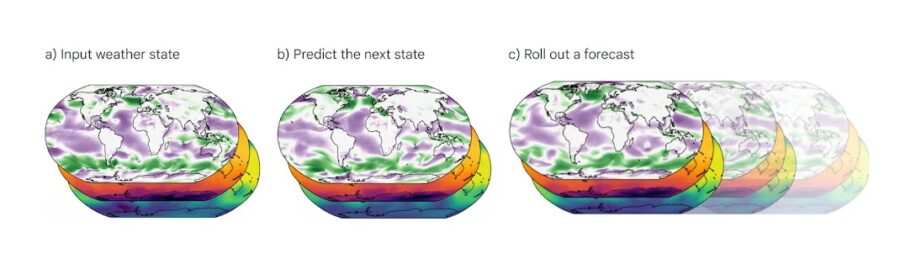
Google DeepMind, la divisione di intelligenza artificiale di Google, ha vinto il prestigioso MacRobert Award 2024 per il suo innovativo sistema di previsioni meteo chiamato GraphCast. Questo modello di IA è in grado di fornire previsioni meteo a 10 giorni con una precisione senza precedenti, in meno di un minuto di calcolo.
Caratteristiche chiave di GraphCast:
Previsioni a 10 giorni con risoluzione di 0,25 gradi (circa 28 km), coprendo l’intero pianeta
Predice 5 variabili meteo a livello del suolo e 6 variabili atmosferiche a 37 diversi livelli di altitudine
Supera del 90% le prestazioni del precedente sistema di riferimento HRES per la maggior parte delle variabili
Esegue le previsioni in meno di 1 minuto, contro le ore richieste dai sistemi tradizionali su supercomputer
Rispetto ad altre app meteo popolari come Dark Sky, AccuWeather e WeatherBug, GraphCast offre previsioni molto più accurate e dettagliate, con un orizzonte temporale molto più esteso. Inoltre, essendo un modello open source, può essere ulteriormente sviluppato e adattato da ricercatori e sviluppatori di tutto il mondo.
Questo riconoscimento dimostra come l’IA stia rivoluzionando il campo della meteorologia, offrendo strumenti molto più potenti ed efficienti rispetto ai metodi tradizionali. Mentre i modelli IA come GraphCast non sono ancora perfetti (ad esempio hanno difficoltà con le previsioni di eventi meteorologici estremi), i progressi compiuti sono davvero impressionanti. In futuro, possiamo aspettarci che l’IA giochi un ruolo sempre più centrale nelle previsioni meteo, a beneficio di moltissimi settori economici e della vita quotidiana delle persone.
Come abbiamo scritto nel mese scorso, la comunità di utenti di Stable Diffusion è stata scossa da una serie di polemiche innescate dalle nuove condizioni di licenza imposte da Stability AI per il suo modello di intelligenza artificiale, Stable Diffusion 3 (SD3). Queste restrizioni hanno suscitato un’ondata di proteste e malcontento tra gli utenti, costringendo l’azienda a fare marcia indietro su alcune delle sue decisioni. La situazione ha raggiunto un punto di svolta venerdì sera, quando Stability AI ha annunciato di aver allentato alcune delle sue condizioni, nel tentativo di placare le tensioni. Tuttavia, questa mossa ha generato reazioni contrastanti all’interno della comunità.
NTT DATA Italia ha recentemente annunciato il programma Artificial Intelligence Metamorphosis, che punta a rivoluzionare il lavoro delle imprese italiane con l’Intelligenza Artificiale (AI).
L’obiettivo è trasformare l’intera organizzazione aziendale – dal modello interno ai modelli di business e all’offerta per i clienti – superando il semplice concetto di riduzione dei costi e migliorando le performance, esplorando nuove possibilità grazie all’AI.
Questa iniziativa fa parte di una strategia globale che dal 1° Aprile ha unito le attività di NTT DATA e NTT Ltd. in NTT DATA Inc., un colosso con oltre 190.000 dipendenti in più di 50 paesi e ricavi superiori ai 30 miliardi di dollari.
Questa integrazione offre un vantaggio competitivo alla multinazionale giapponese, ora con un’offerta di trasformazione AI end to end che include consulenza, infrastrutture – Data Center e connettività – soluzioni digitali e servizi gestiti.
Ne abbiamo parlato con Nicola Russo, Head of Data&Intelligence and Head of AI Metamorphosis Program.
Progressi nell’apprendimento automatico classico e l’emergere dell’apprendimento automatico quantistico
L’apprendimento automatico (ML) classico, un sottoinsieme dell’intelligenza artificiale, è evoluto significativamente dalla sua nascita negli anni ’60. Dall’iniziale riconoscimento di modelli semplici all’attuale utilizzo di enormi dataset per l’addestramento e la generazione di previsioni altamente accurate, l’ML si è dimostrato uno strumento potente in vari settori. Tuttavia, la crescita esponenziale dei dati ha messo in svantaggio i computer classici, poiché si prevede che i sistemi quantistici gestiranno tali scale massicce in modo più efficiente in futuro. Ciò ha portato allo sviluppo dell’apprendimento automatico quantistico (QML), che è destinato a portare significativi progressi nell’ML.
La generazione di intelligenza artificiale (GenAI) e le reti di comunicazione wireless sono destinate ad avere sinergie rivoluzionarie nella rete 6G. Connettendo gli agenti GenAI attraverso una rete wireless, si può potenzialmente liberare la potenza dell’intelligenza collettiva e aprire la strada all’intelligenza artificiale generale (AGI). Tuttavia, le attuali reti wireless sono progettate come un “tubo di dati” e non sono adatte ad accogliere e sfruttare la potenza della GenAI.
I ricercatori di DeepMind, la divisione di Google dedicata all’intelligenza artificiale, hanno recentemente svelato un nuovo metodo per accelerare l’addestramento dell’intelligenza artificiale (IA). Questa innovativa tecnica promette di ridurre significativamente le risorse computazionali e il tempo necessari per addestrare i modelli di IA, rendendo così lo sviluppo di queste tecnologie più veloce ed economico.
In un mondo sempre più dominato dalle intelligenze artificiali, una nuova e promettente alternativa si fa strada: Moshi. Annunciato dal laboratorio francese di intelligenza artificiale Kyutai, Kyutai è co-fondato da Xavier Niel, fondatore e azionista di maggioranza del gruppo Iliad, Moshi si propone come una versione avanzata e multimodale delle attuali tecnologie linguistiche, come il celebre GPT-4.
In soli 6 mesi, con un team di 8 persone, il laboratorio di ricerca Kyutai ha sviluppato da zero un modello di intelligenza artificiale (AI) con capacità vocali senza precedenti chiamato Moshi
comunicato stampa in allegato
Questa innovativa piattaforma non solo promette di rivoluzionare il modo in cui le macchine interagiscono con il mondo, ma anche di superare le attuali limitazioni dei modelli basati esclusivamente su testo. Moshi presenta ancora alcune limitazioni. Attualmente l’assistente supporta solo la lingua inglese.
Il “State of AI Report H1 2024” di Retool offre una panoramica dettagliata sull’adozione e l’uso dell’intelligenza artificiale (AI) nel settore tecnologico nella prima metà del 2024. Il rapporto esamina vari aspetti dell’AI, tra cui le tendenze nelle applicazioni aziendali, l’adozione delle tecnologie AI, i casi d’uso principali e le sfide affrontate dalle aziende.
Presentazione di Apple Vision Pro con funzionalità AI
L’attesissimo visore per realtà mista di Apple, Vision Pro, è destinato a portare l’elaborazione spaziale a nuovi livelli con l’integrazione della più recente tecnologia di intelligenza artificiale (AI) dell’azienda.
Mentre Apple Intelligence, la piattaforma AI del gigante della tecnologia, era stata inizialmente annunciata per i recenti computer Mac e iPhone 15 Pro, un nuovo rapporto di Bloomberg suggerisce che Apple sta lavorando attivamente per portare queste funzionalità AI avanzate anche su Vision Pro.
Vision Pro, presentato da Apple a giugno 2023, è un rivoluzionario computer spaziale che fonde perfettamente i contenuti digitali con il mondo fisico.
Grazie al visionOS personalizzato dell’azienda, il visore offre agli utenti una tela infinita per le app, esperienze di intrattenimento immersive e la possibilità di catturare e rivivere i ricordi in modo veramente tridimensionale.
Il modello Gen-3 Alpha di Runway, disponibile al pubblico dal 1° luglio 2024, rappresenta un grande passo avanti nella generazione di video con intelligenza artificiale. Accessibile con un abbonamento a partire da $12 al mese, questo modello avanzato permette di creare video ad alta fedeltà, coerenti e controllabili tramite prompt di testo, immagine o video, diventando uno strumento prezioso per registi, creatori di contenuti e altri professionisti creativi.
La condivisione di Ophira Orwits su Twitter riguardo alla tecnica di many-shot jailbreaking è un richiamo all’azione per la comunità AI.
Mentre l’intelligenza artificiale continua a progredire e a diventare sempre più integrata nelle nostre vite quotidiane, è essenziale affrontare le vulnerabilità e garantire che i modelli siano sicuri e affidabili. La collaborazione tra ricercatori, sviluppatori e responsabili delle politiche sarà cruciale per affrontare queste sfide e migliorare la sicurezza dei modelli linguistici, proteggendo così gli utenti e la società nel suo complesso.
Ci auguriamo che la pubblicazione sul jailbreaking many-shot incoraggi gli sviluppatori di LLM potenti e la comunità scientifica più ampia a considerare come prevenire questo jailbreak e altri potenziali exploit della finestra di contesto lunga. Man mano che i modelli diventano più capaci e hanno più potenziali rischi associati, è ancora più importante mitigare questo tipo di attacchi.
Google ha mantenuto la promessa di aprire al pubblico il suo modello AI più potente, Gemini 1.5 Pro, dopo la versione beta del mese scorso per gli sviluppatori. L’azienda ha recentemente annunciato l’integrazione di Gemini 1.5 Pro nell’app NotebookLM, destinata a ricercatori, studenti e altri utenti che necessitano di organizzare informazioni.
OpenAI ha presentato CriticGPT, un nuovo modello di intelligenza artificiale basato su GPT-4 progettato per identificare errori nel codice generato da ChatGPT, segnando un passo significativo verso il miglioramento della precisione e dell’affidabilità degli output generati dall’intelligenza artificiale, ricorda il personaggio Grillo di Pinocchio, Jiminy Cricket.
Il nuovo modello di intelligenza artificiale chiamato EMethylNET è in grado di rilevare 13 diversi tipi di cancro con una precisione del 98,2% utilizzando solo dati di metilazione del DNA da campioni di tessuto.[1] Questo modello di IA è stato sviluppato dai ricercatori dell’Università di Cambridge nel Regno Unito e potrebbe potenzialmente accelerare la diagnosi precoce, la diagnosi e il trattamento del cancro.
Intel ha presentato mercoledì il primo chiplet di interconnessione di calcolo ottico completamente integrato da utilizzare nell’intelligenza artificiale Il chiplet, noto come OCI, è assemblato con una CPU Intel e esegue dati in tempo reale.
La necessità di un Modello di Fondazione nella Previsione delle Serie Temporali
La previsione delle serie temporali gioca un ruolo cruciale in numerosi ambiti, dal piano della domanda nel retail e la previsione dei mercati finanziari fino alla meteorologia e alla gestione del traffico.
Indigo.ai è una startup italiana che si occupa di intelligenza artificiale (IA) e ha sviluppato una piattaforma per progettare assistenti virtuali, tecnologie di linguaggio e chatbot. La piattaforma “no-code” permette a chiunque in azienda di creare assistenti virtuali di ultima generazione, aumentando le vendite, migliorando la relazione con gli utenti e ottenendo insight sulla propria base clienti.
Leonardo AI, un potente generatore di immagini basato sull’intelligenza artificiale, ha recentemente lanciato un nuovo modello che promette di rivoluzionare la creazione di contenuti visivi. Questo strumento, noto per la sua versatilità e capacità di generare immagini di alta qualità, si è guadagnato una reputazione tra gli artisti e gli utenti di contenuti digitali.
La Trustworthy AI (TAI) è l’Intelligenza Artificiale sostenibile, affidabile, di cui ci si può fidare, che promuove il benessere degli esseri umani e dell’ambiente e rispetta i diritti umani fondamentali. È diventata una necessità sempre più urgente, poiché sulla fiducia si costruiscono le fondamenta delle società, delle economie e del loro sviluppo sostenibile.
L’intelligenza artificiale (AI) si concentra su elementi chiave come il ragionamento, la pianificazione e l’utilizzo di strumenti specifici, che sono essenziali per l’applicazione dell’AI in contesti complessi.
Una ricerca condotta da Tula Masterman (Neudesic) e colleghi ha evidenziato come gli agenti AI siano in grado di raggiungere obiettivi complessi.
Google DeepMind ha annunciato un modello di intelligenza artificiale chiamato V2A (video-to-audio) che può generare audio sincronizzato, compresi musica, effetti sonori e dialoghi, per input video. Questa tecnologia si propone di migliorare la realtà virtuale dei video generati da AI mediante la creazione di soundtrack appropriati direttamente dai pixel del video, senza bisogno di allineamento manuale o descrizioni di testo.
Generare Dati Sintetici con Nemotron-4 340B di NVIDIA
NVIDIA ha recentemente annunciato il rilascio di Nemotron-4 340B, una famiglia rivoluzionaria di modelli progettati per generare dati sintetici per l’addestramento di modelli di linguaggio su larga scala (LLM) in vari ambiti commerciali. Questo lancio rappresenta un importante passo avanti nell’intelligenza artificiale generativa, offrendo un insieme completo di strumenti ottimizzati per NVIDIA NeMo e NVIDIA TensorRT-LLM, inclusi modelli all’avanguardia per istruzioni e ricompense.
Luma AI (ne avevamo scritto recentemente) è una startup fondata nel 2021 con sede a San Francisco, che si concentra sulla creazione di tecnologia di intelligenza artificiale per generare contenuti 3D realistici da promemoria di testo o immagini. Il team di Luma AI è composto da esperti in campo di visione computerizzata, grafica e apprendimento automatico, con una visione condivisa di democratizzare la creazione di contenuti 3D attraverso l’IA. LUMA AI offre un’interfaccia intuitiva che consente agli utenti di creare contenuti 3D senza bisogno di formazione specializzata o attrezzature costose.
La ricerca recente sul campo dell’intelligenza artificiale (IA) ha visto un aumento significativo dell’attenzione verso l’utilizzo di modelli di linguaggio per compiti clinici.
Tuttavia, i dispositivi mobili e indossabili, come ad esempio dispositivi di monitoraggio della salute, forniscono dati longitudinali ricchi e personalizzati che possono essere utilizzati per monitorare la salute personale. In questo contesto, gli autori presentano il Personal Health Large Language Model (PH-LLM), un modello di linguaggio fine-tunato per comprendere e ragionare su dati di serie temporali numerici relativi alla salute personale.
Luma AI ha recentemente lanciato Dream Machine, un sistema di generazione di video basato sull’intelligenza artificiale che consente di creare scene realistiche e fantastiche da istruzioni di testo e immagini. Questo strumento, diverso da altri come Sora, è completamente aperto e disponibile per l’utilizzo gratuito da parte di tutti.
Stability AI ha annunciato l’uscita di Stable Diffusion 3 (SD3), il generatore di immagini più potente e open-source disponibile attualmente. Questo modello di intelligenza artificiale (IA) è stato progettato per generare immagini realistiche e dettagliate da descrizioni testuali, superando i migliori generatori di immagini AI esistenti per capacità di realismo fotografico.
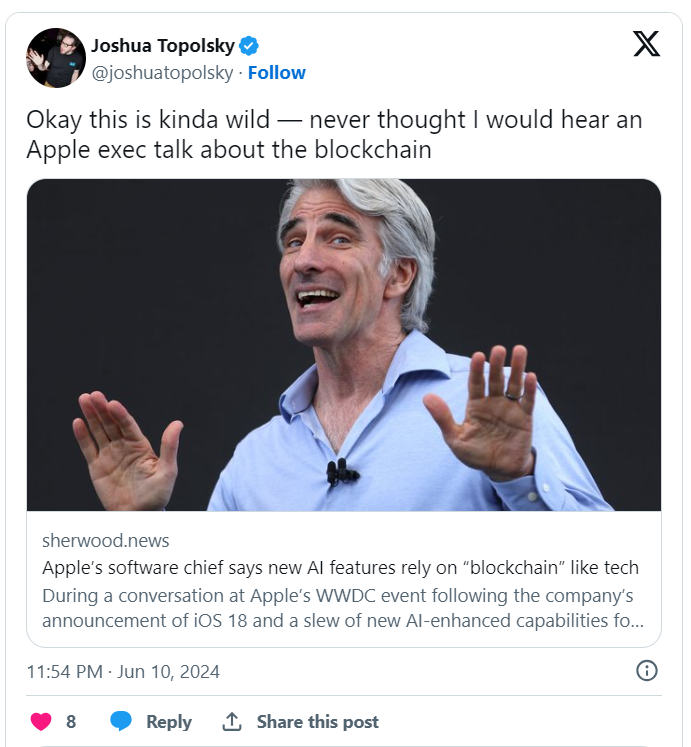
Apple sta sviluppando l’intelligenza artificiale con la sua nuova suite di funzionalità Apple Intelligence su iPhone, iPad e Mac. Alcune richieste, con il permesso dell’utente, saranno inviate a ChatGPT di OpenAI.
Un dirigente afferma che i servizi di intelligenza artificiale di Apple usano un modello “blockchain” per garantire la privacy.
Dopo la presentazione di Apple, il vicepresidente senior dell’ingegneria del software Craig Federighi e il vicepresidente senior della strategia di machine learning e intelligenza artificiale John Giannandrea hanno parlato alla stampa insieme a Justine “iJustine” Ezarik.
Alla domanda su come Apple protegge la privacy dei clienti, Federighi ha detto che le richieste inviate ai server Apple sono anonime, con IP mascherati e senza registrazione delle informazioni.
Inoltre, il software del server sarà pubblico per la verifica da parte di ricercatori indipendenti, e i dispositivi interagiranno solo con server verificabili. Apple Intelligence è il sistema di intelligenza personale che porta potenti modelli generativi su iPhone, iPad e Mac.
Per funzionalità avanzate, abbiamo creato Private Cloud Compute (PCC), un sistema di intelligenza cloud progettato per l’elaborazione AI privata.
Molte altre aziende cinesi, dai più grandi giganti della tecnologia a una miriade di start-up, hanno fatto passi avanti nei propri sforzi di sviluppo LLM. Alibaba Cloud ha rilasciato Qwen2, la seconda versione della sua famiglia di modelli linguistici Tongyi Qianwen open source, utilizzata in chatbot come ChatGPT di OpenAI.
Include aggiornamenti come pre-formazione multilingue e una finestra di contesto ampliata, permettendo domande e risposte più lunghe, posizionandosi tra i LLM open source più potenti al mondo, include Tongyi Qianwen LLM, il modello di visione AI Qwen-VL e Qwen-Audio.
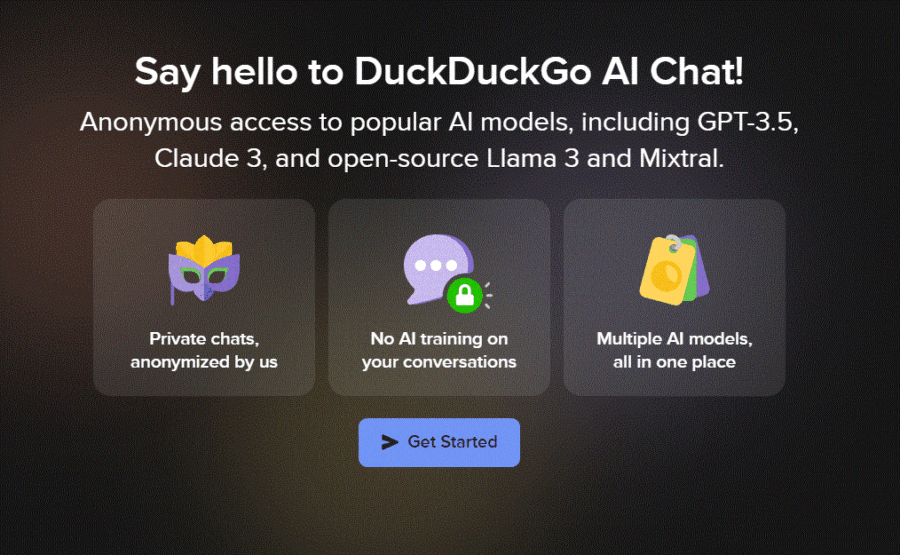
DuckDuckGo, noto per il suo motore di ricerca e browser web incentrato sulla privacy, ha lanciato un nuovo servizio che permette agli utenti di interagire con chatbot AI in modo privato e anonimo.
Il servizio, chiamato DuckDuckGo AI Chat e accessibile su Duck.ai, è disponibile a livello globale.
Raspberry Pi Foundation. Il piccolo e conveniente Raspberry Pi ha creato una grande comunità di fai-da-te, che usa questi computer delle dimensioni di una carta di credito per vari scopi, dai media center ai nodi Bitcoin. Raspberry Pi è molto usato per insegnare ai bambini a costruire e programmare computer, oltre che per altri progetti.
Realizzato in collaborazione con lo sviluppatore di processori di intelligenza artificiale Hailo, il kit AI Raspberry Pi è ora disponibile per l’aggiornamento del Raspberry Pi 5 e viene venduto al prezzo di $70, come dichiarato dall’organizzazione di beneficenza britannica.
In un’era in cui la tecnologia ha rivoluzionato il modo in cui interagiamo gli uni con gli altri, il concetto di “mind network” è diventato sempre più rilevante. Questa innovativa idea prevede un sistema interconnesso a livello globale in cui gli individui possono condividere e scambiare pensieri, emozioni ed esperienze in modo fluido, superando barriere geografiche e linguistiche.
In questo articolo esploreremo il concetto di mind network, i suoi potenziali benefici e gli avanzamenti tecnologici che lo stanno rendendo una realtà.
Text to Sound è qui. Il più recente modello Audio AI può generare effetti sonori, brevi tracce strumentali, paesaggi sonori e una vasta gamma di voci di personaggi, tutto da un prompt di testo.
Perplexity AI ha rivoluzionato il modo in cui scopriamo e condividiamo informazioni. Questa innovativa piattaforma non solo risponde alle domande, ma dà agli utenti il potere di esplorare gli argomenti in profondità, riassumere i contenuti e persino creare articoli lunghi. In questo articolo, approfondiremo le funzionalità e le capacità di Perplexity page, evidenziando il suo potenziale per trasformare il modo in cui interagiamo con la conoscenza.
Man mano che il campo dell’analisi finanziaria continua a evolversi, l’integrazione di modelli linguistici avanzati nel toolkit dei professionisti e dei ricercatori finanziari potrebbe portare a progressi significativi nella nostra comprensione delle prestazioni aziendali e dei driver dei rendimenti del mercato azionario.