
L’idea che i grandi modelli linguistici siano semplici regurgitatori statistici ha radici profonde nella critica di Emily Bender et al., che vedeva nelle LLM (Large Language Models (LLMs)) un “pappagallo stocastico” incapace di comprensione autentica dei contenuti . Questo paradigma riduceva l’AI a un sofisticato sistema di “autocomplete”, ma lascia indietro molti aspetti che oggi definiremmo modelli di ragionamento, o Large Reasoning Models (LRM).
Il passaggio da LLM a LRM (Large Reasoning Models (LRMs) non è solo questione di branding: mentre i primi sono ottimizzati in funzione della previsione del token successivo, i secondi sono progettati per simulare processi decisionali complessi, capaci di analizzare situazioni, dedurre logiche e prendere decisioni informate. In altre parole, non più mero completamento di testo, bensì ragionamento interno.

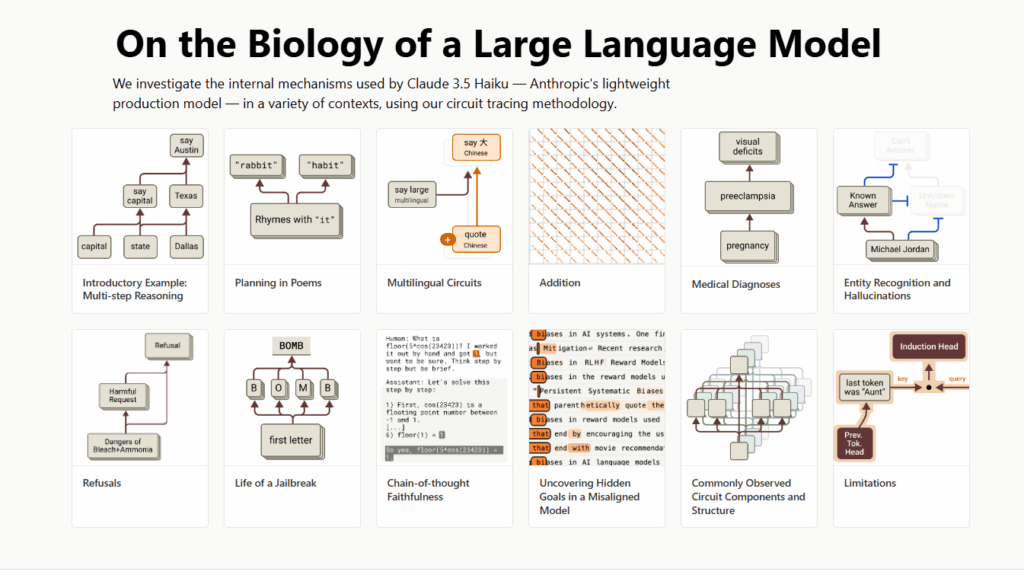
Anthropic ha offerto la dimostrazione più chiara con il paper “Tracing the thoughts of a large language model”, pubblicato il 27 marzo 2025 Home. Attraverso tecniche di interpretabilità simili a una “microscopia” sui circuiti interni di Claude, gli ingegneri hanno scoperto che il modello non si limita a un calcolo sequenziale di probabilità, ma elabora concetti in uno spazio condiviso fra diverse lingue, pianifica rime con anticipo e segue percorsi paralleli per compiti anche matematici.
La scienza dietro gli LRM si fonda sul concetto di interpretabilita meccanistica, un campo in rapida crescita che mira a mappare i circuiti interni dei modelli linguistici giganteschi per scoprire come emergano concetti e algoritmi dentro reti neurali dense di miliardi di parametri. Anthropic ha applicato tecniche di “circuit tracing” per isolare gruppi di neuroni che rappresentano caratteristiche specifiche, chiamate feature, e per collegarle in strutture algoritmiche, dette circuiti, che orchestrano compiti complessi come la rima o il calcolo matematico in piu fasi.
Per la poesia, Claude non aspetta di arrivare all’ultimo verso per scegliere una rima: elabora in anticipo possibili terminazioni sensate e poi compone il verso sulla base di quella pianificazione. Nelle operazioni di calcolo, emergono percorsi distinti per l’approssimazione e per la precisione, che si combinano per restituire il risultato esatto senza aver memorizzato formulette a tavolino . Anche nei ragionamenti in più fasi, come nel domandare “Qual è il capoluogo dello stato dove si trova Dallas?”, Claude attiva prima il concetto “Dallas è in Texas” e poi “capoluogo del Texas è Austin”, dimostrando di concatenare fatti indipendenti Home.
Il risultato è evidente: la macchina non si limita più a un’autocomplete evoluto, ma mostra i segni di processi interni simili a quelli del pensiero umano. Grazie agli LRM, il “pappagallo stocastico” diventa un interprete di concetti, un pianificatore e un ragionatore, segnando il tramonto dell’AI come semplice completatore di frasi.
La comunita di esperti reagisce con entusiasmo ma anche con sano scetticismo. Chris Olah di Anthropic parla di un nuovo “microscopio” per l’AI capace di mostrare algoritmi nascosti e auspica di estendere il metodo a tutta la computazione del modello, per garantire maggiore sicurezza e affidabilita. Al contrario, critici come Gary Marcus liquidano l’iniziativa come mossa di marketing piu che come rigore scientifico, sostenendo che la capacita di manipolare singoli neuroni non prova una comprensione autentica, ma solo un’illusione di controllo,
Sul forum Hacker News alcuni commentatori definiscono le sintesi giornalistiche del paper troppo semplificate e invitano a leggere direttamente i dati grezzi per valutarne le reali potenzialita
In realta il dissenso non mina il modello LRM ma ne sottolinea i limiti e le sfide future: l’interpretabilita meccanistica copre solo una piccola frazione del calcolo totale e richiede ore di lavoro umano per decifrare ogni circuito, rendendo urgente l’automazione del processo.
Altri gruppi di ricerca, da DeepMind alle universita di Northeastern, stanno esplorando approcci analoghi evolvendo la monosemanticita e creando tool di visualizzazione delle attivazioni neurali. Questa frontiera scientifica sembra indicare che l’AI smette di essere un mero completatore di frasi e diventa un laboratorio di ragionamento interno, anche se i veri algoritmi restano ancora in parte celati alla nostra osservazione.