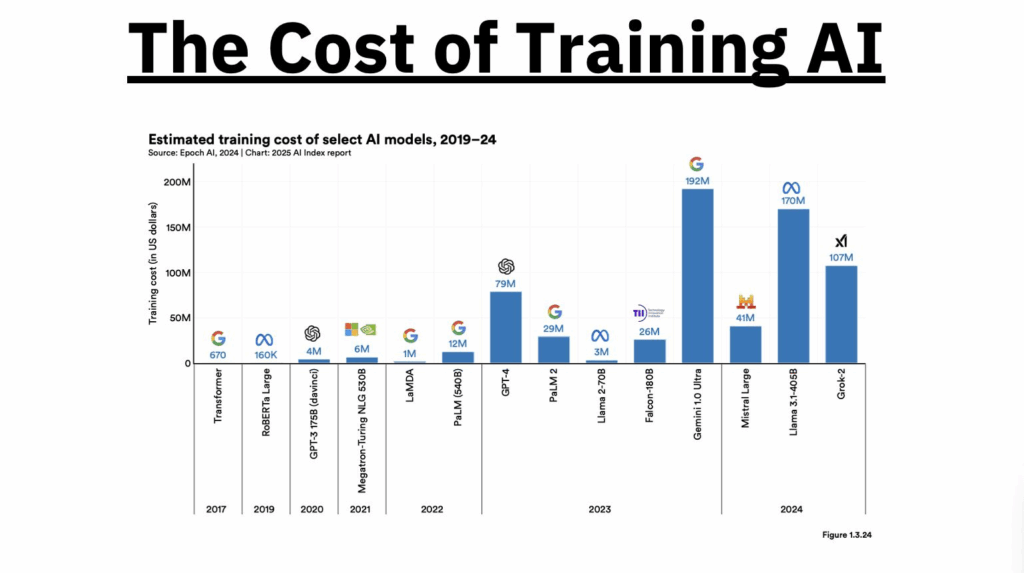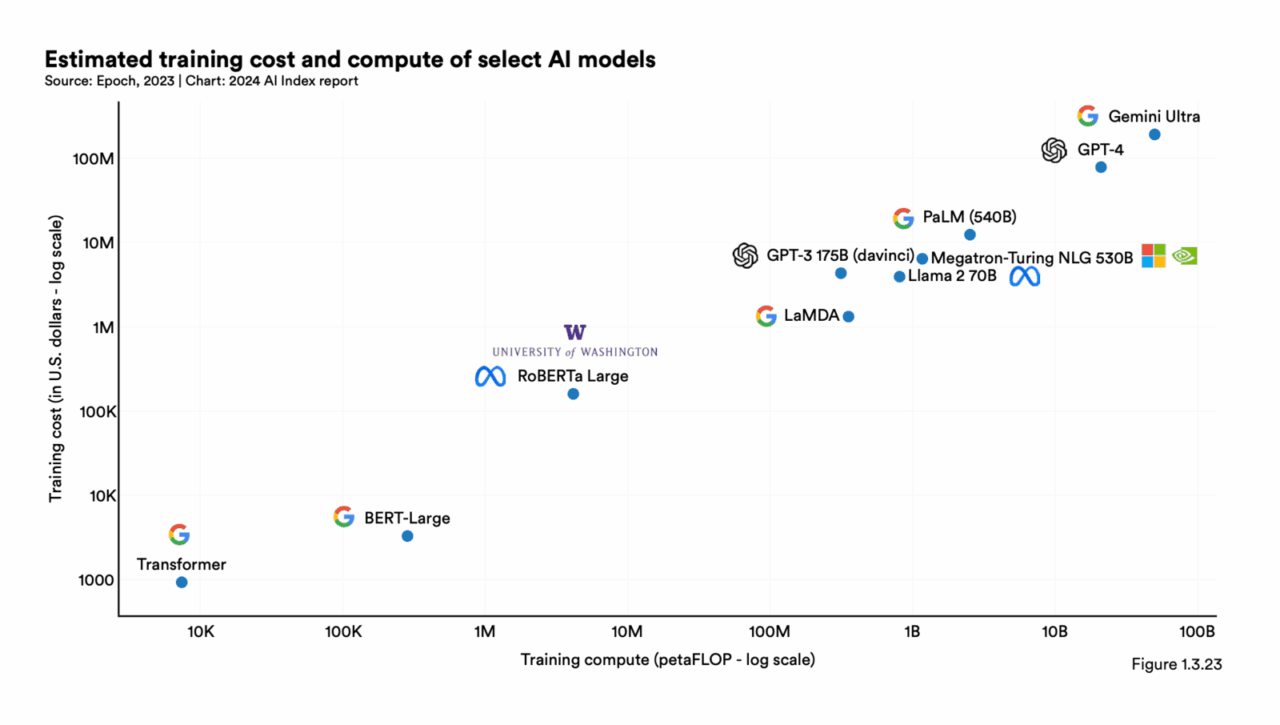
Nel 2017 bastavano 930 dollari per addestrare un Transformer. Nel 2025, con Llama 3.1 e Gemini 1.0 Ultra, si parla di 170 e 192 milioni rispettivamente. No, non è un errore di battitura, ed è inutile controllare il cambio con lo yen: siamo entrati nell’era dell’AI capitalistica pesante, dove l’unico modello che puoi permetterti di addestrare da solo è quello mentale per accettare che il tuo progetto AI non sarà mai competitivo senza il backing di un hyperscaler o un fondo VC dal pedigree siliconvalleyano.
Il motivo? Non è magia nera, è economia industriale in stile XXI secolo. Addestrare un Large Language Model oggi è come costruire un acceleratore di particelle che però sputa fuori email più eleganti e assistenti virtuali meno idioti. Ecco dove vanno quei milioni.
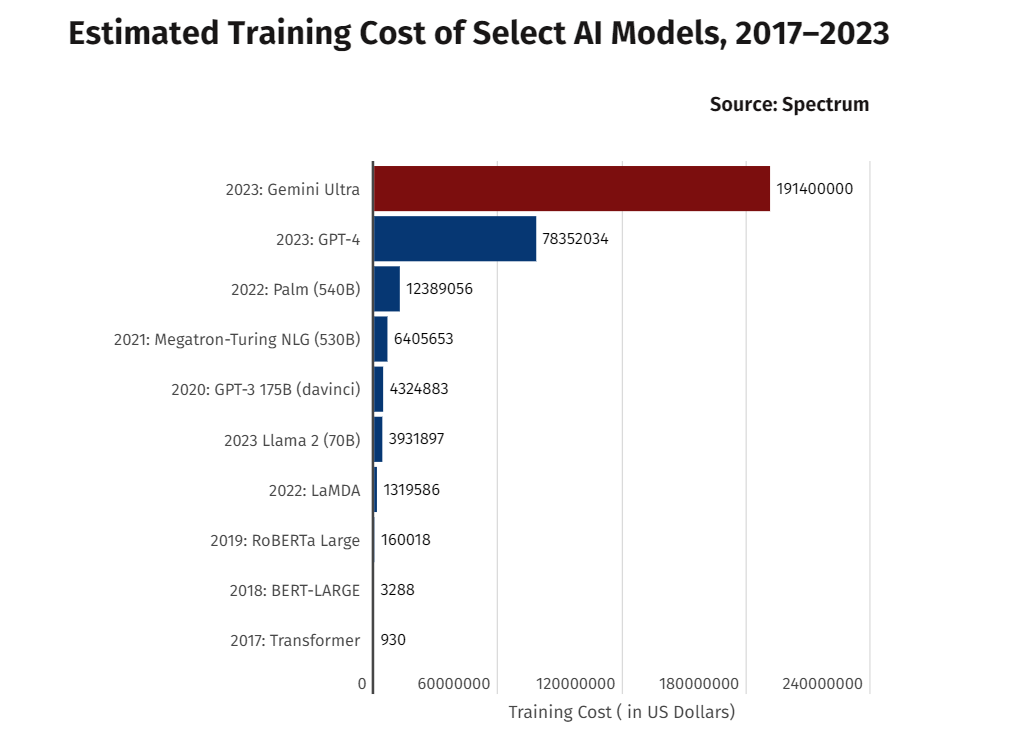
Cominciamo dai dati, la materia prima di ogni AI. Ma non stiamo parlando di due subreddit e una manciata di articoli di Wikipedia. Ci vogliono terabyte, a volte petabyte, di testi, codici, dialoghi e altre forme di linguaggio umano. Raccolti, filtrati, annotati, puliti. E siccome una AI è tanto intelligente quanto i dati su cui è stata addestrata, ogni frase inutile o tossica che entra nel dataset è una futura allucinazione in produzione. Il processo non è solo lungo: è costoso, perché richiede storage, ingegneri e, sempre più spesso, anche licenze per l’uso di contenuti protetti.
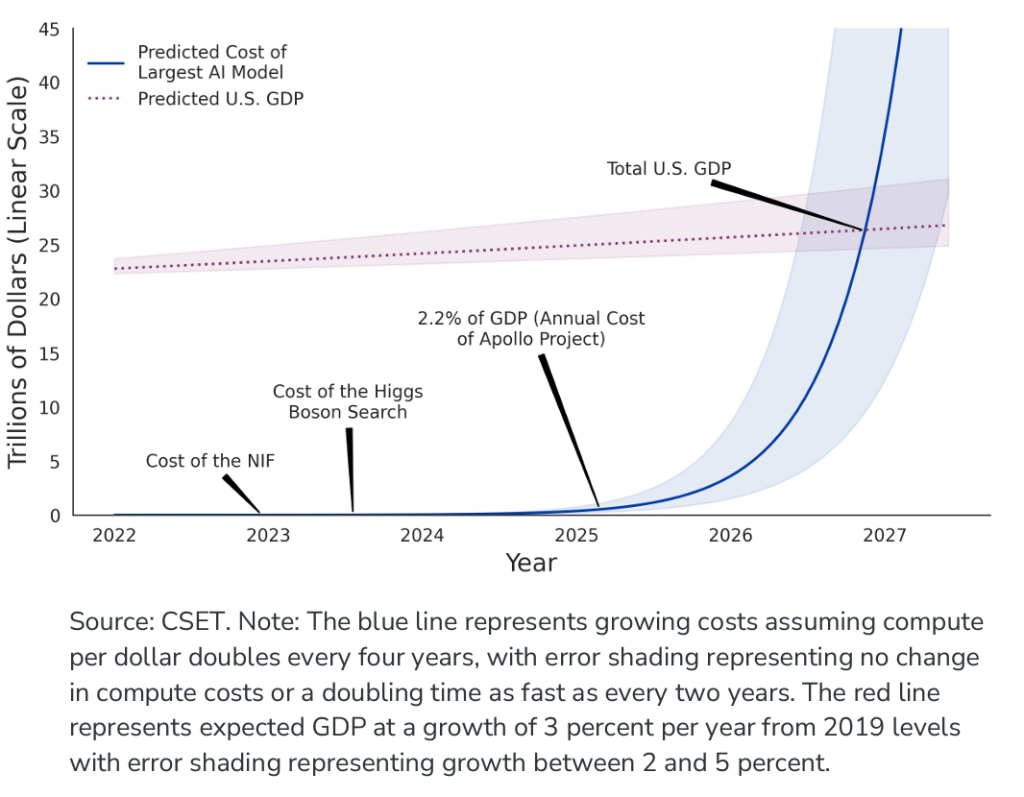
Poi c’è il talento, e no, non basta uno smart guy che ha letto “Deep Learning” di Goodfellow. Servono team di decine di ricercatori, ingegneri, esperti di NLP e infra-nerd specializzati nella gestione di cluster distribuiti con decine di migliaia di GPU. I migliori di loro vengono pagati come calciatori di Serie A, con pacchetti compensativi da 7-10 milioni annui, perché il margine di errore è sottile e l’impatto di una scelta sbagliata nella topologia del modello può trasformare milioni in fumo di silicio.
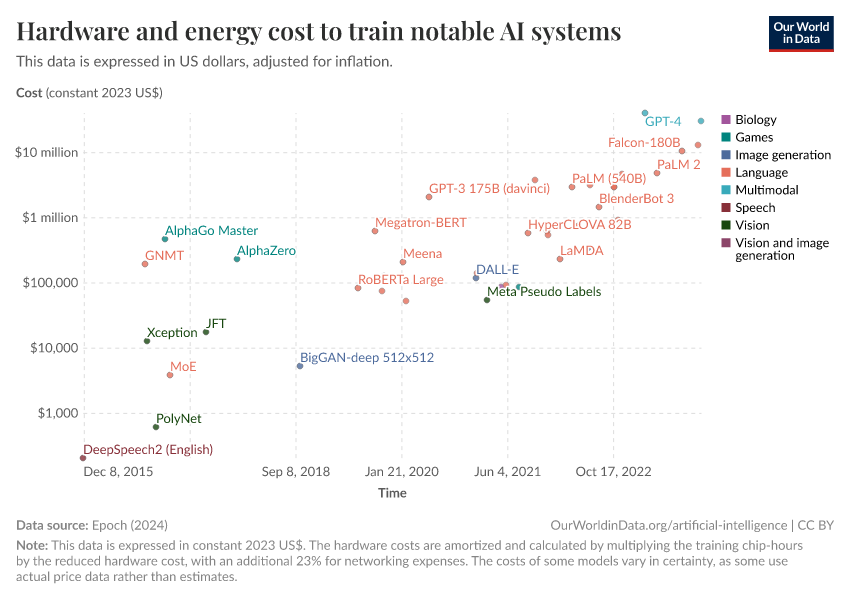
Il vero colosso, però, è la potenza computazionale. Per addestrare GPT-4 ci sono voluti mesi, migliaia di GPU H100 e un’infrastruttura da far invidia a un data center governativo. E non parliamo solo di energia: la logistica di mantenere un sistema del genere stabile, efficiente e senza bottlenecks per settimane o mesi è un progetto ingegneristico titanico. Per questo ormai i costi di training sono diventati un indicatore macroeconomico, alla pari del prezzo del petrolio o del tasso d’interesse della FED.
E quindi? Le startup e le imprese “normali” hanno una sola strada percorribile: non addestrare, ma adattare. Prendere modelli pre-addestrati (open o commerciali), e usare tecniche come il Retrieval-Augmented Generation (RAG) o il fine-tuning su dataset aziendali specifici. È meno sexy, ma è ciò che permette di creare valore concreto senza dover ipotecare la sede aziendale per comprare H100 su eBay.
In sintesi: l’AI è ancora uno sport elitario. E mentre Big Tech si gioca l’egemonia linguistica a colpi di GPU e milioni, il resto del mondo farebbe bene a studiare come sfruttare questi modelli senza doverli costruire da zero. Anche perché, a questi prezzi, presto addestrare un LLM costerà quanto costruire una centrale nucleare. E sarà comunque più facile ottenere i permessi per la seconda.