Sembra un’idea uscita da un laboratorio segreto di Google X, e invece è realtà open source. Prendi una cellula, una qualsiasi, una di quelle che ti porti appresso ogni giorno senza degnarla di uno sguardo. Quella cellula sta facendo qualcosa: produce proteine, si divide, reagisce agli stimoli. Ora immagina di trasformare tutte queste attività, tradizionalmente descritte da migliaia di numeri inaccessibili ai più, in una semplice frase in inglese. Voilà: benvenuti nell’era del linguaggio cellulare, dove le cellule parlano e i Large Language Models (LLM) ascoltano.
Dietro questa rivoluzione semiotica c’è C2S-Scale, una suite di modelli linguistici sviluppata a partire dalla famiglia Gemma di Google, pensata per interpretare e generare dati biologici a livello monocellulare. L’acronimo sta per “Cell-to-Sentence Scale” e il concetto è tanto semplice quanto spiazzante: convertire il profilo di espressione genica di una singola cellula in una frase testuale. Come trasformare una sinfonia genetica in una poesia sintetica. A quel punto puoi parlarci. Chiederle cosa fa. O come si comporterebbe sotto l’effetto di un farmaco.
Il contesto è questo: l’analisi single-cell è una delle frontiere più calde della biologia moderna. Ma i dati che produce – sequenziamenti RNA a risoluzione cellulare – sono così massicci, rumorosi e complessi che fino ad ora servivano batterie di bioinformatici, cluster HPC e settimane di lavoro per cavarne qualcosa di utile. Con C2S-Scale, tutto questo diventa text-to-text. L’interfaccia? Il linguaggio naturale. Le cellule? Una chat in attesa di input.
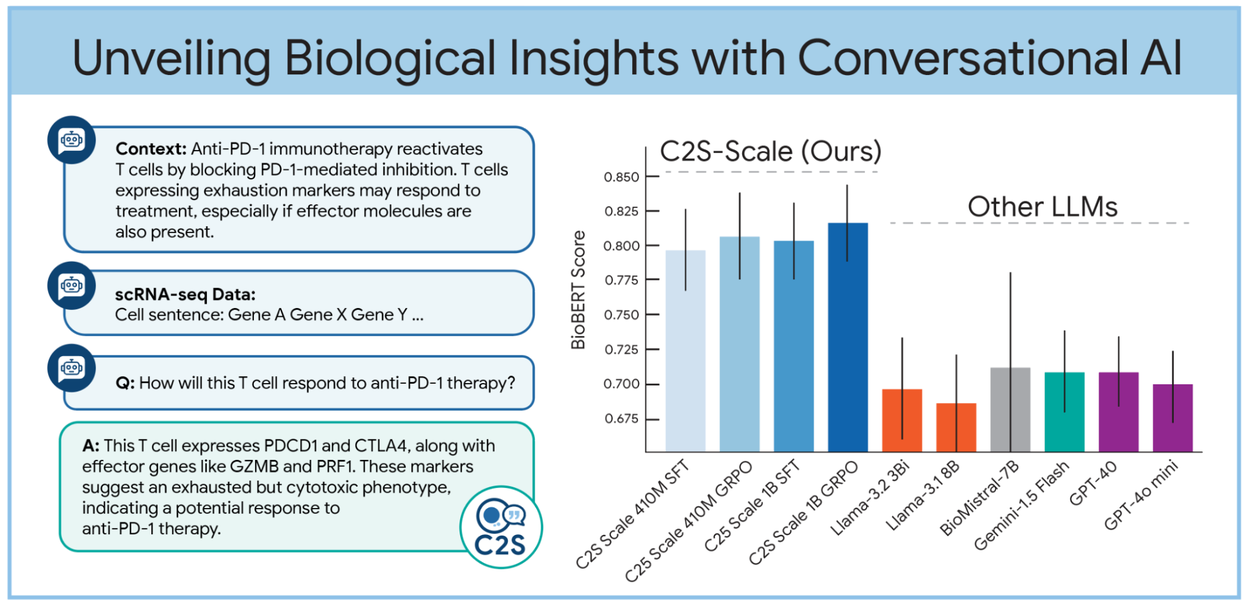
I ricercatori del progetto hanno costruito un lessico biologico dove ogni frase cellulare è composta dai geni più espressi, ordinati gerarchicamente. Questo linguaggio, sebbene minimale, contiene tutto ciò che serve per catturare il “mood” della cellula. L’esempio perfetto? Una cellula T immunitaria che si trova davanti a un trattamento anti-PD-1, una delle terapie oncologiche più discusse degli ultimi anni. Chiedi al modello come reagirà. Ti risponderà. Con una frase. Comprensibile. Contestuale. Con senso biologico. E, potenzialmente, clinico.
La scalabilità è un altro asso nella manica. I modelli C2S vanno da 410 milioni a 27 miliardi di parametri. Il che significa che puoi far girare un mini-modello sul tuo laptop per qualche esperimento esplorativo, oppure puoi lanciarti con la big gun da 27B per modellare l’intero fegato umano sotto perturbazione farmacologica. Non è solo un esercizio di stile: c’è dietro l’osservazione empirica che le prestazioni di questi LLM biologici crescono esponenzialmente con l’aumentare della loro capacità. Più dati, più parametri, più insight.
E qui arriva il twist da manuale di science fiction: la simulazione cellulare. Non solo le cellule possono parlare, ma C2S-Scale può anche predire cosa faranno. Inserisci una cellula baseline e un trattamento, ottieni una nuova frase che simula la sua espressione futura. In altre parole, un laboratorio in silico. Una cellula virtuale. Lo step successivo? Fare esperimenti che non esistono ancora, ottimizzare farmaci prima di produrli, saltare direttamente alla medicina predittiva senza passare dal via.
Ovviamente, per garantire che i modelli non diventino semplici generatori di fuffa biologica, viene applicato reinforcement learning con funzioni di ricompensa semantiche (tipo BERTScore). Si premiano le risposte che hanno senso scientifico, si puniscono le allucinazioni. Si crea così una specie di intelligenza biologica text-based, capace non solo di ragionare come un ricercatore, ma di spiegarsi anche meglio.
Tutto questo è open source, il che significa che la comunità scientifica potrà non solo usarlo ma anche metterci le mani, adattarlo, ottimizzarlo, fargli domande sempre più raffinate. È un po’ come aver dato un microfono alle cellule e un dizionario ai bioinformatici.
Con C2S-Scale, Google non ha solo costruito un’altra famiglia di LLM, ha messo in piedi una nuova grammatica della biologia, dove l’RNA è la nuova sintassi e ogni esperimento è un prompt.
Non è solo un salto tecnologico. È un cambio di paradigma. E come ogni rivoluzione linguistica che si rispetti, cambierà per sempre il modo in cui comprendiamo la vita.
Blog: Google Research Scaling Large Language Models for Next-Generation Single-Cell Analysis
I modelli e le risorse di Cell2Sentence sono ora disponibili su piattaforme come HuggingFace e GitHub . Vi invitiamo a esplorare questi strumenti, sperimentare con i vostri dati monocellulari e scoprire fin dove possiamo arrivare quando insegniamo alle macchine a comprendere il linguaggio della vita, una cellula alla volta.