Partiamo da una verità tanto banale quanto ignorata: lavorare con modelli linguistici di grandi dimensioni (LLM) non è difficile perché sono “intelligenti”, ma perché sono imprevedibili, opachi, e spesso capricciosi come artisti in crisi creativa. E allora il vero mestiere non è più scrivere codice, ma costruire impalcature solide dove questi modelli possano “giocare” senza mandare tutto a fuoco.
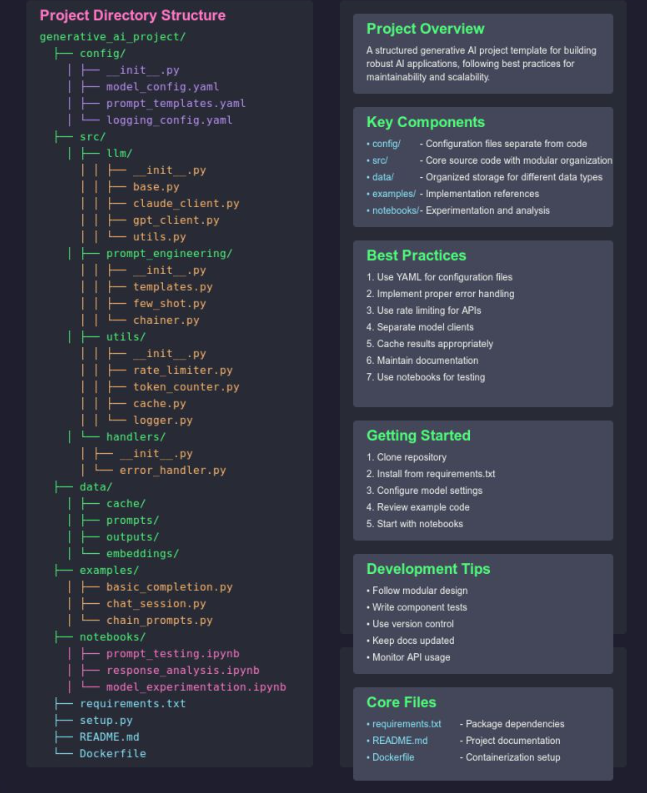
Quando si mettono le mani su progetti che orchestrano più provider LLM, stratificazioni di prompt engineering, dati che scorrono come fiumi impazziti e team distribuiti tra dev, ML engineer e product owner, l’unica ancora di salvezza è una struttura progettuale ferrea, cinicamente modulare e brutalmente trasparente.
La separazione netta tra configurazione e codice non è una questione estetica, ma una necessità operativa. YAML non è solo una moda hipster da DevOps, ma il tuo miglior alleato per isolare ogni variabile da testare, ogni modello da sostituire, ogni timeout da ritoccare senza dover scavare nel codice come un archeologo sotto caffeina. Centralizzare le configurazioni non è solo elegante: è sopravvivenza.
Un modulo dedicato al prompt engineering è ciò che distingue i progetti amatoriali da quelli “sostenibili”. Qui non si tratta solo di scrivere prompt carini con due frasi in caps lock. Si parla di un sistema templatizzato, con supporto few-shot dinamico, interpolazione di contesto, e strumenti di test integrati per misurare drift semantico e hallucination rate. Un prompt è codice, va trattato con la stessa dignità (e paranoia).
La sandboxizzazione dei client LLM – uno per provider, con interfacce standardizzate – è la chiave per evitare che un update di Anthropic o OpenAI ti faccia crollare l’intera architettura. Isolamento, mocking e fallback logici devono essere parte della struttura come lo scheletro in un corpo. Non farlo è come costruire un grattacielo su sabbie mobili e pregare che non piova.
C’è poi la triade maledetta ma indispensabile: caching, logging e rate limiting. Il caching non è ottimizzazione: è autodifesa. Se rigeneri lo stesso output mille volte sei un dilettante o un masochista. Logging dettagliato, con livelli semantici e tracciabilità del contesto, è l’unico modo per capire perché qualcosa è andato storto, non solo che è andato storto. E il rate limiting… beh, se non vuoi farti bannare da metà degli endpoint AI, meglio che tu lo implementi come un dogma religioso.
Tutto questo non serve solo a rendere i progetti più stabili. Serve a renderli vivibili. Vuoi fare sperimentazione rapida con versioni di modelli, prompt alternativi o sistemi di orchestrazione multi-agent? Devi avere un’infrastruttura modulare dove ogni pezzo si possa staccare, sostituire, loggare e debuggare senza riscrivere l’intero monolite. La riproducibilità, in questo contesto, è un’utopia che puoi solo sfiorare se hai tracciato tutto, dal seed random alla latenza su ogni chiamata.
E sì, anche la collaborazione ne guadagna. Quando un ML engineer può entrare nel repo e capire subito cosa succede, dove, e perché, senza dover leggere 40 file e 3 wiki obsolete, hai fatto bingo. L’onboarding non deve essere una seduta spiritica.
Chi lavora su Retrieval-Augmented Generation (RAG), fine-tuning, o sistemi basati su agenti, sa quanto questa architettura sia non solo utile, ma inevitabile. Le alternative sono solo due: caos o stagnazione. Se vuoi scalare, evolvere e iterare in tempi umani, questa è la via.
Tu come ti stai organizzando? Hai trovato altri pattern vincenti o ti sei schiantato contro i soliti iceberg? Raccontamelo, magari ci scambiamo cicatrici.