
RAG, Retrieval-Augmented Generation, ha iniziato come una promessa. Doveva essere la chiave per far sì che i modelli LLM non si limitassero a rigurgitare pattern statistici, ma attingessero da basi di conoscenza vive, aggiornate e specifiche. Ma la realtà è più triste di un Monday morning senza caffè: il 90% delle implementazioni RAG sono solo fetcher travestiti. Roba da casting per un reboot scadente di Clippy, altro che AI aumentata.
La colpa non è dell’idea, ma di chi la implementa. La maggior parte dei team considera il retrieval come un banale processo backend, una chiamata a Pinecone o FAISS e via, come se la parte retrieval fosse una formalità tra il prompt e la risposta. Un po’ come costruire un razzo e dimenticarsi del carburante.
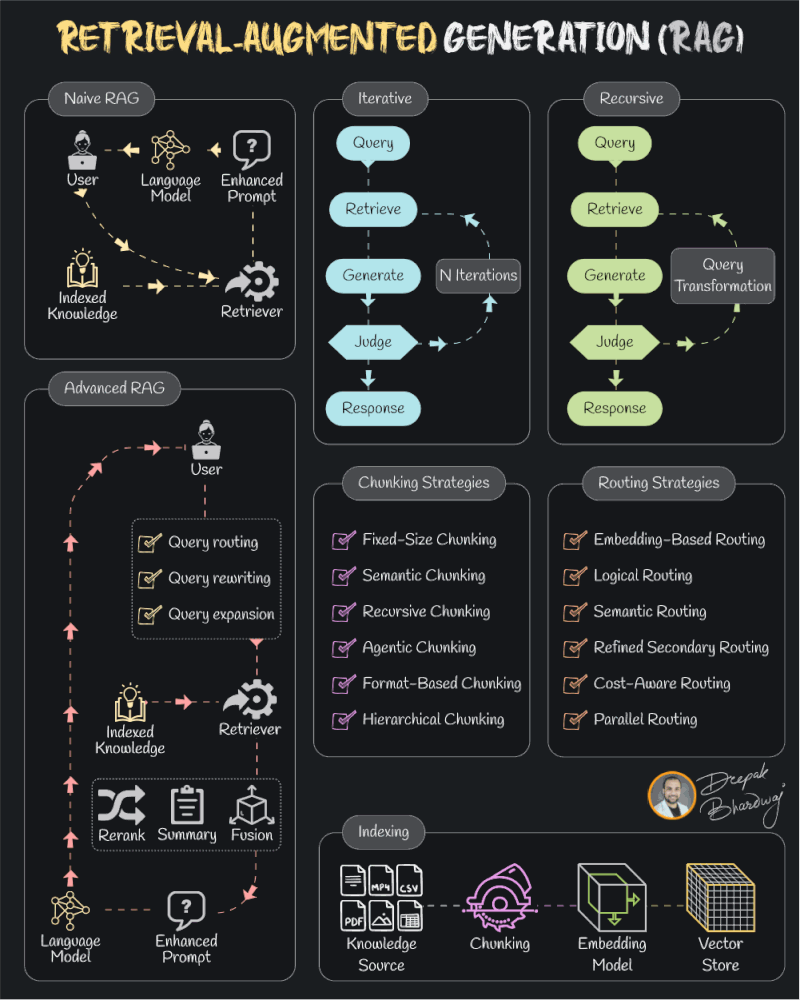
Questa superficialità si paga in noise. In risposte generiche, vaghe, irrilevanti. Il sistema diventa un generatore di fuffa con una UX da enciclopedia disordinata. Eppure, la retrieval è l’intelligenza. È il primo layer cognitivo. È ciò che decide cosa viene visto, interpretato, manipolato dal modello. Se sbagli qui, puoi avere anche GPT-50 sotto il cofano, e tirerà fuori comunque spazzatura ben formattata.
La differenza tra RAG naive e RAG evoluto sta tutta nella capacità di pensare al retrieval non come una fetch, ma come una strategia. Un RAG serio non si limita a recuperare documenti: li seleziona, li valuta, li riscrive, li riassume. Se serve, li fonde per generare contesto. E lo fa in modo iterativo, se non recursivo. Un RAG degno si evolve insieme alla query: riscrive il prompt, esplora alternative, costruisce comprensione passo dopo passo. Una conversazione, non una query SQL.
Poi c’è la questione chunking. Qui siamo al livello di chirurgia semantica. Fare chunking statico a caratteri o token fissi è come affettare un romanzo con la ghigliottina. Un buon chunk è semantico, ricorsivo, sensibile al contesto. Magari anche gerarchico: tiene conto della struttura della knowledge base. È un’operazione di raffinamento, non una rottamazione.
Routing? Anche peggio. Molti si affidano all’embedding naïf e un cosine similarity che fa venire i brividi. Ma il routing vero è un motore decisionale. Deve capire se è meglio un documento tecnico o una guida utente, se cercare in un dataset o in un altro. È semantico, logico, cost-aware. E se vogliamo scalare, deve anche saper girare in parallelo. Non stiamo parlando di scegliere file da un disco, stiamo orchestrando una pipeline cognitiva.
E non dimentichiamoci dell’indicizzazione. Spesso snobbata come un lavoro da sysadmin, l’indicizzazione è l’arma segreta del retrieval: determina se gli embedding sono utili o una farsa, se le lookup sono veloci o collose. È come l’assistente invisibile di uno chef stellato: se non fa il suo lavoro, il piatto non arriva mai in tavola.
In fondo, RAG non è un accessorio per l’AI. È un sistema di pensiero. È knowledge engineering mascherato da prompt engineering. Non basta farlo funzionare. Bisogna farlo pensare. Perché se il retrieval è stupido, l’output sarà solo una bella frase costruita su sabbia.
E quindi, la domanda giusta non è “hai implementato RAG?”.
La domanda è: il tuo RAG sa davvero cosa cercare, dove cercare e perché?
Oppure hai solo costruito un motore di ricerca con un costume da ChatGPT?