Secondo uno studio MSFT 25% del codice nuovo scritto da Google è generato da AI. Non lo dice un anonimo post su Hacker News, lo dice Sundar Pichai in persona. Mark Zuckerberg, non certo noto per la moderazione nei suoi entusiasmi, vuole strumenti AI di coding ovunque dentro Meta. OpenAI e Anthropic stanno già infilando i loro modelli nei flussi di lavoro degli sviluppatori. Ma c’è un dettaglio fastidioso che rovina la festa: questi modelli sanno scrivere codice, ma non sanno correggerlo. O meglio, si perdono in bug che uno stagista al primo mese sistemerebbe in due minuti. Così, mentre ci illudiamo che la prossima frontiera sia il prompt che ti scrive l’app da solo, la realtà è che passiamo ancora la maggior parte del tempo a fare debugging. A mano. Come nell’era pre-AI.
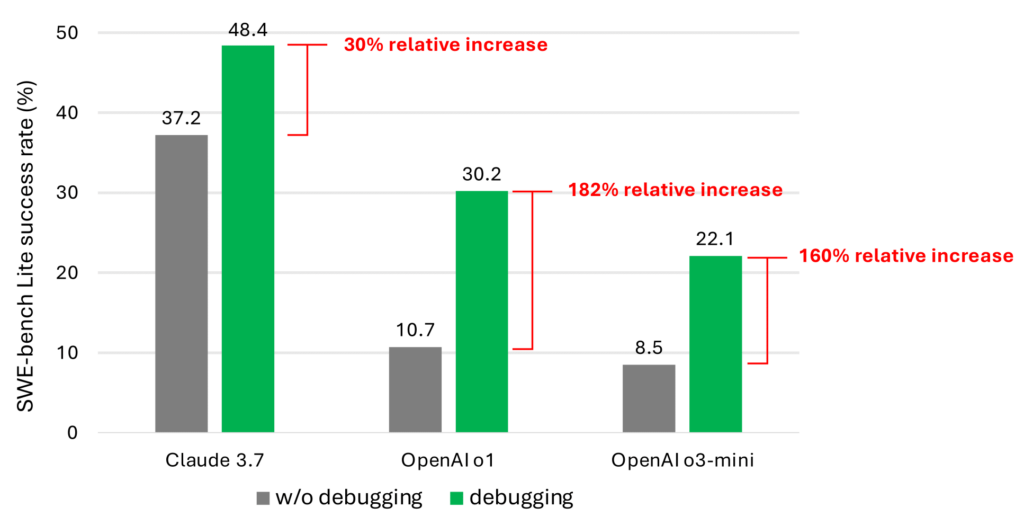
Una fotografia chiara e impietosa arriva da uno studio basato su SWE-bench Lite, un benchmark che testa modelli su 300 task di debugging realistici e curati, non i soliti giocattolini da playground. I risultati sono tutto fuorché entusiasmanti: Claude 3.7 Sonnet è il top performer, ma risolve solo il 48.4% dei bug. OpenAI o1 si ferma al 30.2%, o3-mini sprofonda al 22.1%. Numeri che non ti fanno proprio venir voglia di dare in mano la tua pipeline di produzione a un transformer ottimista.
Il punto non è che l’AI non capisca il codice. Lo sa scrivere, sa fare refactoring, suggerisce pattern che a volte sorprendono anche gli umani. Il problema è che non pensa come un developer. Non ragiona per ipotesi, non fa debugging esplorativo, non sa scegliere lo strumento giusto, non imposta breakpoints, non guarda le variabili, non cerca informazioni. Indovina. Come un medium col terminale, non un ingegnere software.
Perché? Perché nessuno ha mai insegnato a questi modelli cosa vuol dire “fare debugging” in senso umano. I dataset di training sono pieni di codice statico, ma non di sequenze temporali di azioni investigative. Mancano i dati comportamentali che rappresentano il debugging come processo decisionale sequenziale: osserva → ipotizza → testa → fallisci → riprova. In una parola, manca il metodo.
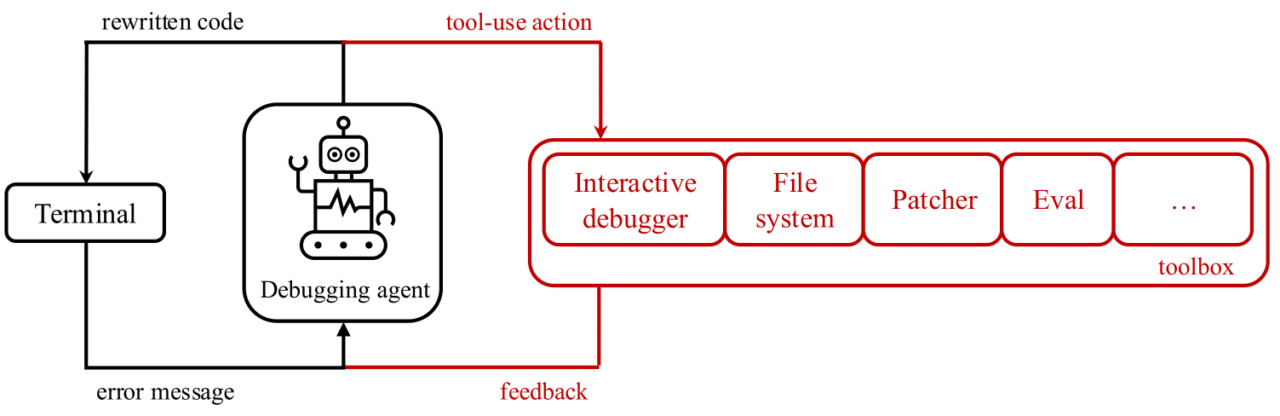
Da qui nasce Debug-Gym, un’idea che suona piccola ma ha un potenziale enorme. È un ambiente open-source dove agenti AI possono interagire con repository completi, dentro container Docker isolati, in condizioni realistiche. Non più snippet astratti ma codice vivo, con bug reali, strumenti reali, output reali. Tutte le azioni sono testuali, quindi LLM-friendly, ma è la dinamica a cambiare tutto. Qui l’AI non risponde a una domanda. Qui agisce, esplora, osserva, fallisce, e—se è addestrata bene—impara. Proprio come noi.
Se funziona, Debug-Gym potrebbe essere il primo passo per trasformare questi modelli da generatori passivi a collaboratori attivi. Non un copilota che ti suggerisce righe di codice, ma un junior engineer che ti affianca, che fa domande, che indaga, che col tempo può diventare anche bravo. Non un automa da babysittare, ma un teammate vero.
Per ora è una release tecnica e silenziosa. Ma potrebbe essere quella che segna il salto di paradigma. Perché scrivere codice è solo metà del lavoro. Se l’AI non sa sistemarsi da sola, resterà sempre un assistente carino ma inutile. E noi, i CTO, dovremo continuare a fare da genitori ai nostri modelli “prodigio”.