
Benvenuti nel teatrino dell’intelligenza artificiale, dove le apparenze contano più della sostanza e i benchmark sono diventati il nuovo campo di battaglia della reputazione. Meta, ex-Facebook e attuale fabbrica di illusioni alimentate da GPU, ha appena servito un esempio da manuale di come si possa manipolare la percezione senza infrangere esplicitamente le regole. E lo ha fatto con Llama 4 Maverick, il suo modello open-weight che, a detta loro, “batte GPT-4o e Gemini 2.0 Flash su una vasta gamma di benchmark”.
Ovviamente, è andata diversamente.
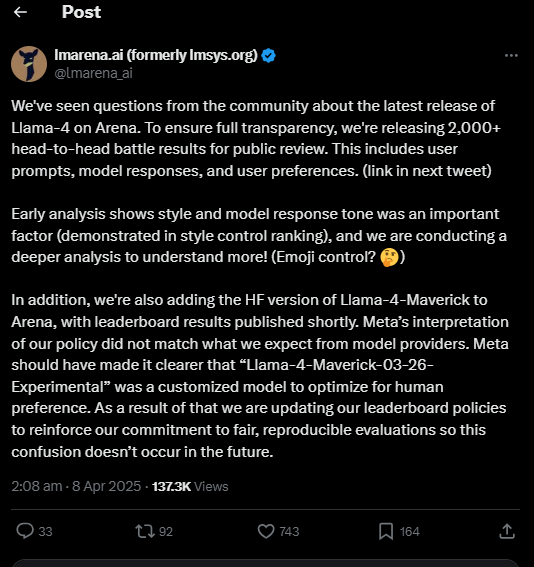
Nel weekend, Meta ha rilasciato due nuovi modelli della serie Llama 4: Scout, il fratellino minore, e Maverick, il modello mid-size che avrebbe dovuto mettere in crisi i soliti noti (OpenAI, Anthropic, Google). Subito Maverick si è piazzato secondo nella classifica di LMArena, il sito che vive e muore in base a quanto bene gli LLM riescano a convincere gli umani nel confronto diretto. Un punteggio ELO di 1417 superiore a GPT-4o ha fatto brillare gli occhi di chi sognava un’alternativa open seria al duopolio Microsoft-Google.
Peccato che fosse tutto basato su una versione… truccata.
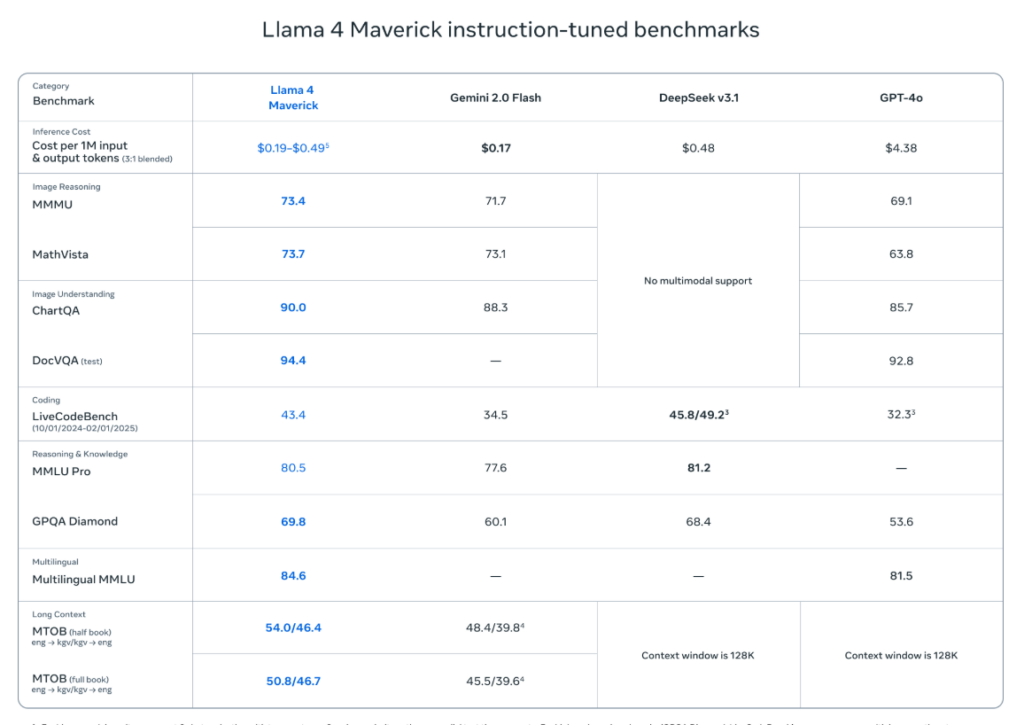
Meta ha infilato tra le righe della documentazione che il Maverick usato su LMArena non è quello pubblico. Il modello testato si chiamava infatti Llama-4-Maverick-03-26-Experimental, e sì, era ottimizzato per la conversazione. Tradotto: un fine-tuning ad hoc pensato per massimizzare le performance solo nel contesto dell’arena. Non quello che puoi scaricare e usare tu, sviluppatore, domani mattina.
E qui parte il balletto delle giustificazioni. LMArena ha pubblicamente bacchettato Meta su X, dicendo che la compagnia “non ha interpretato correttamente la policy” e promettendo nuove regole per evitare che questo genere di operazioni si ripeta. Tradotto in cinico: si sono fatti infinocchiare. E ora devono salvare la faccia.
La portavoce di Meta, Ashley Gabriel, ha cercato di ridurre il danno parlando di “sperimentazioni con varianti personalizzate”, mentre Ahmad Al-Dahle, VP dell’AI generativa di Meta, ha negato che ci sia stato overfitting sui test set. Ma il problema non è tanto se abbiano barato apertamente, quanto il contesto tossico che stanno aiutando a creare. In un ambiente dove ogni modello viene giudicato da punteggi ELO e benchmark sintetici, basta un minimo di ottimizzazione ad hoc per sballare completamente la percezione pubblica. Il risultato? I dev si fidano sempre meno delle classifiche, ma non hanno alternative credibili.
E non è un caso se Simon Willison, ricercatore indipendente che segue da vicino il mondo LLM, ha detto: “Il punteggio che hanno ottenuto è completamente inutile per me. Non posso nemmeno usare il modello che ha preso quel punteggio.” Sembra quasi la recensione di un ristorante stellato che serve menù da copertina ai critici e avanzi ai clienti paganti.
Il fatto che Meta abbia rilasciato Llama 4 di sabato non è passato inosservato. Zuck ha risposto con la solita frase zen da maestro Jedi: “Era pronto in quel momento.” Che è un po’ come dire “ho pubblicato il repo sul GitHub perché stavo finendo la birra”.
Secondo un report de The Information, la release era già stata rinviata più volte per via di problemi interni legati alle prestazioni del modello. Ma poi è arrivata la pressione: DeepSeek, una startup cinese con un modello open-weight impressionante, ha messo Meta in difficoltà. E quindi eccolo lì, il rilascio frettoloso, il trucco del modello “experimental” e il marketing camuffato da trasparenza.
Ora la comunità open-source si trova davanti a un paradosso: Maverick è tecnicamente open, ma i risultati che lo hanno reso famoso non sono quelli del modello che puoi usare. È un po’ come comprare una Ferrari dopo aver letto una recensione basata su un prototipo da pista che non verrà mai messo in commercio. Complimenti per la furbizia, ma siamo al limite tra strategia e manipolazione.
E la morale? Semplice. I benchmark stanno diventando come le elezioni nei paesi autoritari: teoricamente aperti, ma controllati da chi sa usare meglio gli strumenti della propaganda. Se LMArena è l’arbitro imparziale, allora Meta ha appena trovato il modo per comprare l’arbitro senza nemmeno doverlo corrompere. Un capolavoro di realpolitik applicata al machine learning.
Intanto qui trovi la notizia originale su TechCrunch.
LM Arena Chatbot Arena Policy: ttps://blog.lmarena.ai/blog/2024/policy/?utm_source=chatgpt.com