di Redazione Tech
I grandi modelli linguistici (LLM) come ChatGPT hanno rivoluzionato il modo in cui interagiamo con l’intelligenza artificiale, ma non sono privi di limiti. Uno dei problemi più critici è la generazione di contenuti “allucinati”, ovvero informazioni false o inventate presentate come vere. Questa tendenza rappresenta un rischio in contesti dove la correttezza fattuale è essenziale, come in ambito medico, giuridico o giornalistico.
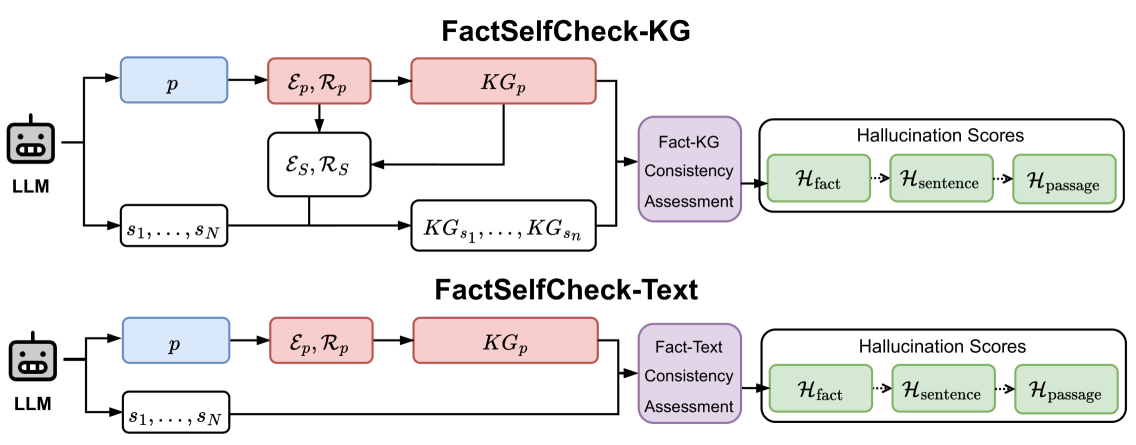
Un team di ricercatori della Wroclaw University of Science and Technology e dell’University of Technology Sydney ha recentemente presentato FactSelfCheck, un innovativo metodo per identificare le allucinazioni a livello di singoli fatti, anziché di frasi o paragrafi. Il sistema si basa sulla costruzione di grafi della conoscenza (knowledge graph), dove ogni fatto è rappresentato come una tripla (soggetto, relazione, oggetto). Ad esempio, (“Albert Einstein”, “premio Nobel”, “1921”).
Come funziona FactSelfCheck?
- Estrazione di conoscenza: Il testo generato dall’LLM viene scomposto in entità e relazioni, formando un grafo strutturato.
- Confronto tra risposte: Generando più risposte alla stessa domanda, FactSelfCheck analizza la coerenza dei fatti tra le diverse versioni. I fatti che variano o si contraddicono vengono classificati come potenziali allucinazioni.
- Punteggio di affidabilità: Ogni fatto riceve un “punteggio di allucinazione”, che ne indica l’affidabilità.
I risultati sono promettenti: rispetto a metodi precedenti come SelfCheckGPT, FactSelfCheck migliora la correzione dei contenuti errati del 35%, contro un incremento dell’8% ottenuto con approcci a livello di frase. «La granularità è fondamentale», spiega Albert Sawczyn, autore principale dello studio. «Identificare esattamente quale fatto è sbagliato permette interventi più mirati, riducendo il rischio di eliminare informazioni corrette».
Implicazioni pratiche e futuro
Oltre al contesto accademico, tecnologie come FactSelfCheck potrebbero integrarsi in strumenti per il fact-checking automatico o nell’ottimizzazione di chatbot aziendali.

A tal proposito, società come Babelscape, specializzata in elaborazione del linguaggio naturale, ha già incorporato grafi della conoscenza nel suo portfolio. Il loro prodotto Knowledge Graph utilizza tecniche simili per estrarre e validare relazioni da testi, offrendo soluzioni per l’analisi di dati testuali complessi in ambito corporate e mediatico.
«L’obiettivo è creare sistemi che non solo generino contenuti, ma lo facciano con accountability», commenta un rappresentante di Babelscape. «L’integrazione di metodi come FactSelfCheck nei nostri strumenti è un passo verso modelli più trasparenti e affidabili».
Mentre la ricerca avanza, la sfida rimane rendere queste tecnologie accessibili e scalabili. Con l’aiuto di realtà come Babelscape, il futuro dei LLM potrebbe essere meno “allucinato” e più ancorato alla realtà.