
L’Intelligenza Artificiale sta cambiando radicalmente il modo in cui aziende e professionisti prendono le decisioni critiche. Grazie all’analisi avanzata dei dati e agli algoritmi predittivi, oggi possiamo dire che l’IA predice il futuro con un’accuratezza sorprendente. Che si tratti di stimare le vendite di un prodotto, prevedere il comportamento degli utenti o anticipare con buoni risultati le tendenze del mercato, le soluzioni basate sull’IA permettono di ridurre l’incertezza e ottimizzare le strategie aziendali.
In questo articolo parleremo proprio di come l’IA predice il futuro in diversi settori, quali sono le tecnologie che permettono queste previsioni e come possiamo sfruttarle per ottenere un vantaggio competitivo, economico o quello che preferisco io ossia risparmiare tempo.
Modelli predittivi: come l’IA predice il futuro
L’Intelligenza Artificiale si basa sull’analisi di enormi quantità di dati per riconoscere schemi e tendenze che sarebbero difficili, se non impossibili, da individuare manualmente. Grazie ai modelli predittivi, l’IA predice il futuro con un’approssimazione sempre più accurata, aiutando aziende e professionisti a prendere decisioni informate.
Ma cosa sono esattamente i modelli predittivi e come funzionano?
I modelli predittivi sono algoritmi di Machine Learning e Deep Learning che analizzano dati storici per fare previsioni su eventi futuri. Funzionano grazie a una combinazione di matematica, statistica e reti neurali che permettono di identificare relazioni nascoste tra variabili.
Immaginiamo di gestire un e-commerce: un modello predittivo può analizzare gli acquisti passati, il comportamento degli utenti sul sito e i trend di mercato per prevedere quanti prodotti verranno venduti il mese prossimo. In questo modo, l’IA predice il futuro della domanda e aiuta a ottimizzare la gestione degli stock.
Tipologie di modelli predittivi
Esistono diverse categorie di modelli predittivi, ognuna adatta a specifici contesti:
- Regressione lineare e logistica: utilizzata per stimare valori numerici (es. vendite future) o probabilità di eventi (es. tasso di conversione);
- Alberi decisionali e Random Forest: modelli che suddividono i dati in più livelli decisionali per migliorare la precisione delle previsioni;
- Reti neurali artificiali: ispirate al cervello umano, analizzano dati complessi per fare previsioni sofisticate, come il riconoscimento delle immagini o l’elaborazione del linguaggio naturale;
- Sistemi di raccomandazione: utilizzati in piattaforme come Netflix o Amazon per prevedere quali contenuti o prodotti potrebbero interessare di più agli utenti.
Ora passiamo alla parte più tecnica, ma non bisogna essere matematici esperti, malati di statistica o laureati in fisica. Ci sono un po’ di formule ma non è importante capirle matematicamente, è più importante capire cosa fanno, tanto i calcoli li farà il modello.
Regressione lineare e logistica: come funzionano e perché sono fondamentali nei modelli predittivi
Quando si parla di modelli predittivi, due delle tecniche più utilizzate sono la Regressione Lineare e la Regressione Logistica.
Questi metodi permettono di fare previsioni basandosi su dati esistenti e vengono applicati in moltissimi settori, dal marketing alla finanza, dalla medicina all’ingegneria.
Regressione Lineare: serve a prevedere valori numerici
La Regressione Lineare è un modello statistico che viene utilizzato per prevedere un valore numerico basandosi su una o più variabili indipendenti.
Come funziona la regressione lineare?
L’idea di base è trovare una relazione lineare tra una variabile dipendente (quella da prevedere) e una o più variabili indipendenti (i fattori che influenzano il risultato).
Immaginate di essere proprietari di una gelateria e di voler prevedere il numero di gelati che venderete in base alla temperatura del meteo. Se li mettiamo in una tabella e ci creiamo un grafico avremo qualcosa simile a questo:
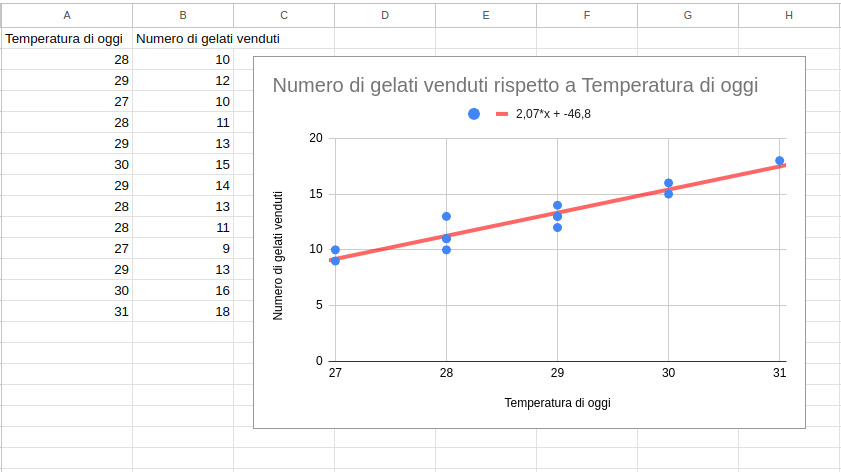
Matematicamente, la formula della regressione lineare semplice è:
Y=mX+bDove:
- Y è il valore da prevedere (nell’esempio è il numero di gelati da vendere).
- X è la variabile indipendente (nell’esempio è la temperatura del giorno).
- m è la pendenza della retta (indica quanto cambia Y al variare di X, nell’esempio è la linea rossa ).
- b è l’intercetta (valore di Y quando X è zero).
Se vogliamo considerare più variabili indipendenti (ad esempio, budget pubblicitario, prezzo del prodotto, stagionalità), il modello diventa:
Y=m1X1+m2X2+...+mnXn+bCaso pratico
Un’azienda vuole stimare le vendite mensili in base alla spesa pubblicitaria. Analizzando i dati storici, scopre che ogni 1.000,00€ di pubblicità ha 500 vendite in più.
Applicando la regressione lineare, può stimare il numero di vendite in base all’investimento pubblicitario.
Pro
Semplice da interpretare e veloce da calcolare, si può fare anche con Excel.
Fa previsioni rapide e identifica correlazioni tra variabili.
Contro
Non funziona bene con dati complessi o quando la relazione tra variabili non è lineare, si capisce facilmente quando il grafico dei dati forma una curva, in questo caso si usa la regressione non lineare.
Sensibile agli outlier, che è un modo figo per dire che ci sono dati anomali che possono distorcere il risultato.