
L’adozione crescente degli strumenti di ricerca basati sull’intelligenza artificiale sta ridefinendo il modo in cui gli utenti accedono alle informazioni. Secondo recenti studi, quasi un americano su quattro utilizza l’AI al posto dei motori di ricerca tradizionali. Tuttavia, dietro l’efficienza apparente di questi strumenti si cela una problematica fondamentale: l’accuratezza e l’affidabilità delle informazioni generate.
A differenza dei motori di ricerca convenzionali, che fungono da intermediari tra utenti e contenuti editoriali, le piattaforme di ricerca generativa estraggono, sintetizzano e ripropongono informazioni senza necessariamente ricondurre alle fonti originali. Questa dinamica non solo sottrae traffico ai siti di news, ma solleva interrogativi sulla trasparenza, sulla qualità dei dati e sulla correttezza delle attribuzioni.
Un’indagine del Tow Center for Digital Journalism ha esaminato il comportamento di otto strumenti di ricerca AI con funzionalità di live search, analizzando la loro capacità di recuperare e citare correttamente contenuti giornalistici. I risultati rivelano un quadro allarmante: oltre il 60% delle risposte fornite era errato, con alcuni chatbot che si distinguevano per una sicurezza ingiustificata nelle loro affermazioni inesatte.
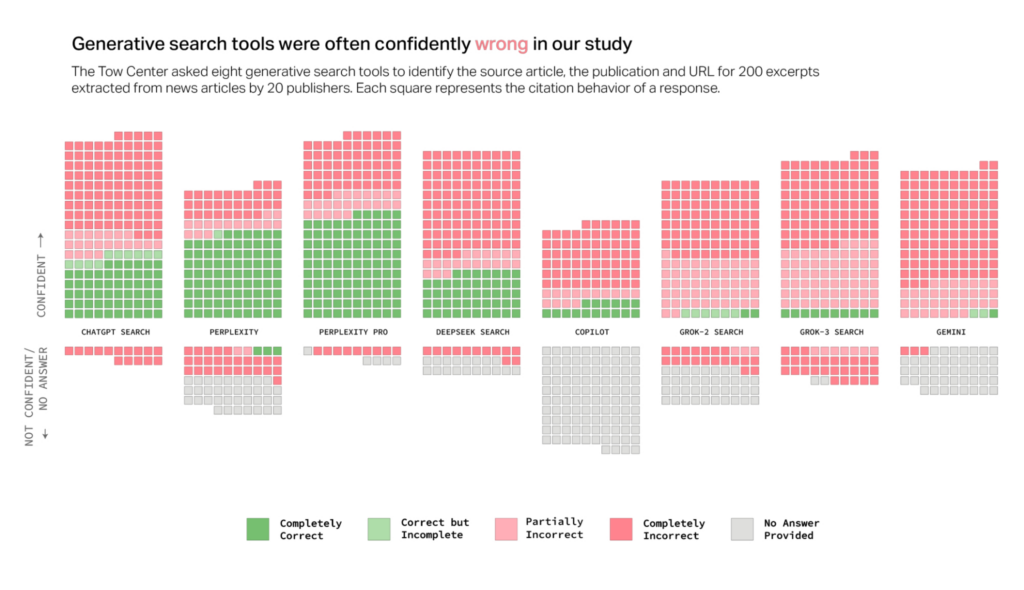
Il problema della fiducia: risposte errate e sicurezza infondata
Una delle evidenze più significative dello studio è che i chatbot raramente ammettono la loro incertezza. Anziché dichiarare l’impossibilità di fornire una risposta accurata, molte piattaforme generano informazioni errate con una sicurezza disarmante. Ad esempio, ChatGPT ha fornito 134 risposte inesatte, ma solo in 15 casi ha segnalato una possibile incertezza.
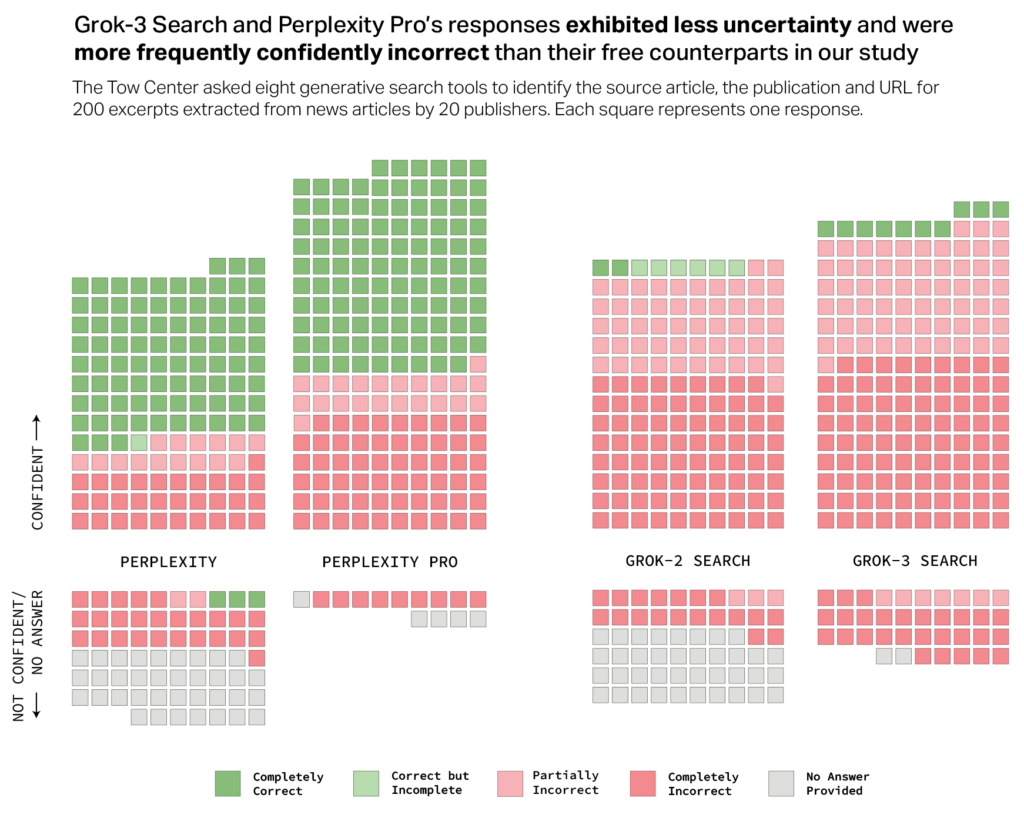
Inoltre, i modelli a pagamento, che ci si aspetterebbe essere più affidabili, hanno mostrato tassi di errore più elevati rispetto alle loro versioni gratuite. Strumenti premium come Perplexity Pro ($20/mese) e Grok 3 ($40/mese) hanno risposto con maggiore accuratezza in alcuni casi, ma anche con una maggiore propensione a fornire risposte errate senza alcuna esitazione. Questa tendenza crea un’illusione di affidabilità, rendendo ancora più difficile per gli utenti distinguere tra dati corretti e inesatti.
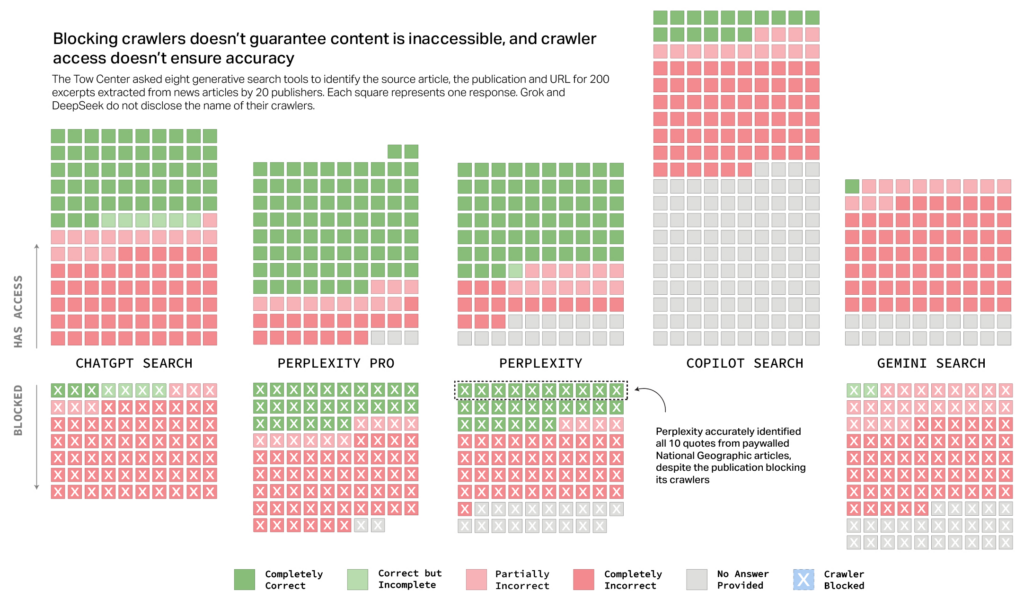
L’inosservanza delle direttive robot.txt e l’accesso non autorizzato ai contenuti
La questione dell’accesso ai contenuti rappresenta un ulteriore elemento critico. Il protocollo di esclusione robot.txt consente ai proprietari di siti web di limitare o impedire la scansione dei propri contenuti da parte di determinati crawler. Tuttavia, lo studio ha rilevato che alcuni chatbot hanno recuperato informazioni anche da fonti che ne avevano esplicitamente vietato l’accesso.
Ad esempio, Perplexity Pro ha correttamente identificato quasi un terzo degli articoli provenienti da testate che avevano bloccato il proprio crawler. In un caso eclatante, la versione gratuita di Perplexity ha identificato tutti e dieci gli estratti di articoli di National Geographic, nonostante il sito avesse impedito l’accesso al suo crawler. Questo comportamento solleva dubbi sulla reale osservanza delle politiche di esclusione da parte di alcune piattaforme AI.
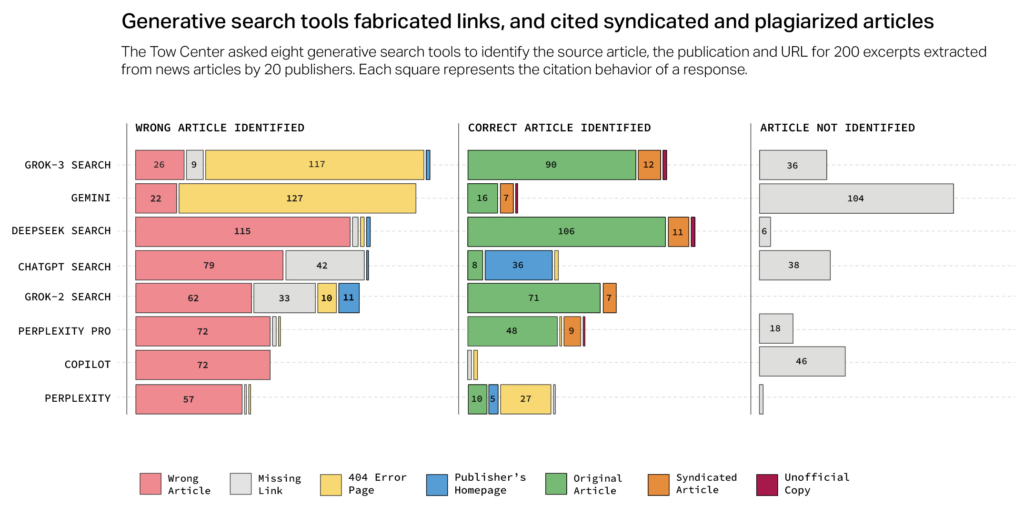
Il problema delle citazioni errate e dei link inesistenti
Un altro problema emerso dallo studio è la tendenza dei chatbot a fornire citazioni errate o a linkare fonti sbagliate. In molti casi, gli strumenti AI hanno attribuito il contenuto a siti che non erano quelli originali o hanno fabbricato URL inesistenti. Ad esempio, DeepSeek ha erroneamente attribuito la fonte di un articolo in 115 casi su 200.
Ancora più preoccupante è il fenomeno della citazione di versioni sindacate o ripubblicate di articoli, anziché degli originali. Perplexity, ad esempio, ha spesso citato versioni di articoli apparsi su Yahoo News o AOL, invece di linkare direttamente alla fonte primaria. Questo fenomeno priva le testate giornalistiche del traffico organico e della visibilità che spetterebbe loro.
Grok 2 si è distinto per la generazione di link inesistenti, mentre più della metà delle risposte fornite da Gemini e Grok 3 conteneva URL fabbricati o non funzionanti. Questo problema compromette la verificabilità delle informazioni da parte degli utenti e mina la credibilità delle fonti giornalistiche.
Accordi di licenza e accuratezza: un rapporto incerto
Alcune aziende AI, tra cui OpenAI e Perplexity, hanno avviato collaborazioni con editori per garantire un accesso diretto ai loro contenuti. Tuttavia, lo studio ha evidenziato che questi accordi non garantiscono necessariamente una maggiore accuratezza delle citazioni.
Ad esempio, il San Francisco Chronicle, pur avendo concesso l’accesso ai propri contenuti a OpenAI, è stato citato correttamente da ChatGPT solo in un caso su dieci. Anche il Time, che ha partnership con OpenAI e Perplexity, ha visto il proprio contenuto identificato in modo impreciso in numerose occasioni. Questo dimostra che, sebbene le aziende AI abbiano interesse a stringere accordi con le testate, l’accuratezza nel riconoscimento e nella citazione delle fonti rimane un problema irrisolto.
Il futuro della ricerca AI e il ruolo degli editori
L’adozione della ricerca AI pone nuove sfide per l’ecosistema dell’informazione. Se da un lato queste tecnologie offrono agli utenti un accesso rapido ai contenuti, dall’altro minano la trasparenza, l’attribuzione delle fonti e la sostenibilità economica delle testate giornalistiche.
La difficoltà nel controllare come i chatbot accedono e utilizzano i contenuti degli editori sta alimentando un dibattito sempre più acceso sul rispetto delle regole da parte delle aziende AI. La News Media Alliance ha sottolineato che la mancanza di strumenti di opt-out efficaci potrebbe compromettere la possibilità degli editori di monetizzare i propri contenuti e finanziare il giornalismo di qualità.
Nonostante questi problemi, il COO di Time, Mark Howard, rimane ottimista sulla futura evoluzione di queste tecnologie: “Oggi è il giorno in cui questi strumenti sono al loro livello peggiore. Con il tempo e con gli investimenti in ingegneria, miglioreranno”. Tuttavia, fino a quando non verranno introdotte misure più efficaci per garantire trasparenza e accuratezza, il rischio che l’AI distorca e renda opaca la diffusione delle informazioni rimarrà elevato.
DATUI su Github