
Cosa fare quando si scopre di essere vittime di Click Fraud
Hai scoperto di essere vittima di click fraud. Come si procede ora?
La prima cosa da fare, ovviamente, è cercare di escludere il traffico malevolo.
Ma ogni cosa ha un inizio, e per mitigare gli attacchi di click fraud abbiamo due cose che fanno capire dove iniziare: l’acquisto di annunci, la pubblicazione di annunci.
Acquistare annunci nel modo corretto
Quando si acquistano gli annunci, soprattutto all’inizio, l’entusiasmo gioca contro i nostri obiettivi.
Filtrare per località, età, dispositivi e quanto altro le singole piattaforme offrono limita molto la pubblicazione di annunci in quelle nazioni dove “lavorano” click farm e sistemi, aiutando a ridurre il rischio.
É il momento dell’aneddoto in tema:
Tanto tempo fa un mio amico proprietario di una pizzeria mi fa: “Sai, ho iniziato a fare pubblicità su Google, e funziona! Hanno cliccato più di mille persone… però solo 7 hanno ordinato.”
“Gli annunci li hai impostati su Piramide, Garbatella e Aventino? (quartieri di Roma ndr)”, gli chiedo.
“Ehm… no…”, fa lui.
“Certo che se uno di Padova ti ordina una pizza gli arriverà fredda.”, faccio io.
La cosa interessante è che anche il click fraud funziona esattamente allo stesso modo, se mostri i tuoi annunci in posti in cui non dovresti ti metti nei guai da solo.
Pubblicare gli annunci nel modo corretto
Qui le cose si fanno un po’ più complicate, ma ci sono risorse online che ci aiutano a realizzare quanto sto per raccontarvi.
Ho un blog in WordPress su cui devo mitigare gli attacchi di click fraud. Che cosa faccio?
Caso primo: Conosco un po’ di programmazione e voglio scrivere il codice da solo, magari mi faccio aiutare da strumenti di IA come blackbox.ai.
Per prima cosa devi integrare le informazioni di geo localizzazione, puoi usare la libreria GeoIP, e imparare a scrivere dei widget dove inserire gli annunci che verranno mostrati solo se l’utente ha un IP italiano.
Poi giorno dopo giorno puoi inserire controlli su user agent e via dicendo.
Caso secondo: Non conosco la programmazione o la conosco così bene da non volermi infilare in casini indicibili e passare notti insonne.
Puoi installare un plugin che gestisce la pubblicazione degli annunci in maniera completa, un plugin come WPQuads o AdvancedAds.
Cercando le liste degli user agent malevoli, browser e tutto quel che è possibile trovare online, puoi configurare i plugin nel modo più completo possibile per meglio ridurre gli attacchi più utilizzati dal villain di turno.
Alziamo le difese
Un’altra difesa sono le CDN. Impostare una CDN che fa da ombrello al traffico è un ottimo modo per evitare click fraud.
Le CDN più popolari possono bloccare il traffico in tanti modi, per device, per nazionalità o altri parametri.
Se il tuo sito è dedicato esclusivamente ad un pubblico italiano puoi bloccare il traffico di tutte le altre nazioni.
Tranne gli USA, li ci sono i macchinari di Google, Meta, Amazon e gli altri big, gli USA, nel bene e nel male, non vanno bloccati.
Inoltre i sistemi delle big company hanno sistemi di riconoscimento dei bot, almeno quelli più popolari.
Le CDN per controllare l’accesso al sito
Abbiamo letto che quando i nostri siti o le nostre app pubblicano annunci, e siamo sotto attacco, un modo semplice per mitigare gli attacchi di click fraud è impostare una CDN, filtrando la visualizzazione del sito per nazioni, per user agent e IP.
Si possono trovare sul web parecchie liste di IP e user agent da usare con le CDN, una lista abbastanza popolare è quella di Mitchell Krog, una buona risorsa per iniziare.
Chi ha la possibilità di scrivere o farsi scrivere del codice può implementare soluzioni che creano le liste necessarie alla CDN in base i dati della richiesta degli annunci, oppure in base ai dati che ricava dagli analitycs.
Chi non può può affidarsi a chi fa questo di mestiere.
I sistemi professionali di controllo per mitigare gli attacchi di click fraud
Non posso parlare per tutti, ma l’esperienza di Methbot ha insegnato molto a tanti.
La cosa che abbiamo imparato è che non si possono prevenire, ma si possono riconoscere in fretta grazie a dei parametri specifici.
Abbiamo imparato come configurare i server, come impostare le utenze, come configurare l’architettura di rete, insomma abbiamo imparato a battere il ferro per modellare lo scudo secondo le necessità.
Ma sopra a ogni cosa abbiamo imparato a leggere una enorme quantità di dati, interpretarli correttamente e a dargli il giusto peso.
La parte che spesso nessuno sembra voler considerare è che ad ogni novità tecnologia il numero di dati aumenta, e con esso il numero di combinazioni dei parametri che formano le nostre difese.
Significa che un sistema che andava bene 5 anni fa oggi è pressoché inutile.
Nel nostro caso la quantità di parametri che andiamo ad analizzare aumenta costantemente, parametri che vengono analizzati sotto ogni punto di vista, come potete vedere dall’immagine sottostante.
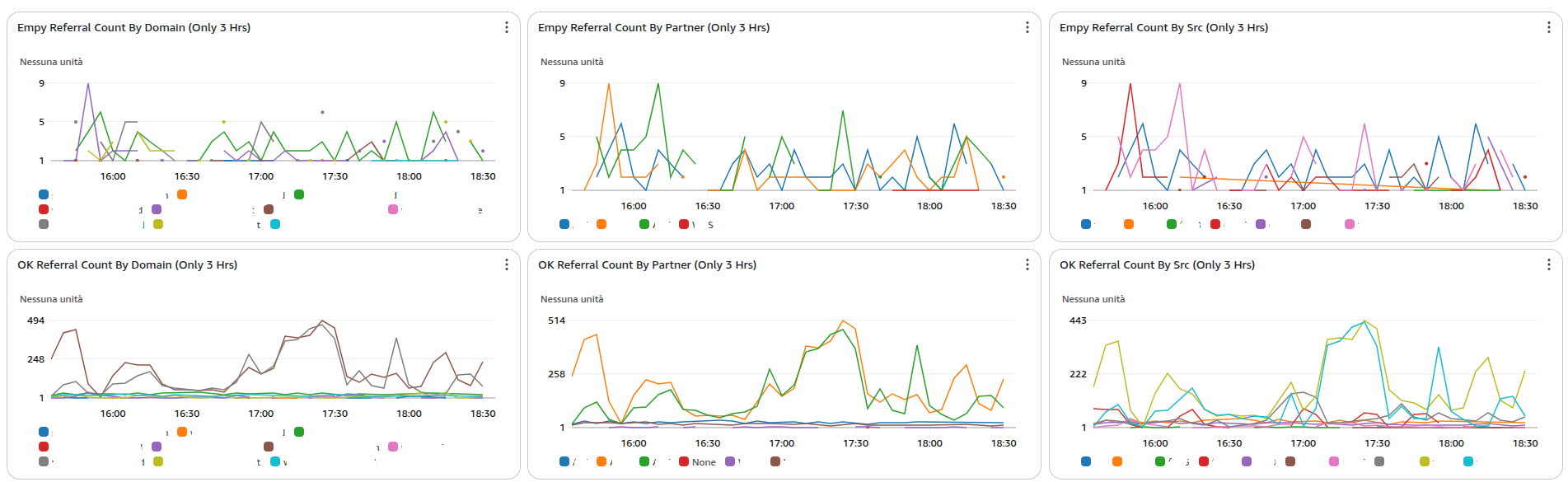
La parte più complessa è ricavare i dati più interessanti che ci permettono di identificare i bot dalle persone, ma è anche la parte più divertente.
Ovviamente, come ogni buon mago, non verrò a svelarvi i nostri trucchi, ma utilizziamo tutto quello che tecnologicamente è possibile utilizzare per ricavare l’origine e lo scopo di “cosa” sta navigando il sito o utilizzando l’app.
Ma torniamo al nostro tema principale.
A differenza dei sistemi fatti in casa questi sistemi di alert e controllo possono integrarsi facilmente a tutta una serie di funzionalità.
L’insieme dei dati del traffico viene analizzato dall’avvio delle campagne pubblicitarie, per sorgente, device, formato e tanti altri parametri in tempo reale.
Il risultato dell’uso di queste piattaforme è il pieno controllo del traffico in ingresso, e di conseguenza del traffico in uscita.
Questo è fondamentale per sapere se gli attacchi da click fraud avvengono solo su determinate tipologie di traffico.
La divisione del traffico per segmenti permette di scegliere e risolvere i problemi in tempi estremamente brevi, individuando sia la provenienza del traffico che le fonti.
Questo ci permette di identificare se l’accesso è stato fatto da un bot o da una persona, così possiamo ordinare se pubblicare o meno le pubblicità o l’erogazione del servizio, oltre ovviamente aggiornare l’analitico dei dati.
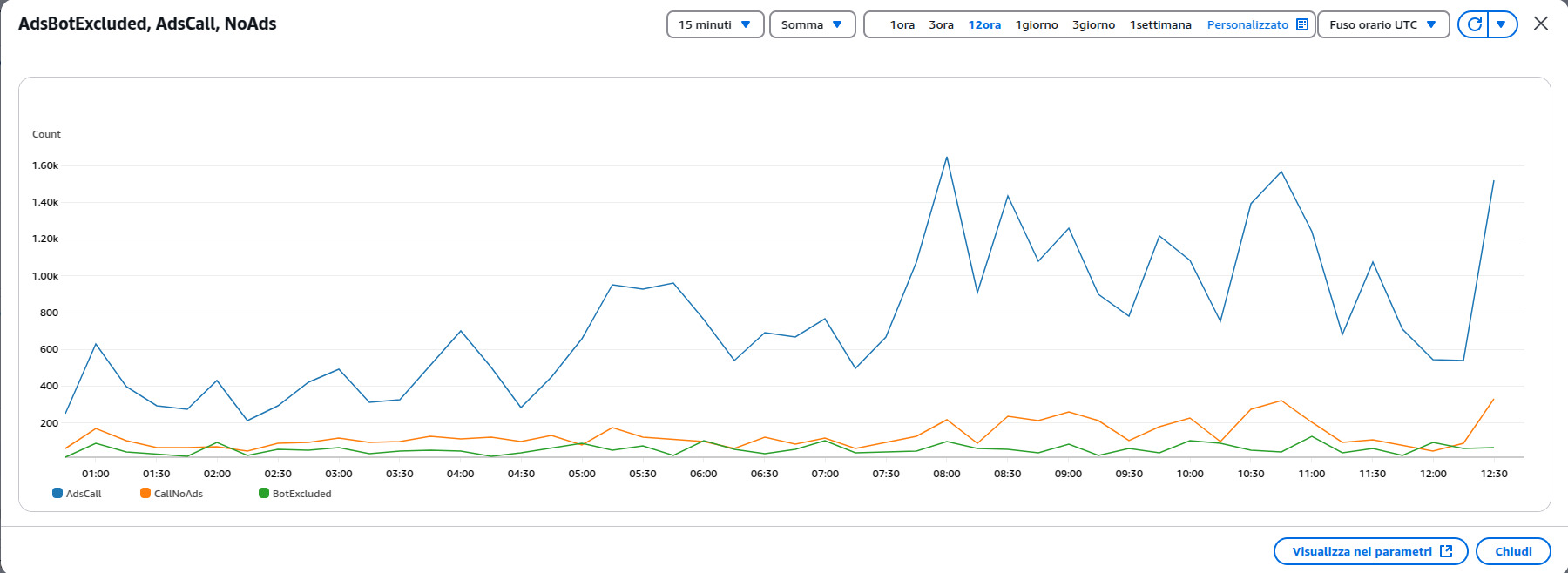
Ci permette anche di identificare se l’investimento pubblicitario è stato fatto con una società che merita la nostra fiducia.
In pratica se acquisti degli ads dalla società XYZ e questa diventa una delle vittime di click fraud riesci ad accorgertene velocemente e mettere in pausa le pubblicità.
Se poi ti trovi a mitigare gli attacchi di click fraud sempre dalla società XYZ un giorno si e l’altro pure, allora puoi anche gentilmente “regalare una cassetta di prugne” alla società XYZ e chiudere il contratto.
Come vedete dal grafico, questa è quella che nel calcio chiameremmo difesa a catenaccio, la linea verde ci indica che, anche se impostiamo tutte le difese, dalla CDN alle configurazioni dei web server, c’è sempre un po’ di traffico malevolo che riesce a passare, che però riusciamo ad identificare e bloccare per tempo.
Se vediamo i numeri è evidente che il 5/6% dei bot riesce a passare il centrocampo e arriva in area di porta:
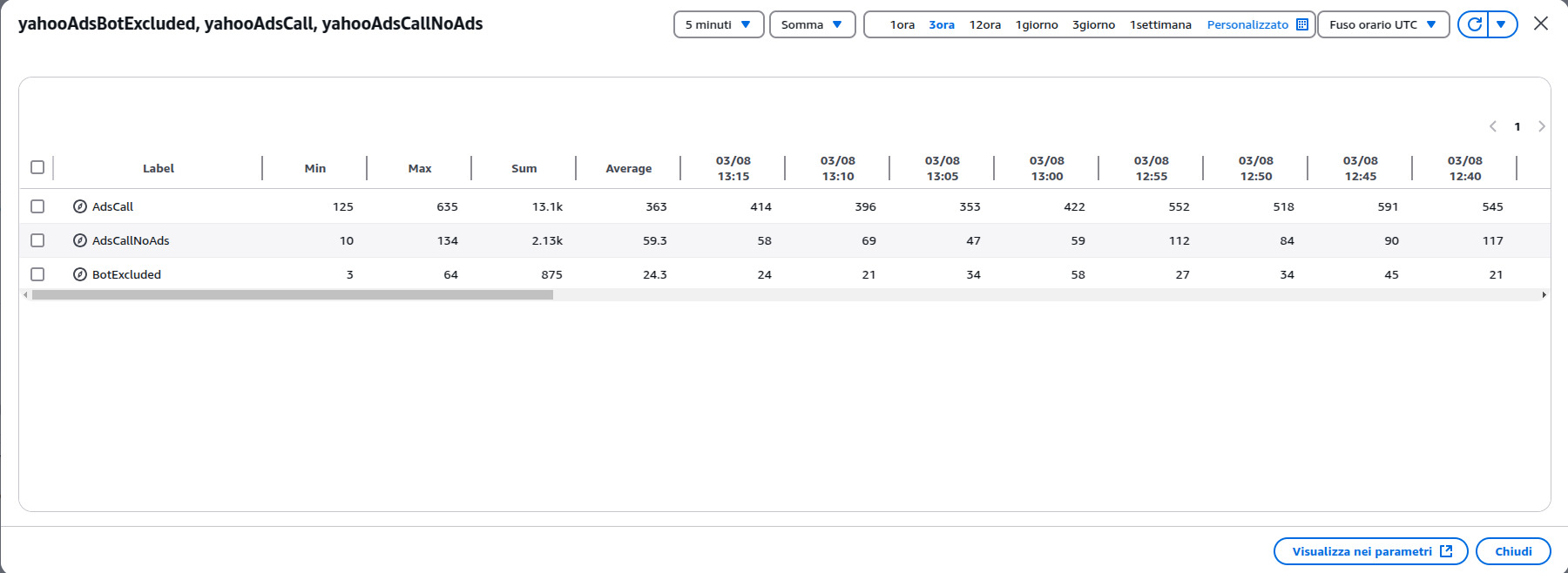
Come vedete non ho preso dati di un giorno particolare in un orario particolare, tutti i giorni è così.
L’IA contro il click fraud
Il vantaggio di avere questi dati ben catalogati, su cosa intendo per “ben catalogati” potete leggerlo nel paragrafo Principi fondamentali della catalogazione qualche articolo fa, è il trovare la strada spianata per il prossimo passo: mitigare gli attacchi di click fraud tramite i modelli di Anomaly Detection.
Grazie ai dati catalogati possiamo creare un modello supervisionato per l’Anomaly Detection nel traffico dedicato al marketing online.
Questo modello funziona utilizzando dati storici etichettati, cioè esempi passati di traffico normale e traffico anomalo, quindi bot, click fraudolenti, user agents e via dicendo.
Preparazione dei dati storici
Per addestrare un modello supervisionato serve un dataset con esempi di traffico già categorizzati. I dati sono sostanzialmente quelli di cui abbiamo parlato sopra:
Log di accesso al sito: IP, User-Agent, tempo di permanenza, numero di pagine visitate.
Dati di Google Analytics: tasso di rimbalzo, origine del traffico, sessioni per utente.
Dati delle campagne pubblicitarie: CTR, CPC, tempo tra i click, formati, ecc…
Database di attacchi o bot conosciuti: Immaginatelo come un enorme foglio Excel composto in questo modo:
| IP | Tempo sulla pagina | Pagine visitate | Origine | Click su Ads | Etichetta |
|---|---|---|---|---|---|
| 192.168.1.1 | 3s | 1 | Unknown | 10 | Bot |
| 82.45.67.12 | 300s | 5 | 1 | Utente reale | |
| 172.217.3.1 | 0.5s | 1 | 50 | Click Fraud |
Scelta dell’algoritmo di ML
Una volta raccolti i dati, si sceglie un algoritmo per l’addestramento.
Ce ne sono parecchi, ognuno con le sue caratteristiche, quelli più utilizzati sono:
Random Forest: Analizza le decisioni basandosi su più alberi decisionali. Si usa quando devi rilevare pattern complicati che prevedono una serie di risultati diversi.
Support Vector Machine (SVM): Funziona come un filtro. Separa i dati normali da quelli anomali creando un confine tra i due tipi di dati.
Reti Neurali: Sono la base del riconoscimento dei sistemi di IA, quindi se gli passiamo tutti i tipi di attacchi che possiamo ricavare sarà in grado di dirci se è un attacco o se non lo è.
Addestramento del modello
La bibliografia dice che i modelli vanno addestrati con una parte dei dati storici, ad esempio 80% e il restante 20% viene usato per fare i test. La realtà è che bisogna fare il meglio possibile con il meglio che abbiamo.
La bontà del modello viene migliorata regolando parametri, ottimizzando le caratteristiche, aggiungendo o togliendo i dati inutili o dannosi.
Rilevazione in tempo reale
Una volta scelto l’algoritmo e addestrato il modello possiamo usarlo per analizzare il traffico in tempo reale.
Quando un utente arriva sul sito o sull’app il modello analizza le sue caratteristiche, ad esempio il tempo sulla pagina, le pagine visitate, IP, origine del traffico e tutti quei dati che abbiamo usato per addestrare il modello.
In base all’algoritmo usato avremo la risposta per sapere se è l’utente è un bot o una persona reale. Può essere un si o un no, o un numero reale da 0 a 1, o un valore numerico positivo o negativo.
Ottimizzazione continua
La parte più comoda di un modello di AI è che è facile aggiornarlo con nuovi dati e migliorare la precisione mano a mano che scopri nuovi tipi di attacchi.
La parte scomoda è che se cambiano i dati di riferimento nella quantità e nel formato bisogna ricominciare d’accapo, perché non sapremo valutare la bontà dei risultati del modello.