
Negli ultimi anni, i modelli di linguaggio di grandi dimensioni hanno ridefinito il panorama dell’elaborazione del linguaggio naturale (NLP), con particolare attenzione ai modelli generativi. Tuttavia, i modelli encoder bidirezionali restano essenziali per compiti come il recupero di informazioni, la classificazione e la regressione. In questo contesto nasce EuroBERT, una nuova famiglia di modelli encoder multilingue progettata per superare i limiti delle attuali architetture e garantire prestazioni all’avanguardia nelle lingue europee e nei principali idiomi globali.
EuroBERT è ottimizzato per una vasta gamma di applicazioni, introducendo innovazioni nell’architettura del modello, nelle metodologie di training e nella selezione dei dataset. Integrando elementi ispirati ai moderni modelli generativi, mantiene la robustezza e l’efficienza delle architetture basate su encoder, con un focus sulle prestazioni di livello superiore.
EuroBERT migliora i modelli multilingue esistenti come XLM-RoBERTa e mGTE attraverso diverse innovazioni chiave. La prima grande differenza è l’ampia copertura linguistica garantita da un dataset di addestramento da 5 trilioni di token, comprendente 15 lingue. Questo consente al modello di operare con maggiore precisione su un numero significativo di contesti e domini.
Dal punto di vista architetturale, EuroBERT introduce meccanismi avanzati come il grouped query attention, le rotary position embeddings e la root mean square normalization, migliorando l’efficienza computazionale e l’accuratezza nelle predizioni. Inoltre, il supporto nativo per sequenze fino a 8.192 token lo rende ideale per attività su documenti di grandi dimensioni, come il recupero di informazioni e la sintesi automatica.
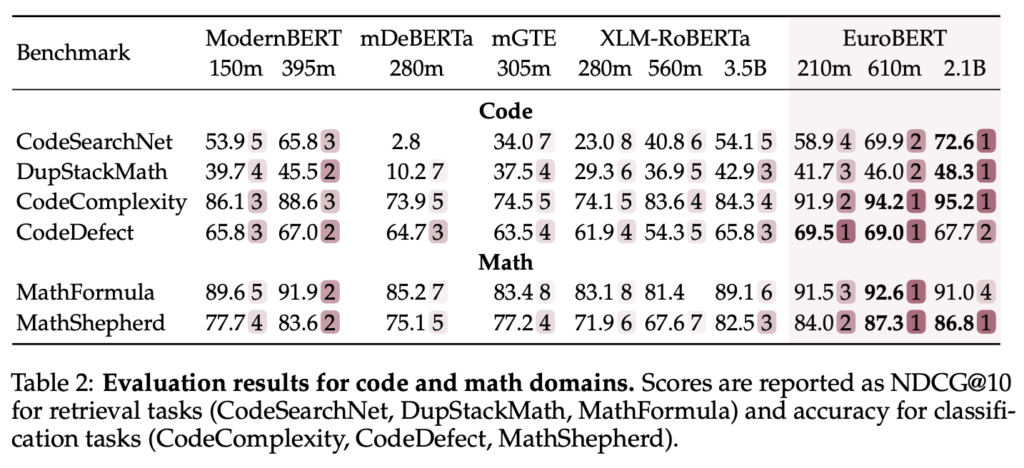
Un altro aspetto distintivo è l’inclusione di dataset specializzati per la matematica e i linguaggi di programmazione, elementi che potenziano le capacità di recupero e ragionamento del modello. Questa caratteristica permette a EuroBERT di eccellere in compiti che richiedono comprensione strutturata del testo, come l’analisi del codice sorgente o il problem solving matematico.
Metodologia di training
L’addestramento di EuroBERT avviene attraverso un pipeline in due fasi, ottimizzata per garantire adattabilità e generalizzazione. Nella fase di pretraining, il modello apprende le strutture linguistiche utilizzando il metodo masked language modeling (MLM) su un corpus multilingue di alta qualità. Successivamente, nella fase di annealing, vengono effettuate regolazioni sulla distribuzione dei dati e sui parametri di addestramento, tra cui la riduzione del tasso di mascheramento e il bilanciamento della rappresentazione multilingue.
Uno degli aspetti più innovativi della ricerca su EuroBERT è l’analisi approfondita delle scelte di addestramento. Gli esperimenti hanno esaminato l’impatto della qualità del filtraggio dei dati, delle variazioni nella lunghezza delle frasi e del bilanciamento delle lingue, permettendo di ottenere prestazioni ottimali su più task.
Prestazioni e benchmark
EuroBERT stabilisce nuovi standard di riferimento per i modelli encoder multilingue, ottenendo risultati all’avanguardia su un’ampia gamma di task NLP. Nei test di multilingual retrieval su dataset come MIRACL, Wikipedia e CC-News, il modello ha superato le prestazioni degli attuali sistemi di ricerca e ranking dei documenti.
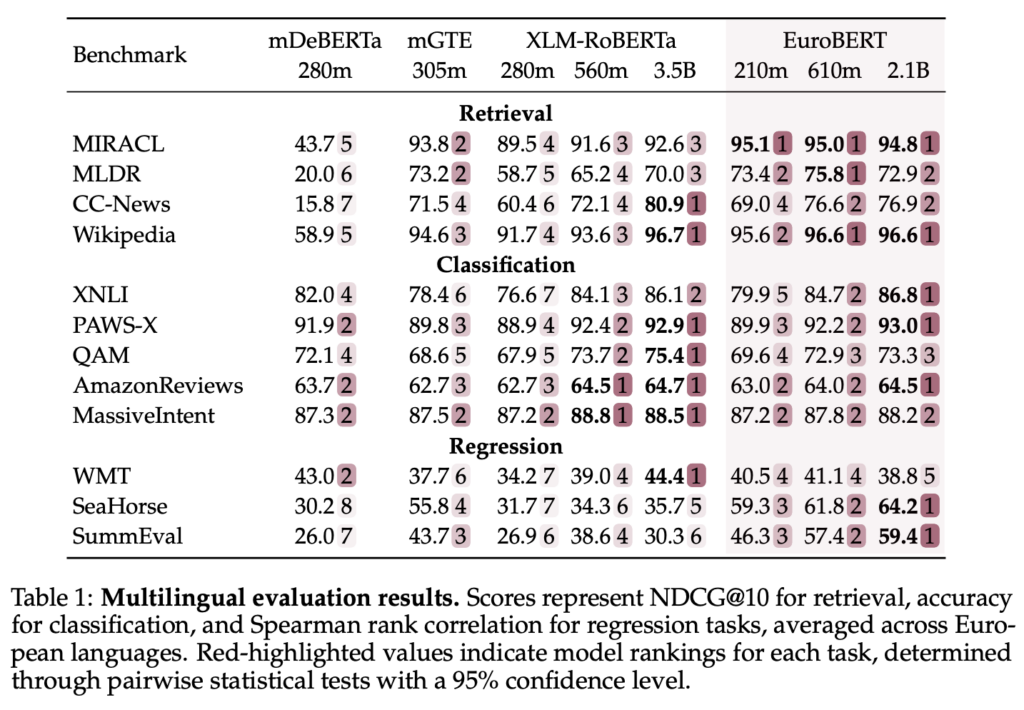
Nei compiti di classificazione, come XNLI, PAWS-X e le recensioni di Amazon, EuroBERT ha dimostrato un’accuratezza superiore rispetto ai modelli precedenti, evidenziando un’eccellente capacità di comprensione semantica e sentiment analysis. Inoltre, nei test di regressione su dataset come SeaHorse, WMT e SummEval, il modello ha ottenuto ottimi risultati nella valutazione della similarità testuale e nei compiti di valutazione automatizzata.
Un altro ambito in cui EuroBERT eccelle è la comprensione del codice e della matematica, ottenendo punteggi elevati nei benchmark CodeSearchNet e MathShepherd. Questo lo rende una scelta ideale per applicazioni che richiedono capacità avanzate di ragionamento simbolico e logico.
Gestione di testi lunghi
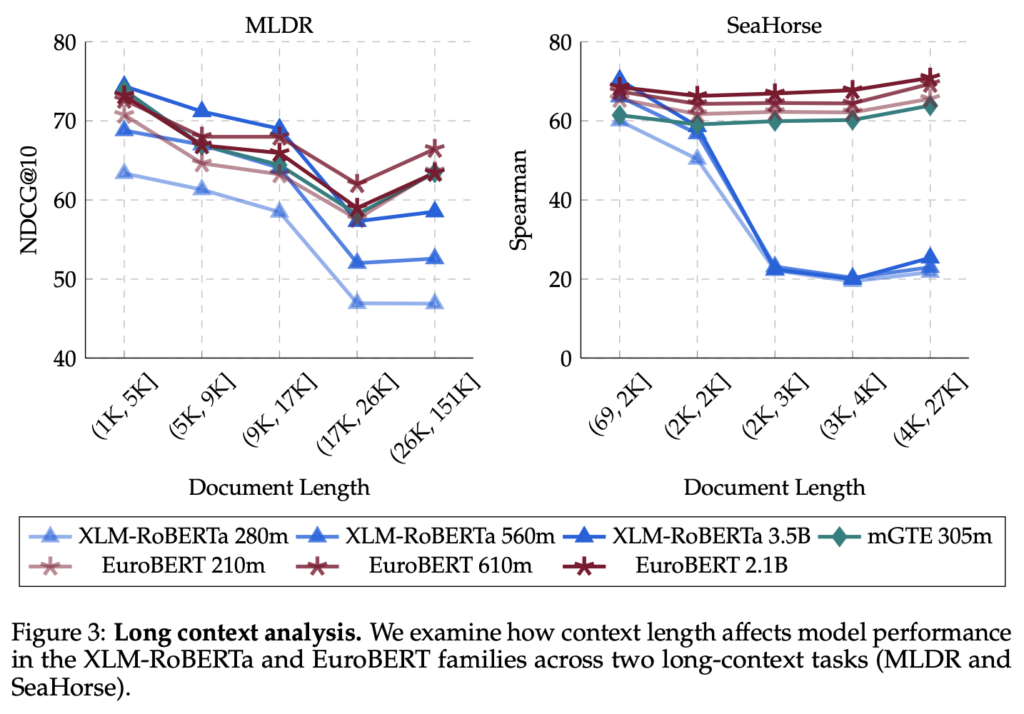
Una delle caratteristiche più rivoluzionarie di EuroBERT è la sua capacità di gestire testi molto lunghi in modo efficace. Il supporto nativo per sequenze fino a 8.192 token lo rende particolarmente adatto a task complessi come il recupero di informazioni su documenti estesi, la generazione di riassunti di alta qualità e la risposta a domande basate su lunghi corpus testuali. Questo lo posiziona come una soluzione ideale per applicazioni in ambito legale, scientifico e accademico.
Open source e accessibilità
Per incentivare l’adozione e la ricerca, l’intera famiglia di modelli EuroBERT è stata rilasciata in open-source, offrendo:
- i checkpoint del modello in diverse dimensioni (210M, 610M e 2.1B di parametri)
- snapshot intermedi per garantire la riproducibilità degli esperimenti
- il framework di training e la composizione dei dataset
Per approfondire, il paper è disponibile su arXiv, mentre i modelli possono essere scaricati da Hugging Face. Il codice di addestramento sarà presto disponibile su GitHub.
Chi ha contribuito al progetto
EuroBERT è il risultato della collaborazione tra il laboratorio MICS di CentraleSupélec, Diabolocom, Artefact e Unbabel, con il supporto tecnologico di AMD e CINES. Il progetto è stato finanziato dal governo francese attraverso il programma France 2030, nell’ambito dell’iniziativa ArGiMi e dell’Istituto DataIA.
Nicolas Boizard, Hippolyte Gisserot-Boukhlef, Duarte M. Alves, André Martins, Ayoub Hammal, Caio Corro, Celine Hudelot, Emmanuel Malherbe, Etienne Malaboeuf, Fanny Jourdan, Gabriel Hautreux, João Alves, Kevin El-Haddad, Manuel Faysse, Maxime Peyrard, Nuno Miguel Guerreiro, Ricardo Rei, Pierre Colombo
Diabolocom, Artefact, MICS, CentraleSupélec, Université Paris-Saclay, Instituto Superior Técnico & Universidade de Lisboa (Lisbon ELLIS Unit), Instituto de Telecomunicações, Unbabel, Université Paris-Saclay, CNRS, LISN, INSA Rennes, IRISA, CINES, IRT Saint Exupéry, Illuin Technology, Université Grenoble Alpes, Grenoble INP, LIG, Equall, ISIA Lab
EuroBERT segna un passo significativo nell’evoluzione dell’NLP multilingue, offrendo un nuovo standard per la comprensione del linguaggio europeo e globale. La comunità è invitata a esplorarlo, testarlo e contribuire alla sua evoluzione per migliorare ulteriormente il panorama dell’intelligenza artificiale applicata al linguaggio naturale.