
L’evoluzione dell’intelligenza artificiale passa attraverso la capacità di potenziare il ragionamento dei modelli linguistici con tecniche sempre più avanzate.
Il reinforcement learning (RL) sta emergendo come una delle soluzioni più promettenti, capace di superare i limiti del pretraining convenzionale e delle tecniche di fine-tuning. Il nuovo modello QwQ-32B dimostra il potenziale di questa metodologia, offrendo prestazioni di livello paragonabile a modelli ben più grandi come DeepSeek-R1, ma con un numero significativamente inferiore di parametri attivi.
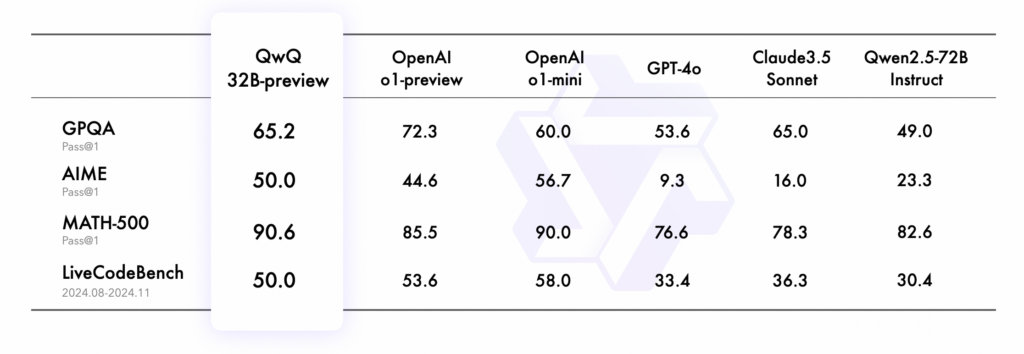
L’adozione di strategie avanzate di RL ha permesso a QwQ-32B di migliorare il ragionamento matematico, la generazione di codice e le competenze generali, introducendo inoltre capacità di interazione con strumenti e adattamento in tempo reale grazie a feedback ambientali.
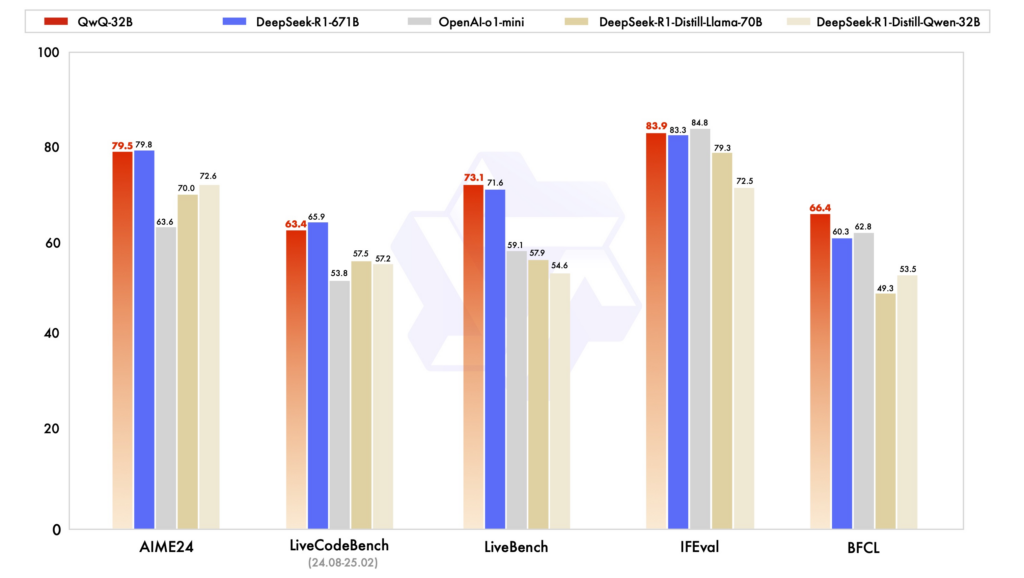
La combinazione di questi fattori rappresenta un passo decisivo verso l’Intelligenza Artificiale Generale (AGI), rendendo QwQ-32B un benchmark nell’ambito dell’intelligenza artificiale open-weight.
QwQ-32B è stato sottoposto a una serie di test rigorosi per valutare le sue capacità in matematica, programmazione e problem-solving generale. I risultati hanno evidenziato che il modello è in grado di competere con alternative di dimensioni maggiori, tra cui DeepSeek-R1-Distilled-Qwen-32B, DeepSeek-R1-Distilled-Llama-70B, o1-mini e DeepSeek-R1 originale.
Questo dimostra come il reinforcement learning possa compensare la riduzione del numero di parametri, ottimizzando l’efficienza del modello senza sacrificare la qualità del ragionamento.
L’uso strategico del reward modeling e dei verificatori di accuratezza ha giocato un ruolo chiave nel raggiungere questi risultati. In particolare, per le competenze matematiche e di coding, QwQ-32B utilizza un verificatore automatico per garantire la correttezza delle soluzioni e un server di esecuzione del codice per testare la validità dei programmi generati.
Questa approccio data-driven ha permesso di ottenere miglioramenti costanti nelle prestazioni, riducendo al minimo la necessità di intervento umano nel processo di addestramento.
Reinforcement learning: la chiave del successo
L’implementazione del reinforcement learning in QwQ-32B è stata sviluppata in due fasi principali. Nella prima, l’attenzione si è concentrata su matematica e coding, utilizzando ricompense basate sulla correttezza delle risposte. Questo ha permesso di affinare le capacità logiche del modello in modo controllato e progressivo.
Nella seconda fase, il modello è stato sottoposto a un addestramento più generico, con un reward model che ha ampliato le capacità oltre la logica formale, includendo seguire istruzioni complesse, migliorare l’allineamento con le preferenze umane e rafforzare le abilità di interazione con agenti software.
Questo livello di ottimizzazione ha permesso a QwQ-32B di raggiungere un equilibrio tra specializzazione e generalizzazione, rendendolo più versatile rispetto ai modelli tradizionali.Un aspetto fondamentale di questa architettura è che il secondo ciclo di RL è stato progettato per preservare le competenze acquisite nella prima fase, evitando regressioni nelle capacità matematiche e di programmazione.
Questo conferma che il reinforcement learning, se ben calibrato, può essere un’alternativa scalabile e sostenibile all’aumento indiscriminato del numero di parametri nei modelli linguistici.
Implementazione pratica di qwq-32b
QwQ-32B è disponibile con licenza Apache 2.0 su Hugging Face e ModelScope, ed è accessibile direttamente tramite Qwen Chat.
Per gli sviluppatori interessati, il modello può essere utilizzato con Hugging Face Transformers o tramite Alibaba Cloud DashScope API, permettendo una facile integrazione in applicazioni di AI conversazionale e reasoning avanzato. Il codice di esempio fornito dimostra come eseguire un’interrogazione al modello, generando una risposta a una domanda di logica numerica.
La flessibilità di implementazione consente di sfruttare QwQ-32B per una vasta gamma di applicazioni, dalla generazione di codice alla risoluzione di problemi complessi, fino all’uso come assistente AI per compiti specifici.verso l’intelligenza artificiale generale
QwQ-32B rappresenta un primo passo verso un futuro in cui il reinforcement learning scalato sarà un elemento cardine dell’evoluzione dell’intelligenza artificiale. L’obiettivo è sviluppare modelli sempre più efficienti, adattabili e in grado di ragionare in modo autonomo, riducendo la dipendenza da dataset statici e migliorando la capacità di apprendere dinamicamente dall’interazione con l’ambiente.
Le prospettive future includono l’integrazione di agenti basati su RL, capaci di gestire ragionamenti a lungo termine e adattarsi in tempo reale alle esigenze degli utenti. Questa direzione di ricerca potrebbe aprire la strada a modelli linguistici in grado di affrontare problemi sempre più complessi, avvicinandoci progressivamente all’AGI.
Con QwQ-32B, il team Qwen ha dimostrato che l’intelligenza artificiale non ha bisogno di un numero esorbitante di parametri per essere potente. La chiave sta nell’ottimizzazione intelligente dell’apprendimento—un concetto che nei prossimi anni potrebbe ridefinire l’intero settore.