
Il governo italiano sta valutando una newco tra Enel, Ansaldo e Leonardo per garantire stabilità al sistema. Ma sarà sufficiente?
Le audizioni parlamentari sul nucleare in Italia hanno evidenziato un crescente interesse per gli Small Modular Reactor (Smr) come soluzione per garantire adeguatezza e flessibilità al sistema energetico nel medio-lungo termine. Secondo Edison, gli Smr potrebbero contribuire per l’11-22% al mix energetico nazionale entro il 2050, offrendo continuità produttiva e minori costi di rete rispetto alle rinnovabili.
Tuttavia, i costi restano un punto critico: il prezzo dell’energia prodotta potrebbe aggirarsi intorno ai 100 euro per Megawattora, con un costo capitale tra 3 e 5 milioni di euro per Megawatt, per un totale stimato tra 4,8 e 8 miliardi di euro per 1,6 Gigawatt attesi tra il 2035 e il 2040.
Studi ci dicono che entro il 2030 (source IFP), l’addestramento dei modelli di intelligenza artificiale di frontiera richiederà data center capaci di consumare cinque gigawatt di potenza, l’equivalente dell’energia necessaria per alimentare 10 città come Milano (0,6975). Questo scenario prospetta una domanda energetica senza precedenti, che pone interrogativi cruciali sull’infrastruttura e la sostenibilità.
Senza Citare l’Europa, gli stessi Stati Uniti, attualmente, non dispongono delle risorse energetiche sufficienti per costruire strutture di tale portata in un unico luogo. La soluzione potrebbe risiedere in un approccio innovativo e radicale: il training decentralizzato dell’IA.
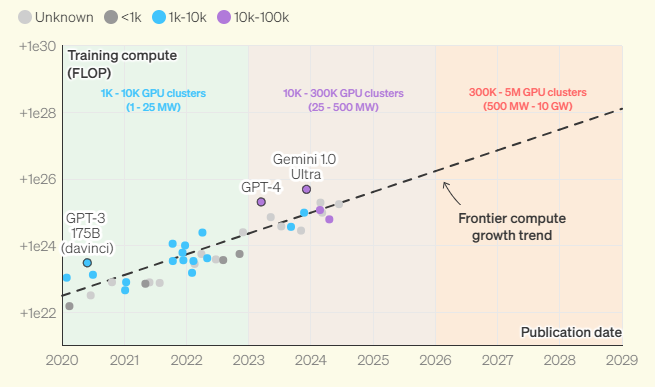
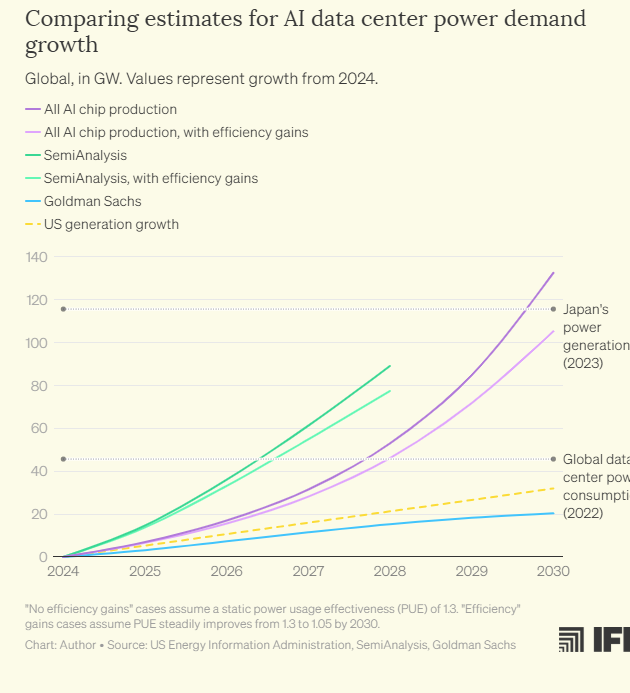
Il training decentralizzato è una tecnica avanzata che distribuisce il carico computazionale dell’addestramento dei modelli IA su più server o data center dislocati geograficamente.
Questo metodo non solo consente di superare le limitazioni infrastrutturali ed energetiche, ma si dimostra anche più agile e scalabile. Costruire molti piccoli data center risulta infatti più praticabile rispetto alla creazione di un’unica megastruttura. Inoltre, la distribuzione della richiesta energetica su più stati o contee allevia notevolmente la pressione sulle reti locali, rendendo il fabbisogno energetico più gestibile.
Tradizionalmente, l’addestramento di un nuovo modello di intelligenza artificiale avviene in un unico, enorme data center. Durante la fase di pre-training, enormi quantità di dati raccolti dal web vengono elaborate dai chip che, analizzando un lotto di informazioni, apportano piccole modifiche ai pesi del modello per migliorarne le prestazioni.
Questi aggiornamenti vengono sincronizzati continuamente tra i vari chip. Dopo miliardi di iterazioni, il modello pre-addestrato è pronto per l’affinamento, per essere poi trasformato in un chatbot efficace o in altre applicazioni avanzate.
Tuttavia, distribuire questo processo su più data center presenta sfide complesse. La necessità di comunicazioni costanti tra i chip comporta aggiornamenti multipli al secondo, il che richiede velocità e sincronizzazione impeccabili.
Ogni volta che un dato viene trasferito tra chip o cavi, si verifica un ritardo fisso dovuto al caricamento e allo scaricamento delle informazioni ad ogni punto di connessione. Nei data center centralizzati, questi ritardi sono minimizzati tramite collegamenti diretti tra i chip, ma su distanze maggiori, le connessioni intermedie causano accumulo di latenze.
Uno dei limiti più significativi per la distribuzione su lunghe distanze è la velocità della luce stessa. Nei cavi in fibra ottica, i dati viaggiano a circa due terzi della velocità della luce, causando ritardi significativi quando enormi quantità di informazioni devono percorrere lunghe distanze attraverso cavi a larghezza di banda limitata. Questa problematica si aggrava ulteriormente man mano che i modelli diventano sempre più grandi, richiedendo flussi di dati sempre maggiori tra i chip.
Nonostante le difficoltà, la possibilità di distribuire il training su più piccoli data center è al centro di nuove ricerche e sviluppi infrastrutturali. Tecniche come DiLoCo consentono un approccio decentralizzato permettendo a diverse parti del modello di aggiornarsi in modo asincrono, ovvero leggermente fuori sincrono, prima di riconciliarsi con le controparti presenti in altri data center.
Questa metodologia (in Allegato) ha già dimostrato la sua efficacia nell’addestramento di modelli da 10 miliardi di parametri, che pur essendo molto più piccoli dei modelli più avanzati, rappresentano comunque un risultato notevole.
Parallelamente, sul fronte infrastrutturale, le aziende stanno implementando più cavi in fibra ottica tra le loro strutture per aumentare il flusso di informazioni, riducendo i colli di bottiglia e il numero di punti di connessione che aggiungono latenza.
Tuttavia, sebbene queste soluzioni rendano possibile l’addestramento distribuito, ciò avviene a scapito dell’efficienza. Non è chiaro esattamente quanto si perda in termini di prestazioni, ma il fatto che molte aziende continuino a investire in enormi data center centralizzati indica che il compromesso in termini di efficienza è ancora rilevante.
Nonostante questo, alcuni segnali indicano che i giganti dell’AI stanno già sperimentando il training decentralizzato.
Microsoft e OpenAI sembrano aver trovato il modo di addestrare modelli su più data center. Microsoft, in particolare, ha stipulato contratti per oltre 10 miliardi di dollari con aziende di fibra ottica per collegare i suoi data center, mentre Google DeepMind ha utilizzato più siti per addestrare il suo primo modello Gemini, anche se non è chiaro quanti e quanto distanti fossero tra loro.
Uno dei timori principali legati al training decentralizzato riguarda l’impatto sulle politiche di governance dell’AI. Distribuendo l’addestramento su più data center più piccoli, potrebbe diventare molto più difficile per i governi tracciare chi possiede la potenza di calcolo necessaria per sviluppare modelli AI di frontiera.
Al momento, monitorare enormi data center multi-gigawatt è relativamente semplice, ma se le aziende abbandonassero queste strutture in favore di data center più piccoli e diffusi, i governi potrebbero faticare a individuare i detentori dei chip di calcolo avanzati.
Tuttavia, i ricercatori ritengono che questi timori siano esagerati. Anche in uno scenario decentralizzato, solo una dozzina di aziende possiede data center in grado di fornire la potenza di calcolo necessaria per i modelli più avanzati.
Costruire piccoli data center su larga scala richiederebbe investimenti multimilionari o addirittura miliardari, limitando questa possibilità solo ai giganti tecnologici e alle aziende IaaS (Infrastructure as a Service). Inoltre, le aziende IaaS monitorano già l’utilizzo della rete e delle risorse dei propri clienti, consentendo loro di identificare chi utilizza grandi quantità di calcolo distribuito.
Reinforcement Learning e il Futuro del Training Decentralizzato
Una potenziale svolta per l’addestramento decentralizzato potrebbe derivare dall’evoluzione del reinforcement learning (RL). A differenza del pre-training tradizionale, l’RL richiede meno aggiornamenti tra i chip, riducendo quindi le esigenze di rete.
Questa caratteristica potrebbe rendere più facile decentralizzare l’addestramento, spingendo le aziende ad adottare questo approccio su larga scala. Se l’RL diventasse una componente chiave nello sviluppo di modelli AI, potrebbe eliminare alcuni dei vincoli che attualmente rendono facile per i governi monitorare l’addestramento decentralizzato, come la necessità di grandi impianti o di cavi in fibra ottica su vasta scala.
Tuttavia, il panorama è altamente incerto. Il paradigma dell’RL è ancora poco compreso, e il settore dell’AI si evolve rapidamente. Questo potrebbe lasciare i governi in difficoltà nel tenere il passo con i cambiamenti, aprendo scenari ancora inesplorati per la regolamentazione dell’AI.
Il futuro dell’addestramento decentralizzato si prospetta dunque pieno di opportunità e sfide, non solo dal punto di vista tecnico, ma anche sul piano della governance e delle politiche di regolamentazione. Con l’evoluzione costante dei modelli AI e delle tecniche di addestramento, resta da vedere come le aziende e i governi sapranno adattarsi a questo nuovo paradigma.