L’Intelligenza Artificiale generativa ha subito una rapida evoluzione, ma dietro l’apparente complessità dei modelli come quelli di OpenAI si cela un’architettura che, sebbene potente, è sorprendentemente semplice da imitare. Non si tratta di magia o di una tecnologia inaccessibile a chi non dispone di miliardi di dollari in investimenti. Al contrario, il cuore di questi modelli è composto da strutture matematiche note, dataset disponibili pubblicamente e tecniche di training replicabili con costi relativamente bassi.
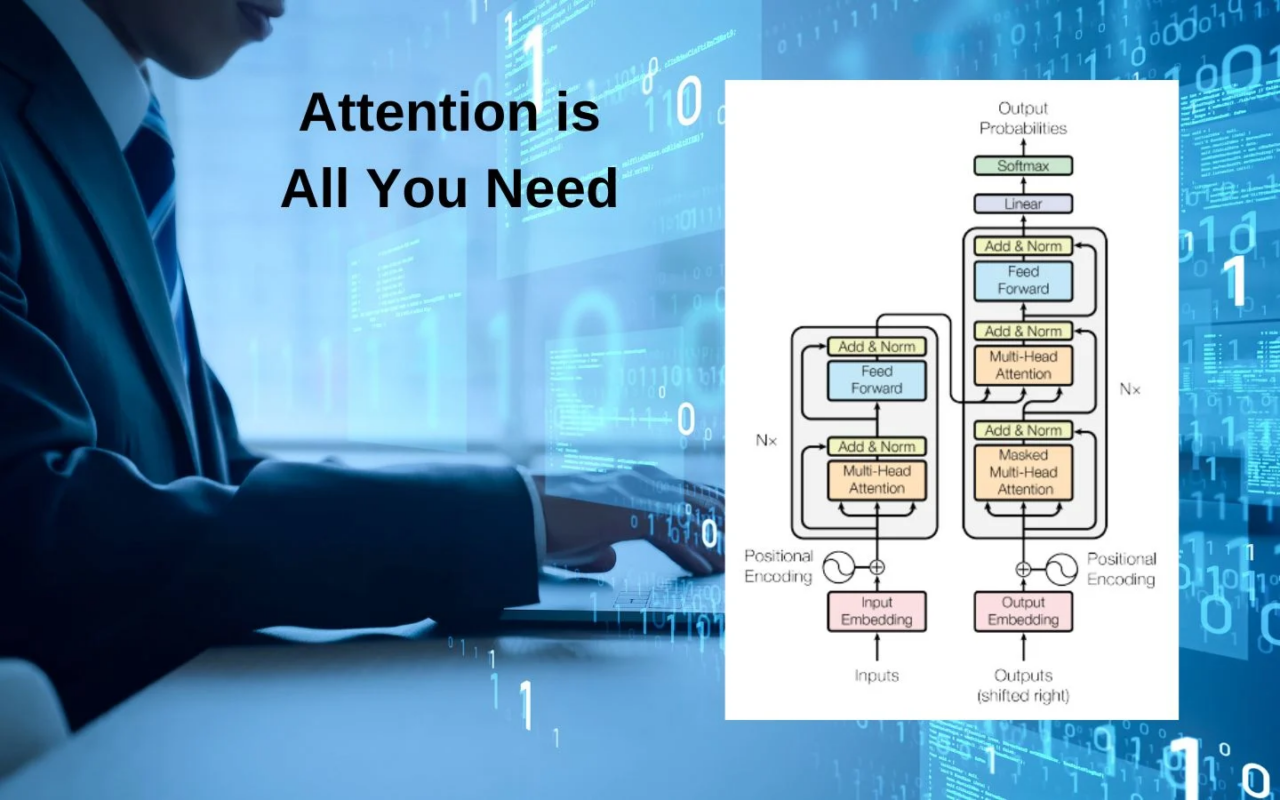
L’architettura di base dei modelli di linguaggio avanzati è il trasformatore, introdotto da Google nel 2017 con il celebre paper Attention Is All You Need. Questo meccanismo, basato sull’auto-attenzione e su una scalabilità computazionale efficace, è oggi il fondamento di molte IA generative. OpenAI non ha inventato nulla di radicalmente nuovo, ma ha ottimizzato un paradigma già noto. Proprio per questo, aziende, startup e persino singoli ricercatori possono riprodurre modelli simili con risorse limitate, sfruttando framework open-source come Hugging Face, PyTorch e TensorFlow.
Il costo dell’addestramento di un modello su larga scala è spesso enfatizzato per scoraggiare la concorrenza, ma la realtà è più sfumata. Modelli più piccoli, addestrati su dataset specializzati, possono raggiungere prestazioni paragonabili a quelle di un grande modello generalista, con una frazione dei costi. In molti settori, la qualità del dataset conta più della dimensione del modello, e la proliferazione di tecniche di fine-tuning e distillazione consente di ottenere risultati impressionanti con budget contenuti.
L’accesso ai dati è un altro fattore chiave. Mentre OpenAI ha potuto addestrare i suoi modelli su enormi quantità di testo, molte di queste fonti sono pubblicamente disponibili o possono essere surrogate con strategie alternative. Web scraping, dataset open-source e archivi storici offrono una base dati sufficiente per creare modelli competitivi senza dover ricorrere a risorse proprietarie. Inoltre, l’evoluzione delle architetture consente di ridurre il compute cost senza sacrificare la qualità delle risposte.
Proprio perché la tecnologia non è più esclusiva, colossi come Amazon e Microsoft stanno cercando di capitalizzare sulla loro infrastruttura cloud, offrendo modelli open-source come DeepSeek sui loro hardware costosi. L’obiettivo non è democratizzare l’IA, ma piuttosto vincolare le aziende e i ricercatori all’uso delle loro GPU e TPU proprietarie, creando una nuova forma di lock-in tecnologico. AWS e Azure sanno bene che l’IA può essere riprodotta ovunque, ma il vero business è il costo computazionale: chiunque voglia competere nel settore avrà bisogno di hardware ad alte prestazioni, e quale miglior modo per garantirsi una fetta del mercato se non offrendo accesso a modelli open-source che, paradossalmente, sono nati per rendere l’IA più accessibile?
L’illusione dell’unicità dei modelli di OpenAI è in gran parte una costruzione mediatica. Il valore reale non risiede tanto nella tecnologia in sé, quanto nell’infrastruttura, nel marketing e nell’integrazione con ecosistemi aziendali. Questo significa che, per chiunque abbia una strategia mirata e una visione chiara, replicare e persino superare questi modelli è non solo possibile, ma economicamente vantaggioso, a patto di non cadere nella trappola dei costi nascosti dell’hardware proprietario imposto dai giganti del cloud.