Mistral AI ha lanciato Mistral Small 3, un modello di linguaggio che offre prestazioni competitive rispetto a colossi come Llama 3.3 70B e Qwen 32B, ma con una velocità di oltre tre volte superiore sulla stessa infrastruttura hardware. Questa nuova release si posiziona come una soluzione potente e leggera per la maggior parte delle applicazioni di intelligenza artificiale generativa, offrendo un equilibrio ottimale tra efficienza e capacità di elaborazione.
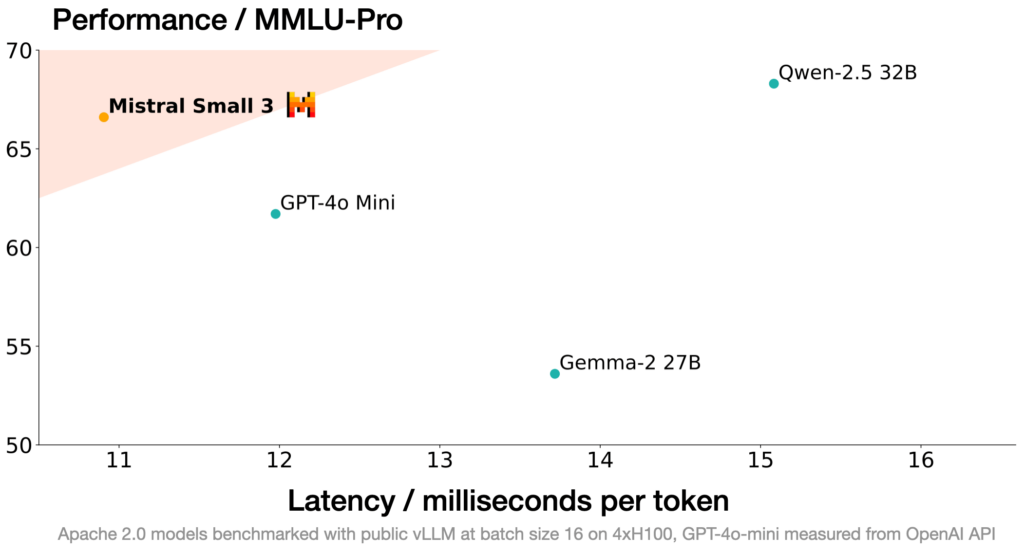
Progettato per il deployment locale, Mistral Small 3 vanta una profondità di rete ridotta rispetto ai suoi competitor, il che si traduce in un tempo di inferenza nettamente inferiore. Con una precisione superiore all’81% su MMLU e una velocità di 150 token al secondo, si afferma come il modello più efficiente della sua categoria. La sua licenza Apache 2.0 consente agli sviluppatori di personalizzarlo liberamente, rendendolo un’opzione interessante per chi cerca una base solida per l’intelligenza artificiale open-source.
Prestazioni e Benchmark
Il team di Mistral ha condotto test di valutazione indipendenti, confrontando Small 3 con altri modelli attraverso oltre 1.000 prompt, tra cui codice, conoscenze generali e istruzioni complesse. Nonostante sia un modello di dimensioni più contenute, ha dimostrato di reggere il confronto con modelli chiusi come GPT-4o-mini e di superare alternative open-source ben più grandi in vari benchmark.
L’accuratezza del modello è stata testata su metriche come Wildbench, Arena Hard e MTBench, convalutate da GPT-4o, confermando l’affidabilità delle sue risposte. Nonostante non sia stato addestrato con reinforcement learning né con dati sintetici, Mistral Small 3 si dimostra un’ottima base per ulteriori sviluppi, in particolare per chi desidera potenziare le capacità di ragionamento attraverso il fine-tuning.
Applicazioni e Scenari d’Uso
Mistral Small 3 sta emergendo come una scelta ideale per diversi scenari, tra cui:
- Assistenti Conversazionali a Bassa Latenza: Perfetto per chatbot e AI interattive che necessitano di risposte istantanee.
- Automazione e Funzioni Programmabili: Ottimizzato per l’esecuzione rapida di funzioni in flussi di lavoro automatizzati.
- Fine-Tuning per Esperti di Settore: Personalizzabile per settori come diritto, medicina e supporto tecnico, garantendo risposte specializzate.
- Inferenza Locale e Privacy: Può essere eseguito su hardware accessibile, come una RTX 4090 o un MacBook con 32GB di RAM, permettendo un’elaborazione privata senza necessità di cloud computing.
Tra i principali settori in cui viene adottato troviamo:
- Finanza: Rilevazione di frodi in tempo reale.
- Sanità: Assistenza ai pazienti e triage intelligente.
- Industria e Robotica: Controllo avanzato dei dispositivi su hardware locale.
- Servizi Clienti e Analisi del Sentimento: Miglioramento dell’esperienza utente attraverso un’analisi linguistica rapida ed efficace.
Un Futuro Open e Accessibile
Mistral Small 3 è ora disponibile su la Plateforme come mistral-small-latest o mistral-small-2501. Questo modello rappresenta un passo avanti per l’open-source, offrendo un’alternativa accessibile e potente ai modelli proprietari. Con una combinazione di prestazioni elevate e bassa latenza, si candida a diventare uno degli strumenti preferiti per chi cerca un AI efficiente, veloce e personalizzabile. Leggi di piu’, documentazione.