Nel mondo dell’intelligenza artificiale, la gestione e l’ottimizzazione dei modelli linguistici di grandi dimensioni (LLM) è diventata un aspetto cruciale per il successo delle applicazioni basate su IA. Sebbene i modelli LLM alimentino una vasta gamma di applicazioni, il monitoraggio delle loro performance, dei costi e dei comportamenti rimane una sfida significativa. Gli strumenti di osservabilità esistenti spesso non forniscono approfondimenti completi, rendendo difficile la risoluzione dei problemi e il miglioramento continuo. Inoltre, il mantenimento della privacy dei dati e la conformità alle normative aumentano ulteriormente la complessità di queste operazioni.
Helicone emerge come una piattaforma open-source progettata per risolvere questi problemi, offrendo una soluzione avanzata per monitorare, valutare e ottimizzare i modelli LLM con una sola linea di codice. In un mondo dove l’efficienza è la chiave, Helicone promette di semplificare e accelerare il lavoro degli sviluppatori e dei team che gestiscono progetti di IA su larga scala.
Un Monitoraggio Semplice e Potente
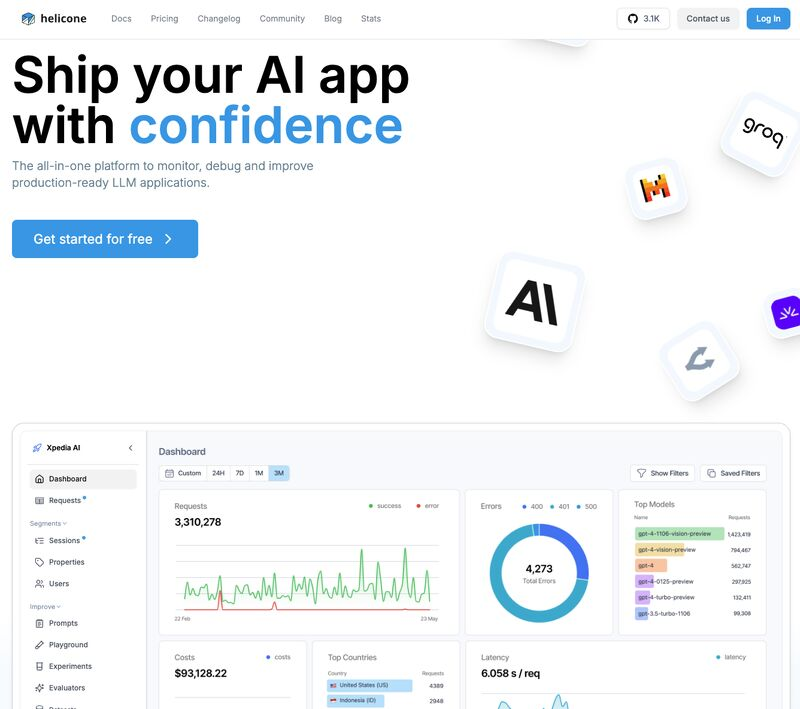
Una delle caratteristiche distintive di Helicone è la sua capacità di gestire la complessità dei modelli LLM in modo semplice ed efficace. Grazie alla sua architettura scalabile, gli sviluppatori possono monitorare le performance in tempo reale, osservando metriche cruciali come latenza e costi. La possibilità di integrare facilmente l’osservabilità nelle proprie pipeline di sviluppo con una singola linea di codice è un vantaggio significativo, consentendo di risparmiare tempo e risorse.
Helicone offre strumenti avanzati per la gestione dei prompt, che permettono di sperimentare e versionare i prompt utilizzando dati di produzione. Inoltre, i parametri di monitoraggio sono altamente configurabili, il che consente di personalizzare l’osservabilità in base alle esigenze specifiche di ogni progetto. Questi strumenti non solo migliorano l’efficacia dei modelli LLM, ma anche la trasparenza del loro comportamento, facilitando il debugging e l’ottimizzazione delle performance.
Ottimizzazione dei Costi e delle Risorse
In un’epoca in cui le risorse sono limitate e i costi dell’IA continuano a crescere, la capacità di monitorare e ottimizzare i costi è fondamentale. Helicone permette di ottenere visibilità dettagliata sulle spese associate ai modelli LLM, offrendo gli strumenti necessari per gestire in modo efficiente i costi operativi. La comprensione dei costi in tempo reale consente ai team di prendere decisioni più informate e di ridurre gli sprechi, contribuendo così a ottimizzare gli investimenti in tecnologia.
Integrità e Privacy dei Dati
La sicurezza e la privacy dei dati sono priorità assolute per ogni progetto di IA. Helicone è progettato per garantire che i dati siano trattati in modo sicuro e conforme alle normative, senza compromettere la performance o la facilità d’uso. Con l’introduzione di funzionalità avanzate per l’integrazione e il controllo dei dati, le organizzazioni possono avere la tranquillità di sapere che i loro modelli LLM sono gestiti nel rispetto dei più alti standard di sicurezza.
Un Ecosistema Open-Source in Continua Evoluzione
Essendo un progetto open-source, Helicone beneficia di un’ampia comunità di sviluppatori che contribuiscono costantemente al miglioramento e all’evoluzione della piattaforma. Questo approccio collaborativo consente di avere una soluzione in continua evoluzione, sempre al passo con le nuove sfide tecnologiche e normative. La trasparenza e l’accessibilità del codice sorgente permettono anche alle organizzazioni di personalizzare Helicone secondo le loro specifiche esigenze, ottenendo il massimo dal loro investimento in intelligenza artificiale.
Il Futuro della Gestione dei Modelli LLM
In un panorama in rapida evoluzione, Helicone rappresenta una risorsa fondamentale per chiunque desideri ottimizzare i propri modelli linguistici di grandi dimensioni senza dover affrontare la complessità di soluzioni proprietarie costose e difficili da implementare. Con Helicone, le organizzazioni possono finalmente ottenere il massimo dal loro investimento in LLM, migliorando le performance, ottimizzando i costi e garantendo la sicurezza dei dati, il tutto con una piattaforma scalabile e facile da integrare. Non è mai stato così facile monitorare, valutare e ottimizzare i modelli LLM in modo efficace.
Repository: https://github.com/hatchet-dev/hatchet
Website: https://www.helicone.ai/