
DeepSeek AI ha presentato DeepSeek-R1, un modello open source che si pone come un diretto concorrente del noto OpenAI-o1 nei compiti di ragionamento complesso. Questo traguardo è stato raggiunto grazie all’introduzione di un algoritmo innovativo chiamato Group Relative Policy Optimization (GRPO) e a un approccio multi-stage basato sul reinforcement learning (RL). La combinazione di queste tecniche ha consentito di superare molte delle limitazioni tradizionali nei modelli di intelligenza artificiale per il ragionamento avanzato.
Group Relative Policy Optimization (GRPO): Una Nuova Frontiera nel Reinforcement Learning
GRPO è un algoritmo di ottimizzazione del reinforcement learning che elimina la necessità di un modello di funzione di valore (value function), semplificando significativamente il processo di addestramento e riducendo l’uso di memoria. Invece di basarsi su stime individuali, GRPO utilizza punteggi medi calcolati su gruppi di risultati generati per un singolo prompt. Questo approccio riduce l’overhead computazionale e migliora la capacità del modello di concentrarsi su compiti complessi come il ragionamento matematico.
L’algoritmo prevede quattro fasi principali:
- Generazione di campioni: vengono prodotti più output per ogni prompt utilizzando la politica corrente.
- Valutazione del punteggio: ogni output viene valutato tramite una funzione di reward, che può essere basata su regole o risultati.
- Calcolo del vantaggio: il reward medio del gruppo di output viene usato come baseline, e il vantaggio di ogni soluzione viene calcolato rispetto a questa baseline.
- Ottimizzazione della politica: l’obiettivo di GRPO include i vantaggi calcolati e un termine di divergenza KL direttamente nella funzione di perdita, rendendolo diverso dal tradizionale Proximal Policy Optimization (PPO).
Questo approccio consente un addestramento più robusto e focalizzato sui risultati, evitando la complessità e i problemi di convergenza spesso associati al PPO.
Reinforcement Learning Puro: R1-zero
L’addestramento di DeepSeek-R1 è iniziato con un modello base chiamato R1-zero, sviluppato applicando GRPO a compiti di completamento di testo non supervisionati con modelli di reward basati su regole. Questo includeva:
- Accuracy rewards: per valutare la correttezza di risposte matematiche o soluzioni di codice.
- Format rewards: per garantire che il modello presentasse il proprio processo di pensiero in formato leggibile, utilizzando tag speciali.
I risultati sono stati straordinari: il punteggio pass@1 sul dataset AIME 2024 è passato dal 15,6% al 71,0%, raggiungendo livelli di prestazione paragonabili al modello OpenAI-o1-0912. Tuttavia, questo approccio iniziale ha portato a problemi di leggibilità e mescolanza linguistica, risolti con un successivo approccio multi-stage.
Addestramento Multi-Stage di DeepSeek R1
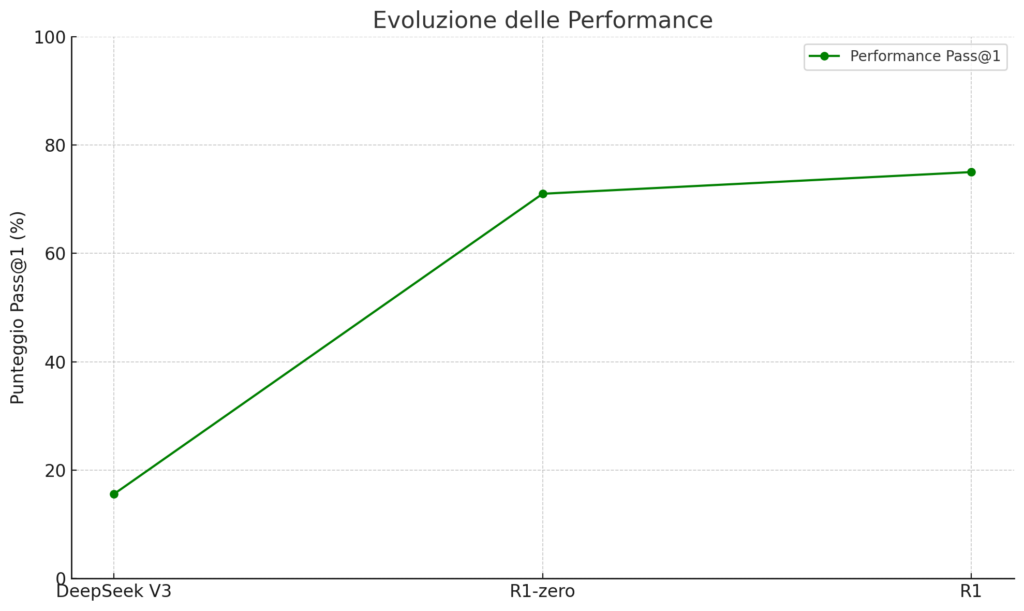
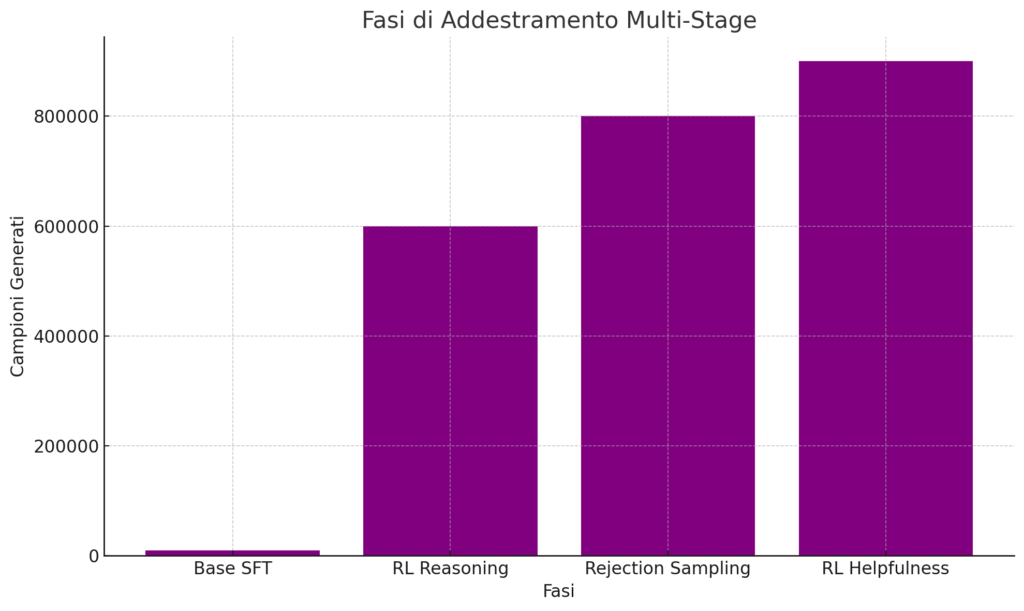
Per perfezionare le capacità del modello e garantire stabilità sin dalle prime fasi di addestramento, il team ha utilizzato un approccio in quattro fasi:
Fase 1: Supervised Fine-Tuning (SFT)
Il modello base è stato raffinato utilizzando dati annotati con catene di pensiero (Chain-of-Thought, CoT) di oltre 10.000 token, generati sia da R1-zero che da annotatori umani. Questo ha migliorato la coerenza linguistica e la leggibilità.
Fase 2: Reinforcement Learning per il Ragionamento
GRPO è stato applicato nuovamente per affinare le capacità di ragionamento in compiti intensivi come matematica e programmazione. È stato aggiunto un reward specifico per la coerenza linguistica, aiutando il modello a mantenere una lingua uniforme.
Fase 3: Rejection Sampling e SFT
Un ampio dataset sintetico è stato generato utilizzando il Rejection Sampling. Questo approccio ha prodotto 600.000 campioni legati al ragionamento e 200.000 per compiti più generali, come scrittura creativa e simulazione di ruoli, utilizzando DeepSeek V3 come giudice.
Fase 4: RL per Helpfulness
Nella fase finale, GRPO è stato combinato con modelli di reward sia basati su regole che sui risultati, per migliorare l’utilità e la sicurezza del modello.
Risultati e Sorprese
Il modello DeepSeek-R1 ha dimostrato che un approccio ben strutturato basato su GRPO e RL può portare a miglioramenti significativi, anche senza utilizzare tecniche avanzate come Monte Carlo Tree Search (MCTS). Inoltre, i reward semplici basati su accuratezza e formato si sono rivelati più efficaci rispetto a modelli di reward più complessi.
Questo modello open source rappresenta una pietra miliare, non solo per le sue capacità tecniche, ma anche per il potenziale impatto sull’accessibilità di soluzioni avanzate di AI nel campo del ragionamento.
Newsletter – Non perderti le ultime novità sul mondo dell’Intelligenza Artificiale: iscriviti alla nostra newsletter gratuita e accedi ai contenuti esclusivi di Rivista.AI direttamente nella tua casella di posta!