La generazione aumentata dal recupero delle informazioni (Retrieval-Augmented Generation, RAG) si evolve con l’introduzione del Chain-of-Retrieval Augmented Generation (CoRAG), che combina il potere del recupero iterativo con modelli di ragionamento Chain-of-Thought (CoT). Questo approccio consente di affrontare domande complesse suddividendo il processo in passaggi successivi, recuperando informazioni rilevanti e ragionando su di esse prima di generare una risposta finale.
Cos’è il CoRAG?
Il CoRAG migliora il tradizionale RAG integrando un ragionamento passo-passo, emulando il modo in cui un essere umano affronta domande a più livelli (multi-hop). Questo approccio si rivela cruciale in contesti dove una semplice pipeline “query-risposta” non è sufficiente, come nei task di domande complesse o nei problemi che richiedono più passaggi logici per essere risolti.
Come Implementare il CoRAG
- Preparazione del Dataset
Il primo passo è la raccolta di un dataset adatto, come KILT o HotpotQA, progettato per domande a più passaggi. È essenziale che il dataset contenga non solo la domanda e la risposta finale, ma anche i passaggi intermedi del ragionamento (catena di ragionamenti) per addestrare il modello su esempi completi e strutturati. - Recupero delle Informazioni con Reject Sampling
Implementa un sistema di recupero, come Dense Passage Retrieval (DPR) o BM25, per generare percorsi multipli di recupero per ogni domanda. A questo punto, utilizza il metodo del Reject Sampling, scartando i percorsi che non portano a risposte corrette. In pratica, il sistema genera diverse “catene di recupero” (retrieval chains) e conserva solo quelle che conducono alla risposta corretta tramite ragionamento coerente. - Filtraggio e Fine-Tuning del Modello
Dopo aver selezionato le catene di recupero valide, utilizza questi esempi filtrati per il fine-tuning del modello linguistico di base (ad esempio, GPT o un altro modello LLM). Questo passaggio consente al modello di apprendere come gestire il ragionamento multi-hop e rafforza la capacità di generare risposte basate su catene di informazioni accurate. - Inferenza Iterativa
Durante l’inferenza, il modello utilizza il ragionamento iterativo. Ad esempio:- Recupera informazioni iniziali in base alla domanda.
- Riformula la domanda sulla base di ciò che è stato trovato.
- Continua il processo fino a raggiungere la risposta finale.
Vantaggi e Insight del CoRAG
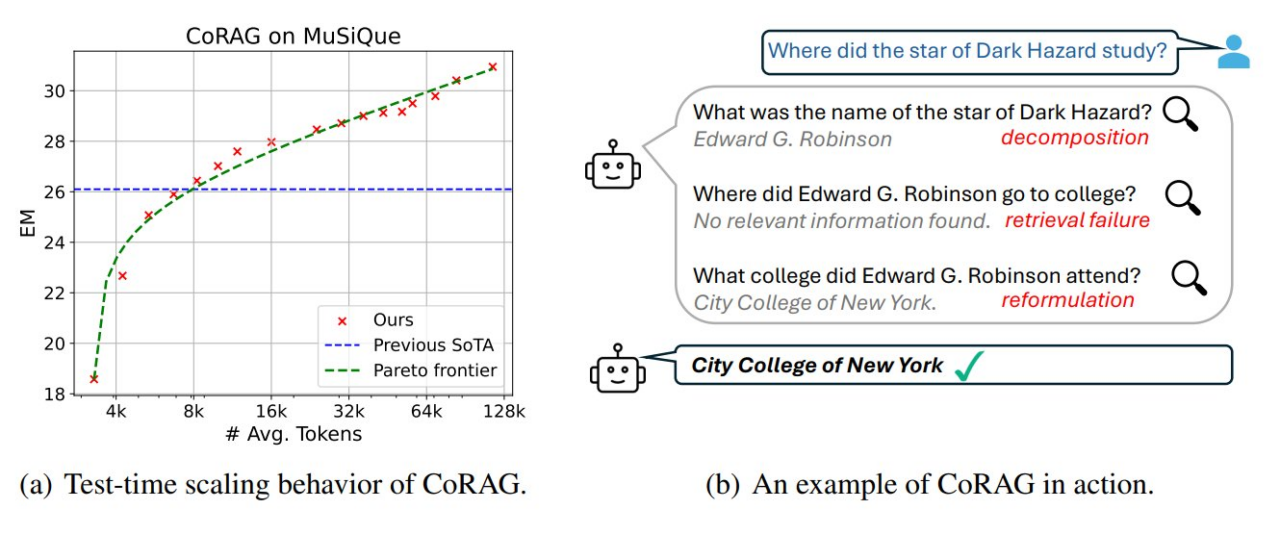
Miglioramento del punteggio QA Multi-Hop: Il CoRAG ha dimostrato di migliorare significativamente i punteggi nei task di domande a più passaggi, con un incremento di oltre 10 punti Exact Match (EM).
Performance scalabile con risorse di calcolo: Aumentare il tempo di calcolo durante la fase di test migliora le prestazioni, poiché il modello può iterare e affinare i recuperi più volte.
Retriever più forti, prestazioni migliori: L’uso di retriever avanzati, come DPR, porta a una maggiore precisione complessiva.
Impatto del CoT nelle domande multi-hop: Il ragionamento step-by-step ha il maggiore impatto quando la domanda richiede la concatenazione di informazioni provenienti da più fonti.
🏆 Risultati SOTA (State-of-the-Art) su benchmark: CoRAG ha raggiunto risultati all’avanguardia su benchmark come KILT, dimostrando la sua efficacia nel rispondere a domande complesse.
Promesse del CoRAG nel Futuro
L’integrazione del ragionamento iterativo nei modelli linguistici rappresenta una nuova frontiera per l’IA generativa. Con l’approccio CoRAG, è possibile combinare potenza computazionale e processi di ragionamento umano, aprendo nuove possibilità in ambiti come la ricerca scientifica, l’educazione e la generazione di contenuti complessi.