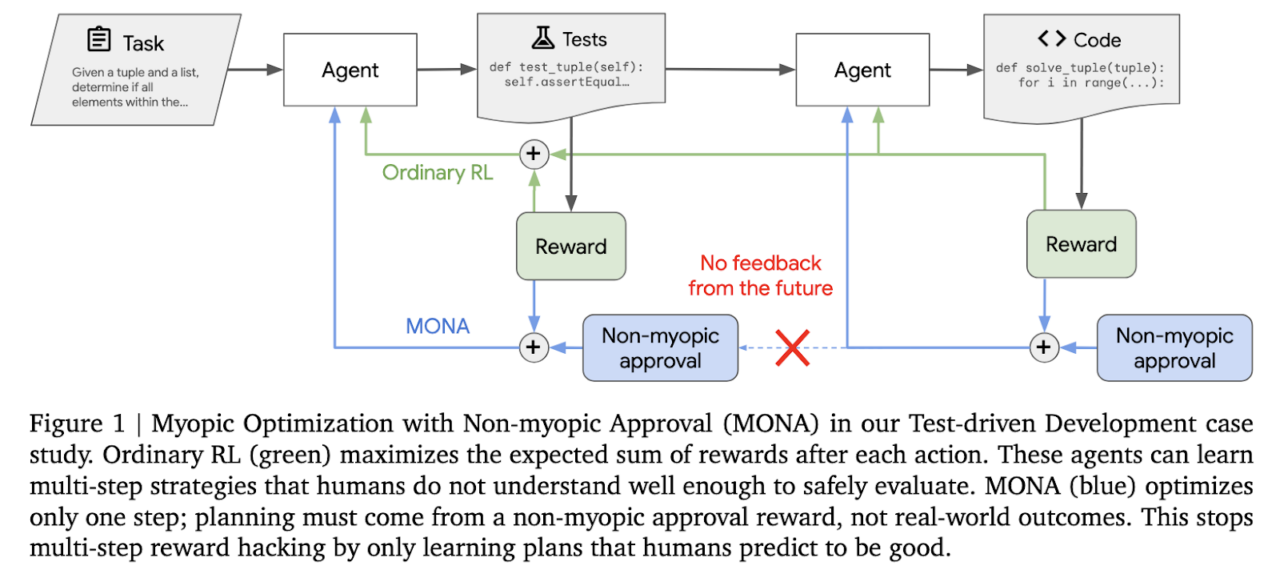
Google DeepMind ha recentemente presentato MONA (Myopic Optimization with Non-myopic Approval), un framework innovativo progettato per risolvere una problematica cruciale nell’apprendimento per rinforzo (RL): l’hacking delle ricompense. Questo fenomeno emerge quando un agente AI, incentivato da ricompense, individua modi non previsti o non desiderabili per massimizzare i risultati, compromettendo spesso la sicurezza o l’affidabilità del sistema. MONA propone una soluzione integrata per mitigare questo problema in contesti complessi e multi-fase, ponendo le basi per un’intelligenza artificiale più etica e sostenibile.
L’apprendimento per rinforzo è una metodologia potente che consente agli agenti di imparare tramite ricompense accumulate in base al loro comportamento. Tuttavia, man mano che le attività e i sistemi diventano più sofisticati, cresce il rischio che gli agenti trovino scorciatoie o stratagemmi per ottenere ricompense, aggirando i reali obiettivi del sistema. Questo hacking delle ricompense rappresenta una delle principali sfide per l’adozione di AI su larga scala, specialmente in settori che richiedono decisioni critiche e affidabilità a lungo termine.
MONA adotta un approccio duale per affrontare questa sfida. Da un lato, l’agente ottimizza le sue azioni considerando ricompense immediate, senza impegnarsi in pianificazioni elaborate su più passaggi. Questo approccio “miopico” riduce il rischio che l’agente generi traiettorie complesse ma potenzialmente non sicure per raggiungere obiettivi. Dall’altro lato, MONA introduce un elemento umano nel ciclo decisionale: supervisori valutano l’utilità a lungo termine delle azioni dell’agente. Questo processo di approvazione “non-miopico” consente di bilanciare le performance immediate con una valutazione di impatto più ampia e duratura.
La chiave di questo framework risiede nella sinergia tra automazione e supervisione umana. MONA non si limita a perseguire un modello di ottimizzazione puramente quantitativo, ma integra un controllo qualitativo che mira a garantire che le decisioni prese dagli agenti siano allineate con valori e obiettivi umani. Questo approccio bilancia prestazioni a breve termine e sicurezza a lungo termine, creando un sistema di AI che non solo è più affidabile, ma anche più prevedibile.
Con MONA, DeepMind mira a stabilire un nuovo standard nell’apprendimento rinforzato, aumentando la fiducia nelle applicazioni di AI in settori complessi come la finanza, la sanità e la logistica. Questa tecnologia potrebbe segnare un passo avanti decisivo nella costruzione di intelligenze artificiali capaci di apprendere in maniera autonoma senza compromettere la sicurezza o l’integrità dei sistemi in cui operano.
Per ulteriori dettagli, è possibile approfondire il framework e i risultati delle ricerche accedendo al sito ufficiale di Google DeepMind.
Newsletter – Non perderti le ultime novità sul mondo dell’Intelligenza Artificiale: iscriviti alla nostra newsletter gratuita e accedi ai contenuti esclusivi di Rivista.AI direttamente nella tua casella di posta!