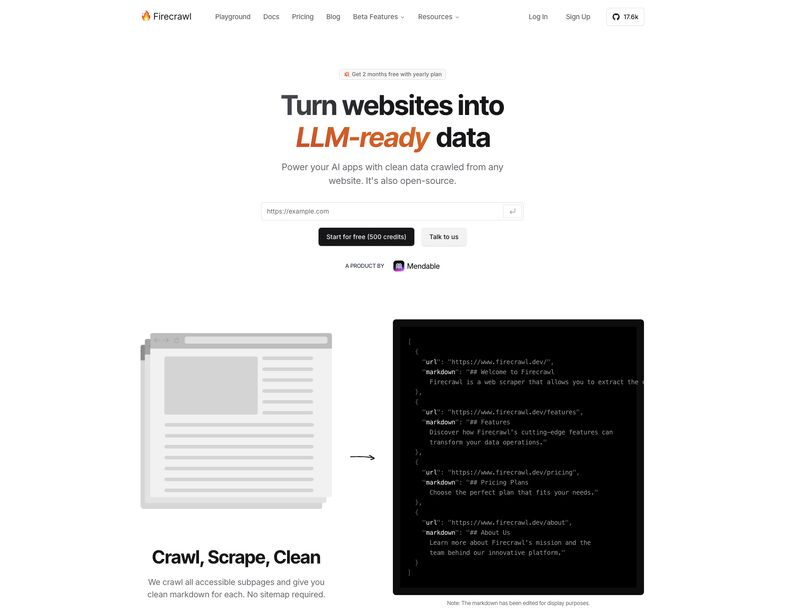
Nel panorama tecnologico moderno, l’estrazione di dati da siti web è diventata una necessità fondamentale per alimentare motori di ricerca, raccogliere informazioni e alimentare intelligenze artificiali. Tradizionalmente, questo processo ha richiesto l’uso di molteplici strumenti e framework, ognuno dei quali era specializzato in una parte del flusso di lavoro, che includeva il crawling, lo scraping e l’estrazione di contenuti. Tuttavia, l’evoluzione delle esigenze e delle soluzioni ha portato all’emergere di strumenti avanzati che semplificano tutto il processo. Firecrawl è una di queste innovazioni rivoluzionarie, che offre una soluzione all-in-one per la raccolta e l’elaborazione dei dati da qualsiasi sito web.
Firecrawl è un’API open-source progettata per ottimizzare l’estrazione dei dati da pagine web, permettendo di ottenere informazioni strutturate e pulite pronte per essere utilizzate in applicazioni di intelligenza artificiale, tra cui modelli di linguaggio di grandi dimensioni (LLM). Questa API è capace di combinare scraping, crawling e l’estrazione dei dati in un unico pacchetto, riducendo drasticamente la complessità per chi sviluppa applicazioni basate sull’elaborazione di dati web.
Scraping e Crawling Avanzato con una Soluzione Unica
Firecrawl è molto più di un semplice strumento di scraping. La sua capacità di raccogliere contenuti in formati pronti per l’uso nei LLM, come markdown, JSON e HTML, rappresenta un enorme vantaggio. Non solo raccoglie i dati grezzi da qualsiasi sito web, ma li converte in formati strutturati che possono essere immediatamente utilizzati per addestrare modelli di linguaggio o per altre applicazioni di intelligenza artificiale. Questo processo elimina la necessità di una fase di pre-processing complessa che, tradizionalmente, sarebbe stata necessaria per adattare i dati raccolti.
Inoltre, la funzione di crawling avanzato permette di estrarre tutti i link di una pagina specifica. Questo significa che Firecrawl non solo estrae i dati, ma è anche in grado di mappare l’intera struttura di collegamenti di un sito web, creando un’architettura di dati completa. Se si desidera ottenere una visione panoramica di come un sito è strutturato o raccogliere una serie di risorse correlate, questa funzione rende l’intero processo automatizzato e altamente scalabile.
Personalizzazione e Utilizzo Versatile
Un altro aspetto che rende Firecrawl particolarmente interessante è la sua versatilità. Può essere utilizzato come un’API stand-alone, il che lo rende particolarmente utile per sviluppatori che vogliono integrare la funzionalità di scraping e crawling nei propri progetti. Inoltre, può essere impiegato come framework, supportando linguaggi di programmazione come Node.js e Python. Questa flessibilità consente agli sviluppatori di personalizzare Firecrawl in base alle proprie esigenze specifiche, rendendolo compatibile con una varietà di ambienti di sviluppo.
Una delle caratteristiche più potenti è la possibilità di configurare Firecrawl per lavorare dietro muri di autenticazione. In molti casi, i dati che ci interessano possono essere protetti da login o altre forme di autenticazione, ma Firecrawl è stato progettato per aggirare questi ostacoli, permettendo un accesso continuo e senza interruzioni ai dati, anche in contesti più complessi.
Inoltre, Firecrawl è in grado di gestire anche contenuti multimediali. Questo significa che, oltre ai testi e ai dati strutturati, è possibile estrarre immagini, video e altri tipi di media, che possono essere utili per alimentare modelli di intelligenza artificiale che richiedono anche informazioni visive.
L’API per la Nuova Era dell’Elaborazione Dati
Firecrawl rappresenta una vera e propria rivoluzione nell’ambito dell’estrazione di dati web. Grazie alla sua capacità di centralizzare tutti i passaggi necessari per ottenere dati pronti all’uso per i modelli di linguaggio, offre un enorme vantaggio competitivo a chiunque desideri raccogliere informazioni da internet in modo efficiente e scalabile.
Se, come molti sviluppatori e professionisti nel campo dell’AI, sei stato frustrato dalle limitazioni di altri strumenti di scraping e crawling, Firecrawl merita sicuramente di essere provato. L’API offre una combinazione unica di facilità d’uso, funzionalità avanzate e possibilità di personalizzazione che lo rendono una scelta ideale per progetti che richiedono un’estrazione dati complessa e ottimizzata.
Per esplorare il progetto e iniziare a utilizzarlo, puoi visitare il repository di Firecrawl su GitHub.
In sintesi, Firecrawl è l’API definitiva per chi desidera trasformare qualsiasi sito web in dati utilizzabili da LLM, permettendo di raccogliere, strutturare ed estrarre informazioni da internet con una facilità senza precedenti.
Repository: https://github.com/mendableai/firecrawl
Website: https://www.firecrawl.dev/
Newsletter – Non perderti le ultime novità sul mondo dell’Intelligenza Artificiale: iscriviti alla nostra newsletter gratuita e accedi ai contenuti esclusivi di Rivista.AI direttamente nella tua casella di posta!