Gestire e ottimizzare i modelli linguistici di grandi dimensioni (LLM) è diventato uno dei pilastri fondamentali per il successo di molte applicazioni basate sull’intelligenza artificiale. Tuttavia, la sfida di monitorare prestazioni, costi e comportamenti degli LLM rimane un punto dolente per molte aziende e sviluppatori. Spesso, gli strumenti di osservabilità tradizionali si dimostrano inadeguati, offrendo una visione limitata e rendendo difficile l’identificazione dei problemi o l’ottimizzazione delle prestazioni.
La Sfida dell’Osservabilità nei LLM
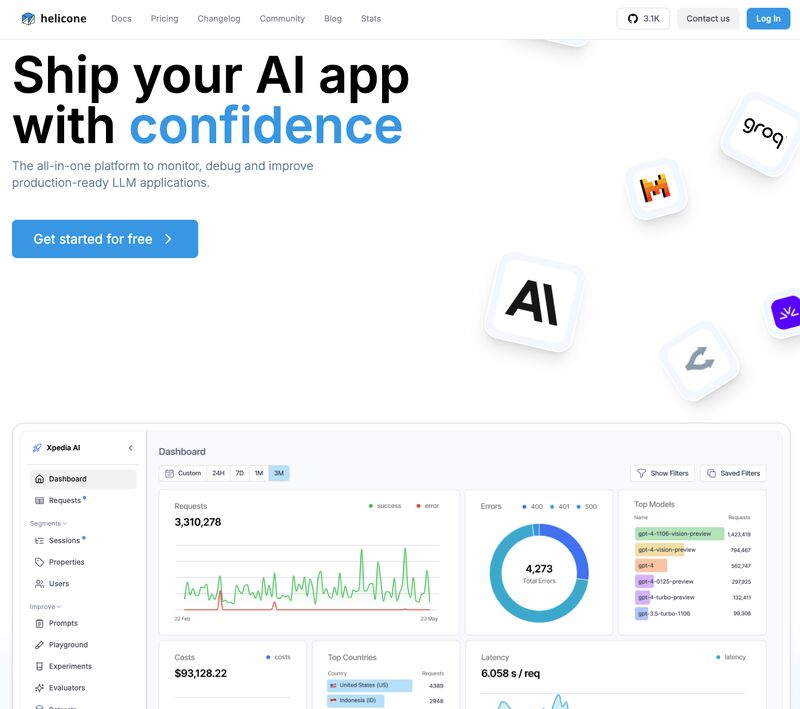
In uno scenario tecnologico in rapida evoluzione, il monitoraggio degli LLM richiede un approccio integrato e avanzato. Non si tratta solo di misurare metriche come latenza o throughput, ma anche di gestire la privacy dei dati e garantire la conformità normativa. Per affrontare questa complessità, è necessario uno strumento che non solo osservi, ma consenta anche di sperimentare, debug e scalare con facilità.
E qui entra in gioco Helicone, una piattaforma open-source progettata per portare l’osservabilità dei LLM a un livello superiore. Con una semplice integrazione a riga singola, Helicone offre la possibilità di monitorare, valutare ed esperimentare con i modelli di AI senza compromettere sicurezza e privacy.
Caratteristiche Rivoluzionarie di Helicone
Helicone si distingue per una serie di funzionalità che affrontano direttamente le lacune degli strumenti esistenti. Tra le principali:
- Gestione dei Prompt: Con la possibilità di versionare e sperimentare prompt utilizzando dati di produzione, Helicone rende semplice iterare sui modelli e ottimizzarne l’output.
- Parametri Configurabili: L’osservabilità non è mai stata così flessibile, consentendo di personalizzare il monitoraggio per adattarsi a specifici casi d’uso.
- Integrazione Dataset: Analizzare i dati utilizzati dai modelli è fondamentale per comprendere e migliorare le performance. Helicone rende questo processo fluido e intuitivo.
- Debug Tracce e Metriche: Con strumenti avanzati per tracciare e debuggare i comportamenti del modello, gli sviluppatori possono individuare anomalie e migliorare l’affidabilità in tempo reale.
- Ottimizzazione dei Costi: Una visione dettagliata dei costi consente alle aziende di ridurre gli sprechi e ottimizzare la spesa per i loro modelli AI.
- Privacy e Sicurezza: In un’era in cui la conformità normativa e la protezione dei dati sono essenziali, Helicone garantisce elevati standard di sicurezza per la gestione delle informazioni sensibili.
Perché Scegliere Helicone?
La risposta è semplice: Helicone combina potenza e semplicità. Grazie alla natura open-source, beneficia di una comunità attiva e di una continua evoluzione, offrendo agli utenti un livello di flessibilità che pochi strumenti proprietari possono eguagliare. La possibilità di integrare Helicone con una singola riga di codice lo rende accessibile sia a team di sviluppo agili che a grandi imprese.
Inoltre, la capacità di scalare insieme ai progetti AI lo rende una soluzione ideale per qualsiasi organizzazione che desideri sfruttare appieno il potenziale dei LLM senza sacrificare controllo, sicurezza o flessibilità.
Conclusione: Un Nuovo Paradigma per l’Osservabilità
Helicone rappresenta più di un semplice strumento: è una piattaforma che risponde a esigenze critiche nel panorama AI di oggi. Semplifica il monitoraggio, consente una migliore gestione dei costi e offre la possibilità di ottimizzare i modelli in modo continuo. Per chiunque lavori con LLM, Helicone potrebbe diventare un alleato insostituibile.
Scopri Helicone e rivoluziona il tuo approccio all’osservabilità dei LLM
Repository: https://github.com/hatchet-dev/hatchet
Website: https://www.helicone.ai/