
Nel vasto panorama dei modelli linguistici di grandi dimensioni (LLM), un’innovazione sorprendente sta riscrivendo le regole del gioco: il Byte Latent Transformer (BLT). Questa nuova architettura abbandona il tradizionale sistema di tokenizzazione per lavorare direttamente con i byte, promettendo un futuro più efficiente e robusto per l’elaborazione del linguaggio naturale.
L’idea di fondo è semplice quanto rivoluzionaria: invece di suddividere il testo in token predefiniti, BLT segmenta il flusso di byte in “patch” di dimensioni variabili. Questi segmenti vengono creati dinamicamente in base all’entropia del byte successivo, un indicatore della complessità dell’informazione. Quando il modello prevede che il prossimo byte sarà difficile da indovinare, alloca più risorse computazionali; quando invece prevede byte prevedibili, usa meno potenza di calcolo.
Questo approccio consente al BLT di superare le limitazioni dei sistemi tradizionali. Nei modelli basati su token, ogni token riceve la stessa quantità di attenzione computazionale, indipendentemente dalla sua complessità. Questo implica uno spreco di risorse su elementi facili da prevedere e una sottostima delle parti più complesse. Con il BLT, invece, la computazione è distribuita in modo intelligente e adattivo.
Dal punto di vista tecnico, il cuore del BLT è costituito da tre componenti principali: un encoder locale leggero che trasforma i byte in rappresentazioni di patch, un potente trasformatore latente che elabora queste patch e un decoder locale che le converte di nuovo in byte. Questo schema consente una gestione fluida delle informazioni senza la necessità di una rappresentazione intermedia fissa.
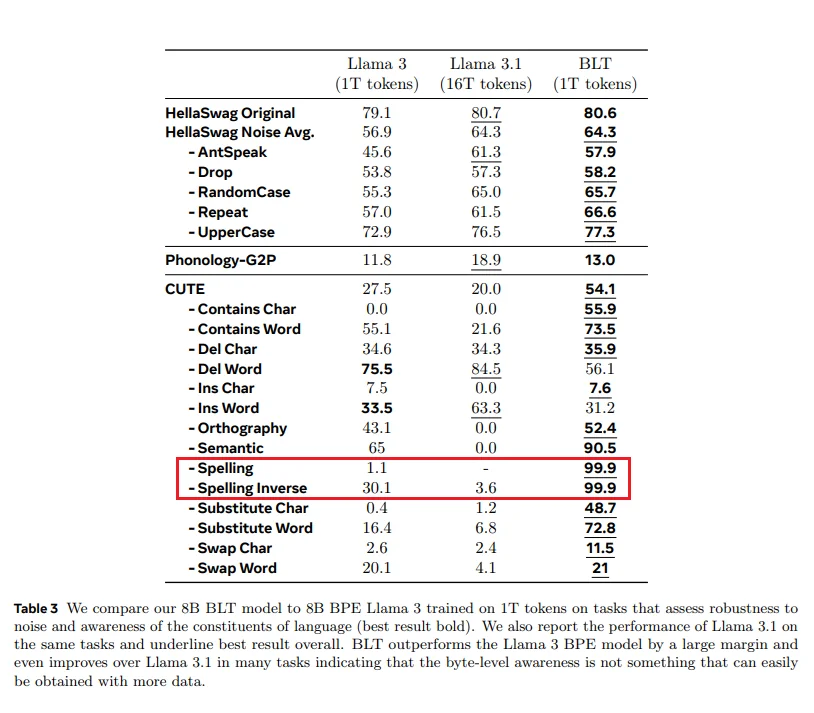
L’assenza di tokenizzazione elimina anche problemi noti come la sensibilità al rumore di input, la mancanza di consapevolezza ortografica e le barriere linguistiche nei sistemi multilingue. I test hanno mostrato che il BLT è significativamente più robusto rispetto ai modelli tradizionali, anche in presenza di dati distorti o rumorosi.
Dal punto di vista delle prestazioni, il BLT non solo eguaglia i modelli basati su token più avanzati, ma li supera in molte applicazioni. I suoi risultati eccellenti in traduzione automatica, comprensione del linguaggio naturale e generazione di codice dimostrano che la modellazione a livello di byte non è solo un’alternativa, ma un nuovo standard verso cui l’intera industria potrebbe convergere.
Il futuro dell’elaborazione del linguaggio sembra più dinamico che mai. Con il Byte Latent Transformer, stiamo assistendo a una vera rivoluzione, una svolta che spinge i confini della tecnologia oltre le convenzioni radicate. In un mondo sempre più guidato dai dati, ogni byte conta davvero.