L’intelligenza artificiale ha raggiunto livelli di sofisticazione senza precedenti, ma i modelli di apprendimento profondo restano in gran parte “scatole nere” dalle dinamiche interne misteriose. La ricerca sull’interpretabilità meccanicistica è il campo su cui si concentrano gli sforzi per decifrare il funzionamento di questi modelli, andando oltre l’incremento della capacità contestuale o la multimodalità. In questo contesto, l’interpretabilità meccanicistica emerge come la più grande sfida e opportunità nella ricerca sull’IA.
Definire l’Interpretabilità Meccanicistica
L’interpretabilità meccanicistica mira a comprendere e descrivere il comportamento interno dei modelli di apprendimento profondo su base rigorosamente analitica. Non si tratta solo di osservare l’output di un modello, ma di decodificare come specifiche architetture neurali, parametri e livelli del modello interagiscano per produrre determinati risultati. Questo approccio analitico non si limita all’osservazione ma cerca di costruire un modello comprensibile, che permetta di prevedere il comportamento della rete su scala significativa e di descriverne la logica operativa in termini umani.
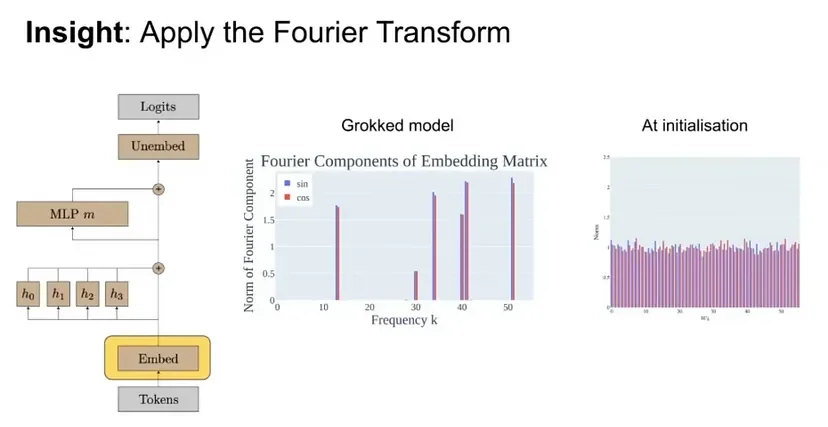
Grokking: Un Comportamento Enigmatico
Uno degli aspetti più affascinanti dell’interpretabilità meccanicistica è la comprensione del fenomeno del “grokking”. Grokking è il termine con cui si descrive la fase in cui un modello, dopo un lungo periodo di addestramento senza apparente miglioramento delle prestazioni, improvvisamente inizia a risolvere un compito in modo eccellente. Questo processo solleva interrogativi su cosa avvenga realmente durante l’addestramento e su quali siano le forze che guidano un modello da un’architettura confusa e caotica a una macchina razionale che esibisce risultati coerenti. Decifrare il grokking potrebbe rivelare strutture logiche profonde e pattern di apprendimento che sono attualmente oscuri, aprendo la strada a modelli più prevedibili e controllabili.
Teste di Induzione: I Rilevatori di Pattern nel Modello
Nel contesto delle reti neurali, le “teste di induzione” sono componenti cruciali per la comprensione della capacità del modello di riconoscere pattern ricorrenti nei dati. Questi moduli sono come piccoli “rilevatori di schema” che identificano correlazioni e strutture all’interno di grandi volumi di dati. Ogni testa di induzione è responsabile dell’analisi di un particolare schema, contribuendo a generare output significativi e complessi basati sull’identificazione e sulla reiterazione di pattern già osservati. Studiare le teste di induzione fornisce intuizioni fondamentali per svelare il processo decisionale dei modelli, offrendo l’opportunità di verificare e migliorare la coerenza della loro logica interna.
Sovrapposizione e Ridondanza nei Modelli di Apprendimento Profondo
Un’altra area di ricerca critica nell’interpretabilità meccanicistica riguarda la sovrapposizione dei percorsi neurali all’interno dei modelli. La ridondanza è spesso considerata uno spreco di risorse computazionali, ma in realtà potrebbe essere una chiave per la robustezza e la flessibilità dei modelli. La ricerca in questo campo mira a comprendere come e perché alcune reti sviluppano più percorsi per risolvere compiti simili, esplorando se la ridondanza possa migliorare la resilienza dei modelli contro l’overfitting o l’instabilità. Questo aspetto è fondamentale per costruire reti più efficienti, che sappiano mantenere la precisione anche in contesti variabili o in condizioni non ideali.
Applicazioni dell’Interpretabilità nel Mondo Reale
L’interpretabilità meccanicistica non è solo un esercizio accademico, ma ha un impatto pratico diretto in numerosi settori, dalla finanza alla sanità, fino alla sicurezza informatica. Essere in grado di comprendere esattamente perché un modello fa una determinata previsione è cruciale per sviluppare sistemi IA sicuri e affidabili. In campo medico, ad esempio, un modello di IA che suggerisce diagnosi deve non solo essere preciso, ma anche interpretabile, per garantire che i professionisti possano validarne l’operato. Nella finanza, la comprensibilità di un modello potrebbe influenzare decisioni critiche, assicurando che le previsioni non siano il risultato di correlazioni spettrali o di pattern casuali.
Decifrare il comportamento interno dei modelli di apprendimento profondo è il fondamento per costruire un’IA realmente affidabile e trasparente.