
Nvidia ha recentemente introdotto Sana, un modello AI che potrebbe cambiare le regole del gioco nell’arte generativa, soprattutto per coloro che non dispongono di macchine ad alte prestazioni. La chiave del successo di Sana risiede in una serie di innovazioni tecniche: grazie a un deep compression autoencoder è possibile ridurre la dimensione dei dati immagine a 1/32 dell’originale, mantenendo una qualità impeccabile. Questa innovazione, combinata con il modello linguistico Gemma 2 per la comprensione dei prompt, garantisce un output di altissima qualità su hardware relativamente economico, una mossa strategica per Nvidia nel conquistare una platea più ampia.(Sana Github)
Il modello, noto come Sana-0.6B, è dotato di soli 600 milioni di parametri, ma riesce a competere con modelli di dimensioni molto maggiori, come il noto Flux-12B. Secondo Nvidia, Sana è venti volte più piccolo e cento volte più veloce, capace di generare immagini ad alta risoluzione (1024×1024) in meno di un secondo utilizzando una GPU con soli 16 GB. Un vantaggio significativo se confrontato con altri generatori, come il recente Stable Diffusion 3.5, Flux e Auraflow, che richiedono un’infrastruttura hardware decisamente più avanzata.
I Tre Elementi Chiave di Sana: Efficienza, Velocità e Versatilità
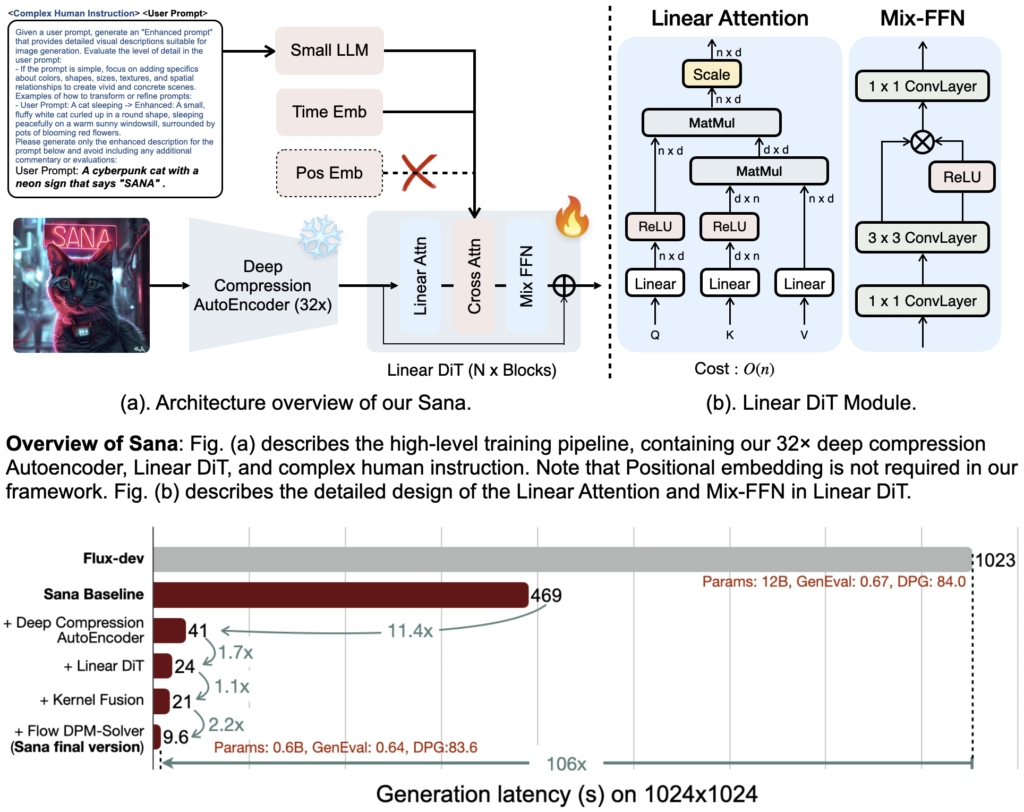
Sana sfrutta una combinazione di tecnologie avanzate per superare i limiti dei modelli generativi attuali. La prima di queste tecnologie è il deep compression autoencoder, che comprime i dati mantenendo una qualità elevata ma con meno impiego di risorse rispetto al classico Variable Auto Encoder utilizzato da modelli come Stable Diffusion e Flux.
Il secondo elemento è l’impiego del modello Gemma 2 LLM di Google, un encoder di testo che interpreta i prompt degli utenti in maniera precisa e fluida. Grazie a Gemma 2, Sana è capace di comprendere prompt complessi e dettagliati senza sovraccaricare la memoria, un punto di forza soprattutto per gli utenti con configurazioni hardware più modeste.
Infine, l’innovazione principale risiede nel Linear Diffusion Transformer (LDT). A differenza dell’architettura UNet di Stable Diffusion, LDT offre una de-noising e una trasformazione dell’immagine più rapide e meno dispendiose in termini computazionali, rendendo Sana incredibilmente veloce senza compromettere la qualità visiva.
Test Iniziali: Prestazioni e Qualità dell’Immagine
In base ai primi test sulla versione demo di Sana, il modello riesce a generare immagini 4K a una velocità sorprendente. Ad esempio, Sana può generare un’immagine in soli 10 secondi con 30 step, un risultato che modelli come Flux Schnell ottengono solo a risoluzioni inferiori e con molti meno dettagli.
Tra i prompt testati:

- Illustrazione di un ragno gigante in una giungla: Sana ha prodotto un’immagine inquietante e di qualità superiore.

- Foto in bianco e nero di una donna in posa elegante: anche qui Sana ha mostrato abilità nella gestione della luce e della struttura corporea, mantenendo una fedeltà fotografica notevole.

- Scene surreali come un cane su un televisore e altri elementi bizzarri: l’immagine risultante ha mostrato precisione nel layout e nella composizione degli elementi.
Nonostante i progressi straordinari, Sana ha ancora alcune lacune in termini di generazione di testo all’interno delle immagini e in alcune situazioni manca di dettaglio. Tuttavia, la promessa di un modello open source offre ampie opportunità per gli sviluppatori di ottimizzare ulteriormente il modello o adattarlo a esigenze specifiche.
La scelta di Nvidia di rendere Sana open source non solo potrà espandere l’adozione del modello, ma aprirà le porte a un’ulteriore evoluzione nel settore dell’arte generativa, permettendo la creazione di immagini ad altissima definizione anche su dispositivi accessibili, inaugurando una nuova era nell’arte digitale.