
Il modello di intelligenza artificiale di Google Research, Tx-LLM annunciato il 9 Ottobre, sta rivoluzionando lo sviluppo dei farmaci.
Il processo di sviluppo di nuovi farmaci terapeutici è notoriamente lungo e costoso: richiede in media 10-15 anni e un investimento di 1-2 miliardi di dollari per ogni candidato, con un tasso di fallimento clinico molto elevato. Ciò è dovuto alla complessità della pipeline, che comporta numerosi passaggi e criteri indipendenti che i farmaci devono soddisfare.
Ad esempio, un farmaco deve interagire specificamente con il target designato senza provocare tossicità, deve raggiungere la sua destinazione all’interno del corpo e deve essere facilmente prodotto su larga scala.
Il processo sperimentale per validare queste proprietà è estremamente dispendioso in termini di tempo e costi. In questo contesto, Tx-LLM, un modello linguistico di grandi dimensioni ottimizzato per prevedere le proprietà delle entità biologiche, emerge come una soluzione innovativa e vantaggiosa per l’industria farmaceutica.
Tx-LLM: Un Modello Linguistico di Rilievo per il Settore Farmaceutico
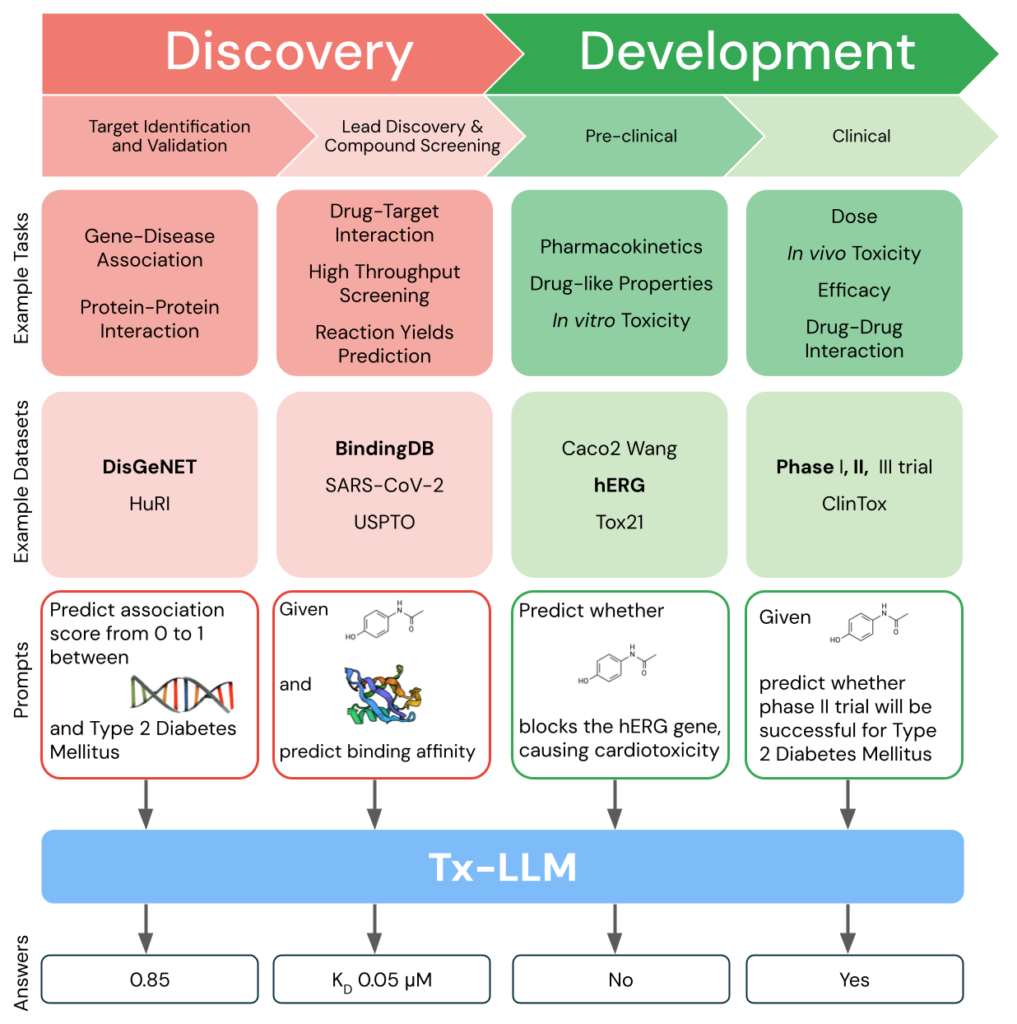
Tx-LLM è stato progettato specificamente per supportare lo sviluppo terapeutico, coprendo tutto il percorso dal riconoscimento del target biologico alla sperimentazione clinica. Addestrato su 66 set di dati relativi alla scoperta di farmaci, questo modello sfrutta l’intelligenza artificiale per prevedere le proprietà di molecole, proteine, linee cellulari e malattie con una precisione notevole. Con un solo set di pesi, Tx-LLM ha dimostrato di raggiungere prestazioni competitive rispetto ai migliori modelli specialistici in 43 delle 66 attività considerate, superandoli in 22 casi. Questo livello di accuratezza offre alle aziende farmaceutiche un potente strumento per identificare e sviluppare candidati terapeutici in modo più rapido ed efficiente rispetto ai metodi tradizionali.

Accelerazione dello Sviluppo Farmaceutico: Riduzione dei Tempi e dei Costi
L’impatto diretto di Tx-LLM sulle aziende farmaceutiche si riflette nell’accelerazione del processo di sviluppo dei farmaci. Grazie alla capacità di prevedere con alta precisione l’efficacia, la sicurezza e la tossicità di una molecola prima della fase sperimentale, Tx-LLM può ridurre significativamente il numero di candidati fallimentari nelle fasi precliniche e cliniche. Ciò si traduce in un risparmio di tempo e risorse, consentendo di focalizzare gli sforzi solo su molecole promettenti. In un settore dove ogni ritardo o fallimento può costare milioni di dollari, l’adozione di un modello predittivo come Tx-LLM rappresenta un vantaggio competitivo senza precedenti.
Versatilità e Adattamento a Diversi Contesti Terapeutici
Un ulteriore punto di forza di Tx-LLM risiede nella sua capacità di trasferire informazioni tra diverse aree terapeutiche. Il modello non solo eccelle nella previsione delle proprietà di piccole molecole, ma è in grado di combinare informazioni testuali e molecolari per fare previsioni ancora più accurate. Questo consente alle aziende di applicare il modello a diverse classi di terapie e condizioni, aumentando la flessibilità e riducendo la necessità di sviluppare modelli separati per ciascun tipo di farmaco.
Un Futuro Promettente per le Aziende Farmaceutiche
Con l’implementazione di Tx-LLM, le aziende farmaceutiche possono non solo ridurre i tempi di sviluppo e i costi complessivi, ma anche migliorare l’efficienza e l’affidabilità dei loro processi decisionali. Grazie alla capacità di Tx-LLM di analizzare e prevedere le proprietà dei farmaci lungo tutto il ciclo di vita terapeutico, dall’identificazione del target fino all’approvazione clinica, le aziende avranno la possibilità di sviluppare farmaci più sicuri e più velocemente. Questo modello rappresenta una svolta epocale per l’industria, aprendo le porte a una nuova era di innovazione e sviluppo nel campo delle terapie farmacologiche.
Se le aziende farmaceutiche intendono restare competitive in un mercato in continua evoluzione, l’integrazione di modelli come Tx-LLM diventa una scelta strategica fondamentale per il loro successo futuro.
Tx-LLM e AlphaFold sono entrambi modelli di machine learning avanzati progettati per risolvere problematiche complesse nel campo della biologia, ma differiscono significativamente per scopo, ambito di applicazione e approccio tecnico. Mentre AlphaFold è noto per il suo contributo fondamentale nella previsione della struttura tridimensionale delle proteine, Tx-LLM mira a supportare lo sviluppo di terapie farmacologiche in modo olistico, prevedendo varie proprietà biologiche e cliniche di molecole e altri componenti terapeutici lungo l’intera pipeline di sviluppo.
Differenze principali tra Tx-LLM e AlphaFold
Obiettivo
- AlphaFold: L’obiettivo principale di AlphaFold è prevedere la struttura 3D delle proteine partendo dalla sequenza amminoacidica. Questa capacità di predizione delle strutture proteiche risolve una delle sfide più difficili della biologia computazionale, con applicazioni nel design di farmaci, nella biologia strutturale e nella comprensione di malattie.
- Tx-LLM: Il fine di Tx-LLM è molto più ampio. È progettato per prevedere una gamma di proprietà rilevanti per lo sviluppo terapeutico, come l’efficacia di farmaci, la tossicità, la biodisponibilità e il successo nei trial clinici. Tx-LLM è stato perfezionato per affrontare task specifici del processo di sviluppo dei farmaci, che vanno dall’identificazione dei target terapeutici alla previsione degli esiti nei trial clinici.
Tipologia di input
- AlphaFold: Il modello si concentra specificamente su sequenze di amminoacidi di proteine. Quindi, il suo input è costituito da stringhe di amminoacidi, e il suo output è la struttura 3D della proteina.
- Tx-LLM: Il modello utilizza una varietà di input, inclusi molecole piccole, proteine, acidi nucleici, linee cellulari e nomi di malattie. Inoltre, incorpora informazioni testuali come la letteratura biomedica e i contesti clinici. Questa flessibilità consente a Tx-LLM di affrontare task molto diversi, che spaziano dal design molecolare alla valutazione dei risultati clinici.
Ambito di applicazione
- AlphaFold: Si concentra quasi esclusivamente sulle proteine, cercando di risolvere un problema strutturale chiave, che è la previsione della loro conformazione tridimensionale. Sebbene questa capacità sia cruciale per numerosi settori, AlphaFold non è direttamente applicabile a tutte le fasi del processo di sviluppo terapeutico.
- Tx-LLM: Il modello è stato sviluppato per coprire l’intera pipeline dello sviluppo di farmaci. Viene utilizzato per task come la classificazione della tossicità dei farmaci, la previsione della loro affinità di legame e la generazione di molecole chimiche. In altre parole, Tx-LLM non è confinato a un solo tipo di entità biologica (come le proteine) ma abbraccia molteplici componenti del processo terapeutico.
Tecnologia sottostante
- AlphaFold: Utilizza un modello di deep learning altamente specializzato, che sfrutta la fisica delle interazioni proteiche e l’attenzione a livello sequenziale per generare modelli tridimensionali di proteine con un livello di precisione senza precedenti. È stato addestrato principalmente su database di strutture proteiche noti.
- Tx-LLM: Si basa su un modello di linguaggio naturale fine-tuned (PaLM-2) e si avvale del Therapeutics Instruction Tuning (TxT), un insieme di dati strutturati con compiti specifici di drug discovery. Tx-LLM incorpora anche una componente testuale, il che significa che può utilizzare informazioni derivate dalla letteratura scientifica, ampliando la sua capacità di applicazione e generalizzazione.
Tipi di predizione
- AlphaFold: Predice esclusivamente la struttura tridimensionale delle proteine, che è fondamentale per comprendere la funzione biologica delle proteine e il loro potenziale come bersagli terapeutici.
- Tx-LLM: Può prevedere diverse proprietà delle entità biologiche e chimiche coinvolte nello sviluppo di terapie, inclusa la tossicità, la probabilità di successo di un farmaco nei trial clinici e altre metriche importanti. Alcuni task che il modello affronta sono di tipo classificativo (ad esempio, se un farmaco è tossico o no), altri di tipo regressivo (predizione dell’affinità di legame), e altri ancora sono generativi (creazione di molecole chimiche).
Risultati e performance
- AlphaFold: È riconosciuto a livello mondiale per la sua accuratezza senza precedenti nel predire strutture proteiche. Ha superato i migliori modelli precedenti ed è stato salutato come una svolta nella biologia computazionale.
- Tx-LLM: Ha raggiunto performance competitive o superiori rispetto ai modelli specialistici in 43 dei 66 task su cui è stato testato, eccellendo in particolare nei task che combinano piccole molecole e informazioni testuali, come la predizione del successo dei farmaci nei trial clinici. Tuttavia, in alcune aree, i modelli specialistici rimangono superiori.
AlphaFold rappresenta una rivoluzione nella previsione delle strutture proteiche, un contributo essenziale per la biologia strutturale e lo sviluppo dei farmaci che richiedono una profonda comprensione delle interazioni proteiche. Tx-LLM, d’altra parte, offre un approccio olistico alla scoperta e allo sviluppo di farmaci, predicendo una vasta gamma di proprietà terapeutiche e biochimiche. Mentre AlphaFold si concentra su un problema altamente specifico, Tx-LLM tenta di affrontare l’intera complessità della pipeline terapeutica, dalla scoperta dei target alla valutazione clinica finale, usando un modello basato su dati testuali e numerici.
In sintesi, AlphaFold è specializzato nella risoluzione della struttura proteica, mentre Tx-LLM offre una piattaforma più generalista per la previsione di proprietà terapeutiche, combinando informazioni molecolari e testuali per accelerare il processo di sviluppo farmaceutico.