Il crescente consumo energetico dei modelli di intelligenza artificiale (AI) è diventato una preoccupazione globale. Un recente studio condotto dai ricercatori di BitEnergy AI, Inc. ha introdotto una nuova tecnica denominata Linear-Complexity Multiplication (L-Mul), che potrebbe ridurre il consumo energetico fino al 95% senza compromettere la qualità delle prestazioni dei modelli AI. L-Mul sostituisce le costose moltiplicazioni in virgola mobile con più semplici operazioni di somma di interi, mantenendo una precisione elevata e riducendo drasticamente i costi computazionali. Questo articolo esplora il funzionamento della tecnica, i suoi risultati e le potenziali implicazioni per il futuro dei modelli AI.
L’intelligenza artificiale è diventata un elemento chiave nello sviluppo tecnologico moderno, con applicazioni che vanno dalla visione artificiale al processamento del linguaggio naturale. Tuttavia, questi avanzamenti sono accompagnati da un crescente consumo energetico. ChatGPT, uno dei modelli di AI più diffusi, consuma giornalmente 564 MWh, equivalenti all’energia necessaria per alimentare 18.000 abitazioni negli Stati Uniti. Entro il 2027, si stima che l’industria AI possa richiedere tra gli 85 e i 134 TWh all’anno, un consumo simile a quello delle operazioni di mining di Bitcoin.
In questo contesto, BitEnergy AI, Inc. ha proposto una nuova soluzione, L-Mul, che promette di ridurre drasticamente i costi energetici dei modelli AI, mantenendo al contempo un’alta qualità di calcolo.
Moltiplicazioni in Virgola Mobile e il Problema Energetico
I modelli di AI si basano ampiamente sulle operazioni in virgola mobile (floating-point), una rappresentazione matematica che consente di gestire numeri molto grandi o molto piccoli in modo efficiente. Questa tecnica è simile alla notazione scientifica, ma applicata in forma binaria. Le moltiplicazioni in virgola mobile, sebbene essenziali per la precisione dei modelli AI, richiedono una grande quantità di energia computazionale.
Nel tentativo di ridurre questo impatto energetico, i ricercatori hanno adottato strategie come la riduzione della precisione, passando da formati a 32-bit (fp32) a formati con precisione inferiore come fp16, fp8 e persino fp4. Tuttavia, la riduzione della precisione può comportare una diminuzione della qualità dei risultati, rendendo complesso bilanciare efficienza energetica e accuratezza.
Linear-Complexity Multiplication (L-Mul): Un Approccio Innovativo
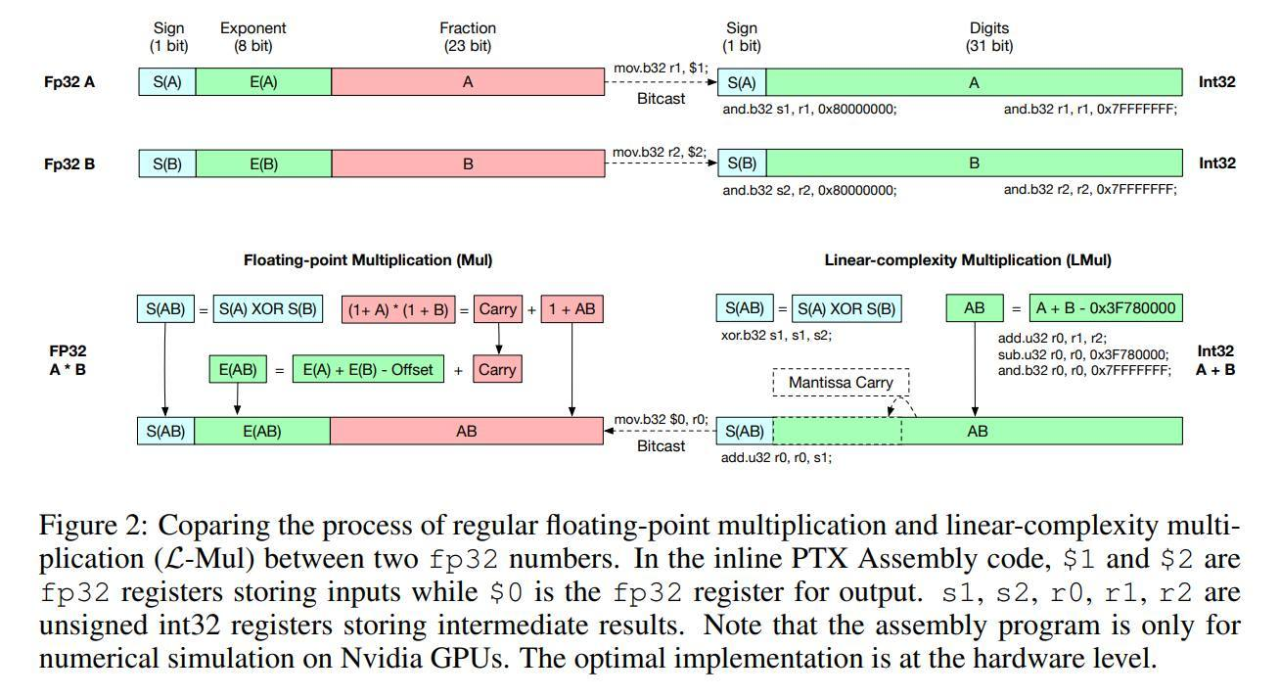
L-Mul affronta direttamente il problema dell’alto consumo energetico dei modelli AI, ridisegnando il modo in cui i modelli gestiscono i calcoli. Invece di utilizzare complesse moltiplicazioni in virgola mobile, L-Mul approssima queste operazioni attraverso somma di interi. Ad esempio, invece di moltiplicare 123,45 per 67,89, L-Mul scompone il calcolo in operazioni più semplici e veloci di somma.
Secondo i ricercatori, applicare L-Mul all’hardware di processamento dei tensori può ridurre il consumo energetico del 95% per le operazioni di moltiplicazione elementare e dell’80% per i prodotti scalari. Queste riduzioni potrebbero significare un risparmio energetico significativo per i modelli di AI che utilizzano questa tecnica.
Prestazioni e Impatti
I risultati preliminari indicano che L-Mul non solo riduce il consumo energetico, ma riesce anche a mantenere un’alta precisione nelle operazioni. In alcune situazioni, L-Mul ha superato gli standard attuali a 8-bit, raggiungendo una precisione superiore con un minore utilizzo di risorse computazionali. Test condotti su compiti di processamento del linguaggio naturale, visione artificiale e ragionamento simbolico hanno evidenziato una riduzione media delle prestazioni dello 0,07%, una diminuzione trascurabile a fronte dei risparmi energetici ottenuti.
I modelli basati su trasformatori (Transformer), che costituiscono la spina dorsale dei grandi modelli di linguaggio come GPT, potrebbero trarre grandi benefici dall’integrazione di L-Mul. L’algoritmo si integra perfettamente nel meccanismo di attenzione, una delle componenti più dispendiose dal punto di vista computazionale in questi modelli. I test condotti su modelli noti, come Llama, Mistral e Gemma, hanno persino rilevato un leggero aumento di precisione in alcuni compiti visivi.
Limiti Tecnici e Prospettive Future
Nonostante i risultati promettenti, L-Mul presenta una limitazione fondamentale: richiede hardware specializzato per poter essere sfruttato appieno. L’attuale generazione di hardware non è ottimizzata per supportare nativamente i calcoli di L-Mul, limitando quindi l’impatto immediato della tecnologia.
I ricercatori di BitEnergy AI hanno già pianificato lo sviluppo di hardware specializzato che supporti nativamente le operazioni di L-Mul. Questo progetto prevede la creazione di kernel algoritmici L-Mul e L-Matmul a livello hardware, insieme a API di programmazione che faciliteranno l’integrazione della tecnologia nei modelli AI. Questa innovazione potrebbe aprire la strada a una nuova generazione di modelli di intelligenza artificiale veloci, accurati e altamente efficienti dal punto di vista energetico.
Conclusioni
L-Mul rappresenta una svolta significativa nel tentativo di ridurre l’impronta energetica dei modelli di intelligenza artificiale. Con un potenziale risparmio energetico fino al 95%, senza compromettere la qualità delle prestazioni, questa tecnologia potrebbe contribuire a rendere l’AI più sostenibile dal punto di vista ambientale ed economico.
Tuttavia, il pieno sfruttamento di L-Mul richiede lo sviluppo di hardware dedicato, una sfida che potrebbe rallentare l’adozione immediata della tecnologia. Con lo sviluppo di nuove infrastrutture hardware, potremmo assistere a un’evoluzione significativa nell’efficienza energetica dei modelli di intelligenza artificiale, aprendo nuove opportunità per applicazioni scalabili e accessibili a costi ridotti.
Il futuro dell’AI potrebbe essere più verde e sostenibile grazie a tecnologie come L-Mul, offrendo benefici tangibili non solo in termini di prestazioni, ma anche di impatto ambientale.