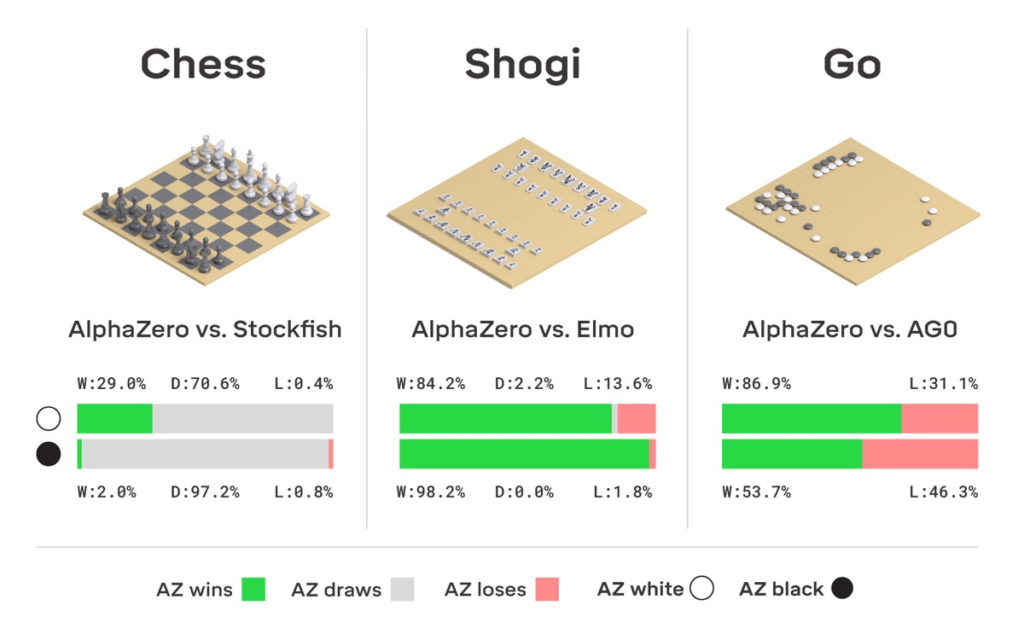
La nuova intelligenza artificiale di DeepMind è la degna erede del primo programma ad aver battuto un essere umano a Go. Partendo da un gioco casuale e conoscendo solo le regole del gioco, AlphaZero ha sconfitto un campione del mondo nei giochi di Go, scacchi e shogi (scacchi giapponesi).
Un articolo che illustra i risultati è stato pubblicato su Science. “Partendo da un gioco completamente casuale, AlphaZero impara progressivamente a riconoscere un buon gioco e sviluppa le proprie valutazioni”, ha dichiarato Demis Hassabis, CEO e co-fondatore di DeepMind. “In questo modo, è libero dai vincoli del pensiero umano sul gioco”.
Gli scacchi sono da tempo una piattaforma ideale per testare e sviluppare l’intelligenza artificiale nei computer. Il primo programma di scacchi per computer fu creato negli anni ’50 presso il Los Alamos National Laboratory. Alla fine degli anni ’60, il programma Mac Hack IV di Richard D. Greenblatt fu il primo a partecipare a un torneo di scacchi umano e a vincere contro un avversario umano. Da allora, molti altri programmi di scacchi per computer sono stati sviluppati, ognuno più avanzato del precedente, fino a quando computer Deep Blue di IBM sconfisse sconfisse il grande maestro Garry Kasparov nel maggio 1997.
La quantità di potenza di calcolo necessaria per addestrare i più grandi modelli di intelligenza artificiale sta raddoppiando ogni 3-4 mesi dal 2012. Questo rappresenta un aumento di oltre 7 volte rispetto al tasso storico di raddoppio di 2 anni, in base alla Legge di Moore, dal 1959 al 2012.
Sette il numero ricorrente
Da AlexNet ad AlphaGo Zero. Su una scala lineare, l’utilizzo del calcolo è aumentato di 300.000 volte negli ultimi (7) sette anni.
La traiettoria attuale suggerisce un futuro in cui il settore tecnologico dovrà bilanciare con attenzione l’innovazione e la sostenibilità economica, con potenziali ricadute sia sui prezzi dei servizi AI sia sulla struttura competitiva del mercato.
Le aziende che sapranno adattarsi a queste dinamiche attraverso investimenti strategici in efficienza energetica e infrastrutture avranno maggiori probabilità di emergere come leader in un panorama sempre più complesso e competitivo.
In (7) sette decenni, l’intelligenza artificiale ha fatto grandi progressi. Tutti i sistemi di AI basati sul ML necessitano di addestramento.
Per i primi 6 decenni, la capacità di calcolo per l’addestramento è cresciuta seguendo la legge di Moore, raddoppiando circa ogni 20 mesi. Dal 2010, questa crescita è diventata ancora più rapida, con un tempo di raddoppio di circa 6 mesi.
La visualizzazione mostra che con l’aumento del calcolo dell’addestramento, i sistemi di intelligenza artificiale sono diventati più potenti.
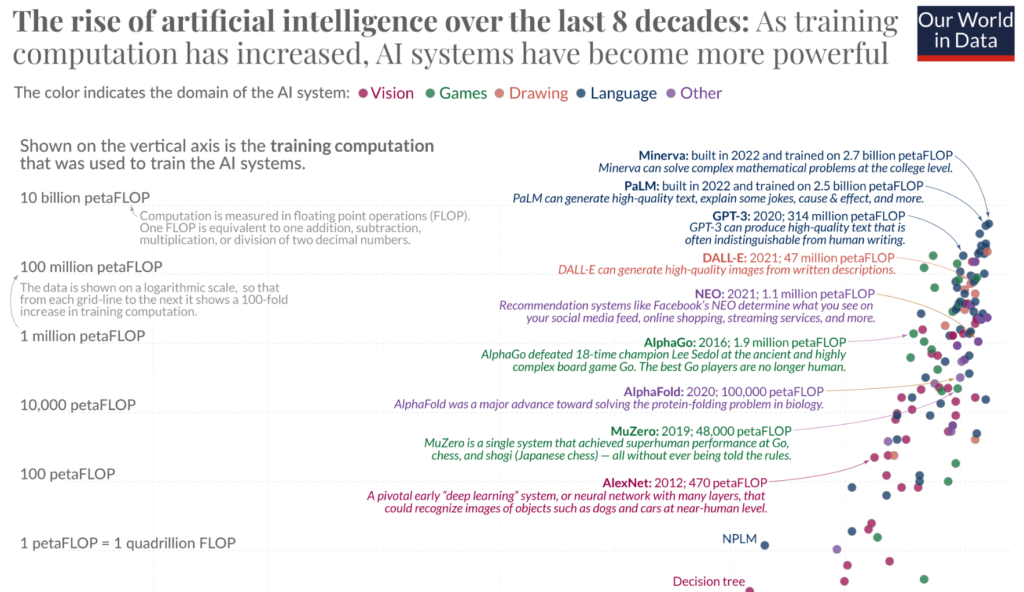
Il calcolo dell’addestramento è uno dei tre fattori principali che influenzano le capacità del sistema, insieme agli algoritmi e ai dati di input.
Studio di OpenAI :
La quantità totale di elaborazione, in petaflop/s-giorni,
utilizzato per addestrare risultati selezionati relativamente noti, che hanno richiesto un notevole sforzo di calcolo per il tempo impiegato e hanno fornito informazioni sufficienti per stimare l’entità del calcolo utilizzato.
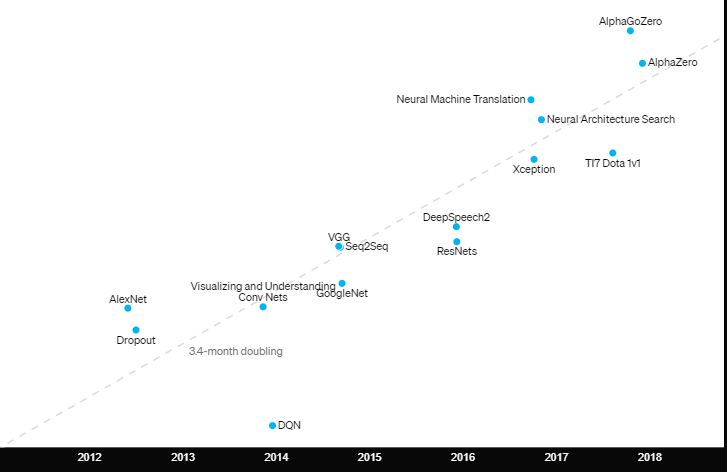
Osservando il grafico possiamo vedere approssimativamente quattro ere distinte:
- Prima del 2012: era raro utilizzare le GPU per l’apprendimento automatico, il che rendeva difficile ottenere i risultati mostrati nel grafico.
- Dal 2012 al 2014: l’infrastruttura per l’addestramento su numerose GPU era poco comune, quindi la maggior parte dei risultati utilizzava 1-8 GPU con una potenza nominale di 1-2 TFLOPS per un totale di 0,001-0,1 pfs-giorni.
- Dal 2014 al 2016: i risultati su larga scala hanno utilizzato 10-100 GPU con una potenza nominale di 5-10 TFLOPS, con conseguenti 0,1-10 pfs-giorni. I rendimenti decrescenti sul parallelismo dei dati hanno comportato che le esecuzioni di training più grandi avessero un valore limitato.
- 2016-2017: approcci che consentono un maggiore parallelismo algoritmico, come grandi dimensioni dei batch(si apre in una nuova finestra), ricerca architettura(si apre in una nuova finestra)e iterazione esperta(si apre in una nuova finestra), insieme ad hardware specializzato come TPU e interconnessioni più veloci, hanno notevolmente aumentato questi limiti, almeno per alcune applicazioni.
AlphaGoZero/AlphaZero è l’esempio pubblico più visibile di parallelismo algoritmico massiccio, ma molte altre applicazioni su questa scala sono ora possibili a livello algoritmico e già essere in atto in un contesto di produzione.
I dati del grafico seguente provengono da test che misurano le prestazioni umane e dell’intelligenza artificiale in cinque aree, dal riconoscimento della scrittura alla comprensione del linguaggio. In ogni area, le prestazioni iniziali dell’intelligenza artificiale sono impostate su -100 e quelle umane su zero come riferimento. Quando il modello supera la linea zero, significa che l’AI ha ottenuto più punti degli umani nello stesso test.
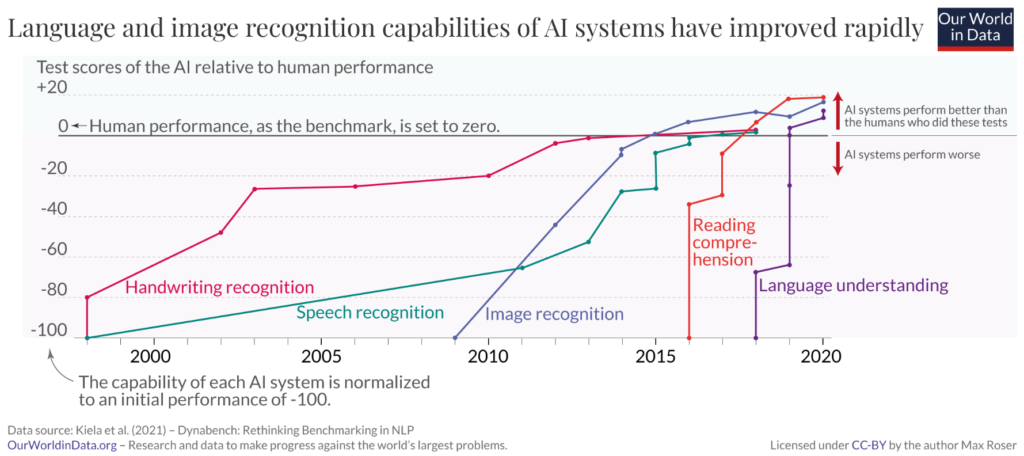
Attenzione, l’IA non ha superato gli umani, né che ci troviamo davanti a sistemi di apprendimento automatico senzienti.
Questo drammatico aumento delle risorse computazionali richieste sottolinea quanto sia diventato economicamente impegnativo raggiungere progressi significativi nel campo dell’IA.
Entro il 2025, in assenza di innovazioni profonde, il consumo di energia dei data center potrebbe rappresentare fino al 10% dell’utilizzo mondiale di elettricità. Lo sviluppo di un sistema di intelligenza artificiale inquina 5 volte di più di un’automobile durante tutta la sua vita.
Aziende come Intel e AMD stanno accelerando nello sviluppo di chip specifici (Radeon Instinct) per l’intelligenza artificiale per soddisfare la crescente domanda di potenza di calcolo.
Il 9 aprile 2024, Intel ha presentato il suo ultimo chip AI, il Gaudi 3, che vanta prestazioni superiori a quelle di Nvidia H100 GPU, Un’efficienza energetica più che doppia e un’elaborazione dei modelli AI 1,5 volte più veloce.
Nvidia si concentra sullo sviluppo di GPU ottimizzate per AI, come le GPU A100 e H100 Tensor Core. La recente acquisizione di Arm Holdings punta a rafforzare il controllo sulle architetture dei chip che alimentano molti dispositivi mobili.
L’intelligenza artificiale stessa può contribuire a migliorare l’efficienza energetica delle infrastrutture che la supportano, ad esempio attraverso previsioni più accurate della produzione di energia eolica. Nuove tecnologie come la fotonica potrebbero aiutare ad alimentare in modo più efficiente le reti neurali in futuro.
Proiezioni sul Consumo Energetico
Il rapido aumento della potenza computazionale sta determinando una crescita altrettanto vertiginosa della domanda energetica. Si prevede che entro i prossimi tre anni, il consumo energetico dei data center potrebbe aumentare di oltre il 300%, una cifra che pone seri interrogativi sulla sostenibilità ambientale e sui costi operativi. Attualmente, i data center rappresentano circa l’1% del consumo energetico globale, ma questo dato è destinato a salire significativamente se la crescita continuerà al ritmo attuale.
Per le aziende, questo significa dover affrontare costi energetici in forte aumento. Secondo stime preliminari, il costo dell’energia per l’addestramento di modelli avanzati di AI potrebbe triplicare nei prossimi cinque anni, erodendo i margini di profitto e costringendo le imprese a investire in soluzioni energetiche più efficienti o a rivedere le loro strategie operative.
Proiezioni sugli Investimenti in Data Center
Parallelamente, gli investimenti in infrastrutture di data center sono destinati a subire un’impennata. Si stima che il mercato globale dei data center, che valeva circa 59 miliardi di dollari nel 2021, possa superare i 150 miliardi di dollari entro il 2027, con una crescita media annua del 15%. Questo aumento sarà principalmente alimentato dalla necessità di aggiornare e ampliare le infrastrutture esistenti per supportare la crescente domanda di potenza di calcolo.
Le aziende dovranno allocare capitali significativi per implementare tecnologie di raffreddamento avanzate e per migliorare l’efficienza energetica, riducendo al contempo le emissioni di carbonio. Inoltre, l’adozione di tecnologie emergenti come il quantum computing potrebbe accelerare ulteriormente questi investimenti, introducendo nuove sfide e opportunità.
Il Paradosso Accuratezza-Energia riguarda il compromesso tra l’accuratezza di un modello di machine learning e l’energia necessaria per raggiungere tale accuratezza.
Aumentare l’accuratezza di un modello richiede spesso architetture più complesse, più strati e maggiori dati di addestramento, il che porta a un significativo incremento del consumo energetico.
Questo paradosso si manifesta nel fatto che, mentre un’elevata accuratezza richiede modelli ad alto costo energetico, l’efficienza energetica spesso comporta una riduzione dell’accuratezza.
Tale compromesso è particolarmente rilevante per applicazioni pratiche come l’edge computing, dove il budget energetico è limitato.
La crescente richiesta di modelli altamente accurati solleva preoccupazioni ambientali legate all’impatto energetico dei centri dati, spingendo la ricerca verso lo sviluppo di algoritmi più efficienti e hardware specializzati che possano ridurre il consumo energetico senza compromettere significativamente le prestazioni.
La rapida crescita della potenza di calcolo necessaria per addestrare modelli di intelligenza artificiale (AI) è stata osservata e documentata in diverse analisi e studi. Ecco alcune fonti e studi scientifici che evidenziano questo fenomeno, Riferimenti:
- “AI and Compute” – OpenAI (2018):
- Fonte: OpenAI Blog
- Descrizione: Uno studio di OpenAI ha evidenziato che la quantità di calcolo usata per addestrare i modelli di AI è cresciuta esponenzialmente, raddoppiando ogni 3,4 mesi dal 2012 al 2018. Questo fenomeno è stato soprannominato la “legge di Moore per l’AI”, indicando una crescita molto più rapida rispetto alla tradizionale legge di Moore che riguarda i transistor nei microprocessori.
- Link: AI and Compute
- “Scaling Laws for Neural Language Models” – OpenAI (2020):
- Fonte: Pubblicazione su arXiv
- Descrizione: Questo studio di OpenAI discute le leggi di scalabilità per i modelli di linguaggio neurale, mostrando come l’aumento della capacità di calcolo migliora le prestazioni dei modelli. Anche se non si concentra esclusivamente sulla crescita della potenza di calcolo, fornisce un contesto sul motivo per cui le richieste di calcolo stanno crescendo così rapidamente.
- Link: Scaling Laws for Neural Language Models
- “The Computational Limits of Deep Learning” – MIT (2020):
- Fonte: MIT Technology Review
- Descrizione: Questo studio evidenzia come i costi di calcolo per l’addestramento dei modelli AI stiano crescendo esponenzialmente, rendendo necessaria una riflessione sui limiti fisici e finanziari dell’attuale tendenza. La ricerca sottolinea l’importanza di trovare soluzioni più efficienti per mantenere la sostenibilità di tali sviluppi.
- Link: The Computational Limits of Deep Learning
- “On the Opportunities and Risks of Foundation Models” – Stanford University (2021):
- Fonte: Stanford University
- Descrizione: Il report analizza l’evoluzione dei modelli di AI di grandi dimensioni, come GPT-3, e discute le implicazioni dell’enorme crescita della potenza computazionale necessaria per addestrarli. Anche in questo caso, il tema della sostenibilità energetica e degli investimenti è centrale.
- Link: On the Opportunities and Risks of Foundation Models
Questi studi scientifici forniscono una base solida per comprendere l’aumento esponenziale della potenza di calcolo necessaria per l’addestramento dei modelli di AI e le conseguenti implicazioni economiche e ambientali.
Newsletter – Non perderti le ultime novità sul mondo dell’Intelligenza Artificiale. Iscriviti alla newsletter di Rivista.AI e accedi a un mondo di contenuti esclusivi direttamente nella tua casella di posta!