
NVIDIA ha recentemente lanciato un nuovo modello di linguaggio di piccole dimensioni chiamato Mistral-NeMo-Minitron 8B, che offre un’accuratezza all’avanguardia pur essendo compatto abbastanza da funzionare su postazioni di lavoro con schede NVIDIA RTX di fascia consumer.
Questo modello è una versione distillata del più grande modello Mistral NeMo 12B, riducendone i parametri da 12 miliardi a 8 miliardi attraverso una combinazione di tecniche di potatura e distillazione. Ciò gli consente di mantenere un’accuratezza paragonabile a un costo computazionale inferiore, rendendolo adatto a varie applicazioni, tra cui chatbot, assistenti virtuali e generazione di contenuti.
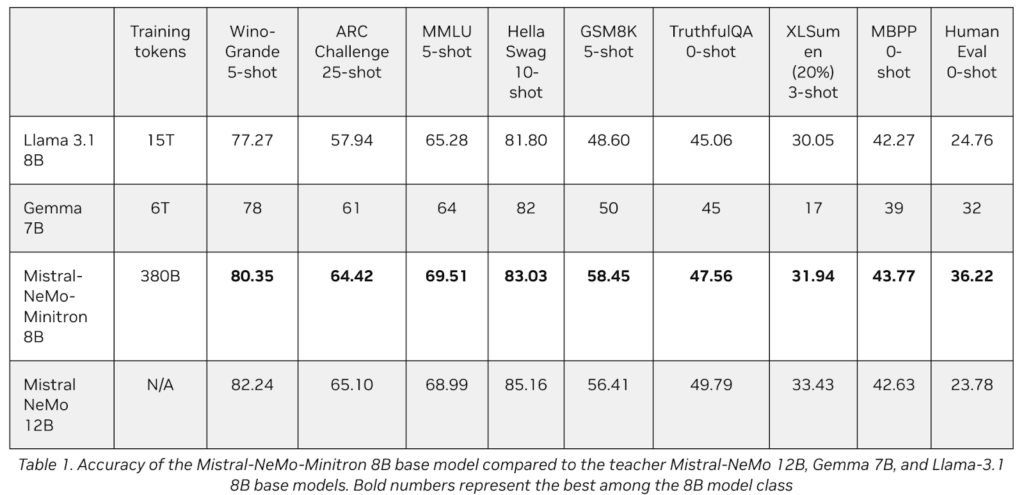
Caratteristiche chiave di Mistral-NeMo-Minitron 8B
- Prestazioni: Il modello eccelle in nove benchmark popolari, dimostrando forti capacità nella comprensione del linguaggio, nel ragionamento, nel riassunto e nei compiti di codifica. Il suo design consente un funzionamento in tempo reale su hardware meno potente, il che è vantaggioso per le organizzazioni con risorse limitate.
- Distribuzione: Gli sviluppatori possono accedere a Mistral-NeMo-Minitron 8B come microservizio NVIDIA NIM con un’API standard o scaricarlo da Hugging Face. Questa flessibilità consente una facile integrazione nei sistemi e nelle applicazioni esistenti.
- Sicurezza: L’esecuzione del modello a livello locale sui dispositivi edge migliora la sicurezza dei dati, poiché le informazioni sensibili non devono essere trasmesse a server remoti.
Rilascio di modelli aggiuntivi
Insieme a Mistral-NeMo-Minitron 8B, NVIDIA ha introdotto anche Nemotron-Mini-4B-Instruct, un altro modello di linguaggio di piccole dimensioni ottimizzato per un basso utilizzo di memoria e tempi di risposta più rapidi. Questo modello è progettato per essere distribuito su PC e laptop NVIDIA GeForce RTX AI, espandendo ulteriormente l’accessibilità delle avanzate capacità di AI per gli sviluppatori.
I progressi di NVIDIA nei modelli di linguaggio di piccole dimensioni riflettono una tendenza in crescita nello sviluppo di AI, concentrandosi sulla fornitura di alte prestazioni pur rispettando i vincoli di dispositivi più piccoli e ambienti con risorse inferiori.