
Il 18 luglio 2024, Mistral AI e NVIDIA hanno annunciato congiuntamente il rilascio di Mistral NeMo, un modello linguistico all’avanguardia sviluppato attraverso i loro sforzi collaborativi.
Questo modello da 12 miliardi di parametri rappresenta un significativo progresso nella tecnologia AI, combinando l’esperienza di Mistral AI nell’addestramento dei dati con l’ecosistema hardware e software ottimizzato di NVIDIA.
Il modello è stato addestrato sulla piattaforma NVIDIA DGX Cloud AI, utilizzando 3.072 GPU Tensor Core H100 da 80 GB, che mostrano l’infrastruttura all’avanguardia alla base del suo sviluppo.
Progettato per prestazioni elevate in varie attività di elaborazione del linguaggio naturale, il modello eccelle nella generazione di testo, nella sintesi dei contenuti, nella traduzione delle lingue e nell’analisi del sentimento.
La sua finestra di contesto del token da 128K consente di elaborare informazioni estese e complesse in modo più coerente.
L’introduzione di Tekken , un nuovo tokenizzatore basato su Tiktoken, offre una compressione più efficiente di circa il 30% per il codice sorgente e diverse lingue principali, con guadagni ancora maggiori per coreano e arabo.
Inoltre , la consapevolezza della quantizzazione del modello durante l’addestramento consente l’inferenza FP8 senza compromettere le prestazioni, fondamentale per un’implementazione efficiente in contesti aziendali.
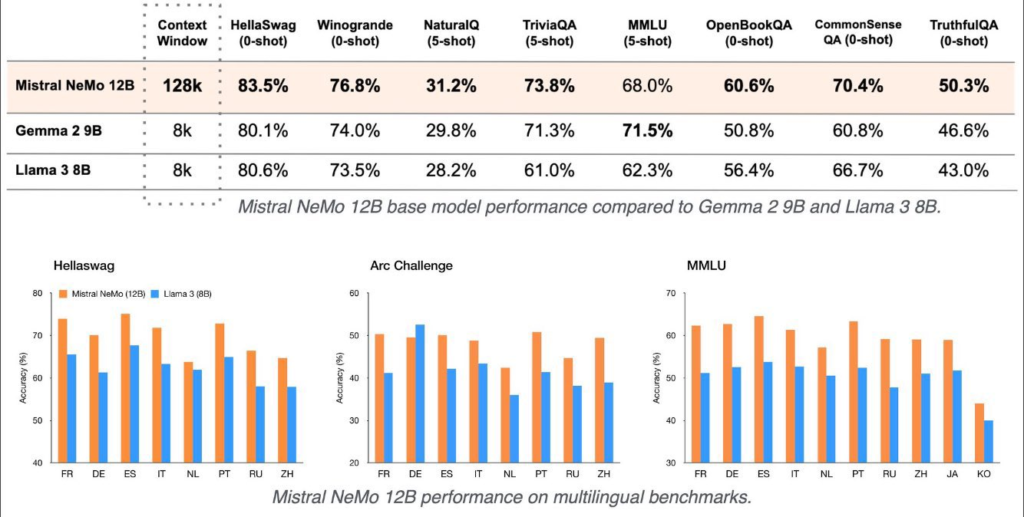
Mistral NeMo 12B offre prestazioni straordinarie rispetto ad altri modelli della stessa categoria. Secondo i benchmark, supera sia Gemma 2 (9B) che Llama 3 (8B) in termini di precisione ed efficienza.
Il suo prezzo competitivo di $0,3 per 1 milione di token input e output lo rende un’opzione favorevole rispetto a modelli più grandi come GPT-4 (contesto 32k) e Mixtral 8x22B, che sono notevolmente più costosi.
La finestra di contesto di 128K di Mistral NeMo e la tokenizzazione avanzata con Tekken gli conferiscono un vantaggio nella gestione di contenuti di formato lungo e attività multilingue, superando il tokenizzatore Llama 3 nella compressione del testo per circa l’85% delle lingue.
I pesi del modello per Mistral NeMo sono disponibili su HuggingFace, sia per la versione base che per quella di istruzione, offrendo agli sviluppatori un facile accesso alla tecnologia per una rapida implementazione.
Il modello può essere utilizzato con mistral-inference e personalizzato con gli strumenti mistral-finetune.
Per l’implementazione aziendale, Mistral NeMo è confezionato come un microservizio di inferenza NVIDIA NIM, disponibile su ai.nvidia.com
Progettato per funzionare su una singola GPU NVIDIA L40S, GeForce RTX 4090 o RTX 4500, il modello offre potenti funzionalità di intelligenza artificiale direttamente sui desktop aziendali, rendendolo altamente accessibile per diverse organizzazioni
Lascia un commento
Devi essere connesso per inviare un commento.