
Negli ultimi anni, la ricerca sull’intelligenza artificiale (IA) ha fatto passi da gigante, portando a innovazioni che un tempo erano considerate fantascienza. Uno degli ambiti più affascinanti e promettenti è la decodifica dell’attività cerebrale per ricostruire immagini direttamente dai pensieri.
Questo traguardo straordinario è reso possibile grazie a modelli di IA avanzati come Stable Diffusion, Generative Adversarial Networks (GANs) e sistemi sviluppati presso istituzioni accademiche di punta come l’Università di Osaka.

In questo articolo, esploreremo come questi modelli vengono impiegati per collegare i pattern dell’attività cerebrale con descrizioni testuali di immagini, permettendo la ricreazione di immagini viste dai partecipanti basandosi sulle loro scansioni cerebrali. Analizzeremo anche l’evoluzione di queste tecnologie, le sfide che affrontano e le potenziali applicazioni future.
Modelli di Diffusione Stabile (Stable Diffusion)
Stable Diffusion è una delle tecniche più recenti e avanzate nel campo della generazione di immagini a partire da descrizioni testuali. Questo modello, simile a DALL-E 2 e Midjourney, è stato adattato per lavorare con i dati dell’attività cerebrale. La sua applicazione in questo contesto rappresenta un significativo passo avanti nella neurotecnologia.
Meccanismo di Funzionamento
Stable Diffusion utilizza un processo di diffusione inversa per generare immagini. Partendo da un rumore casuale, il modello applica una serie di trasformazioni incrementali guidate da un modello di rete neurale addestrato su un vasto dataset di immagini e descrizioni testuali. Nel contesto della decodifica cerebrale, i dati raccolti tramite scansioni cerebrali vengono tradotti in una rappresentazione che il modello può utilizzare come input, permettendo così la ricostruzione dell’immagine vista dal soggetto.
Applicazioni e Risultati
L’uso di Stable Diffusion nella decodifica dell’attività cerebrale ha portato a risultati promettenti. Gli esperimenti hanno dimostrato che è possibile ricreare immagini con un alto grado di somiglianza rispetto a quelle originali viste dai partecipanti. Questo risultato apre la strada a molteplici applicazioni, come la comunicazione assistita per persone con disabilità gravi, la comprensione approfondita dei processi cognitivi e lo sviluppo di nuove interfacce cervello-computer.
Generative Adversarial Networks (GANs)
Le Generative Adversarial Networks (GANs) rappresentano un’altra classe di modelli di IA che sono stati ampiamente utilizzati per la generazione di immagini. Le GANs consistono in due reti neurali principali: il generatore e il discriminatore.
Struttura e Funzionamento
Il generatore crea immagini a partire dai dati di input, che in questo caso sono i pattern dell’attività cerebrale. Il discriminatore, d’altra parte, valuta la somiglianza tra le immagini generate e quelle originali. Durante l’addestramento, queste due reti si sfidano in un gioco a somma zero: il generatore cerca di migliorare continuamente le immagini che produce, mentre il discriminatore tenta di diventare sempre più abile nel distinguere le immagini generate da quelle reali.
Innovazioni e Prestazioni
Negli ultimi anni, le GANs hanno subito notevoli miglioramenti, diventando uno strumento estremamente potente per la decodifica dell’attività cerebrale. L’approccio combinato del generatore e del discriminatore ha permesso di raggiungere una precisione sempre maggiore nella ricostruzione delle immagini, rendendo possibile la creazione di rappresentazioni visive che rispecchiano accuratamente ciò che una persona ha visto o immaginato.
Questo studio dimostra l’uso delle GANs per decodificare l’attività cerebrale e ricostruire immagini visive : Visual Decoding with GANs
Progetto Mind-reading AI (2021): Un’illustrazione di come le GANs possono essere utilizzate per leggere la mente e creare immagini dettagliate basate su pensieri e ricordi.
- Mind-reading AI Using GANs Attached (Essays)
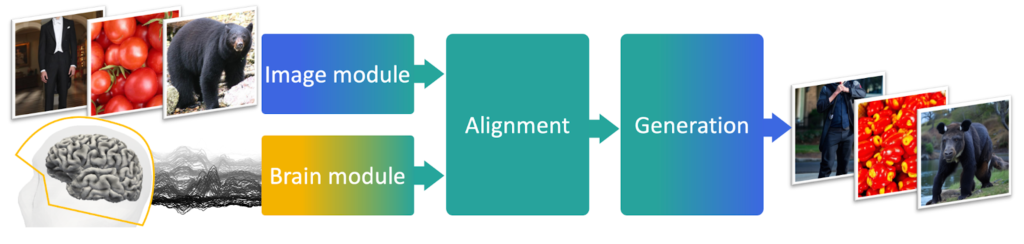
Qui trovate in interessante studio di META : Toward a real-time decoding of images from brain activity
Sistema Integrato dell’Università di Osaka
Un ulteriore avanzamento significativo è stato realizzato dai ricercatori dell’Università di Osaka. Questo team ha sviluppato un sistema che combina sia informazioni visive che testuali per migliorare l’accuratezza dell’interpretazione delle scansioni cerebrali. (attached)
Metodologia e Risultati
Il sistema dell’Università di Osaka utilizza una combinazione di reti neurali convoluzionali per l’elaborazione delle immagini e modelli di linguaggio naturale per l’analisi testuale. Questo approccio integrato consente al sistema di considerare un contesto più ampio e di utilizzare informazioni aggiuntive per affinare le sue ricostruzioni. Grazie a questo metodo, il team è riuscito a raggiungere un’accuratezza fino all’80% nella ricostruzione delle immagini, un risultato che rappresenta un enorme passo avanti rispetto alle tecnologie precedenti.
Per maggiori dettagli e per accedere allo studio completo, puoi consultare i seguenti link: Pagina del progetto su Google Sites
Sfide e Prospettive Future
Nonostante i progressi impressionanti, ci sono ancora numerose sfide da affrontare nel campo della decodifica dell’attività cerebrale. La complessità dei segnali cerebrali, la necessità di dataset di addestramento di alta qualità e l’interpretazione accurata delle intenzioni cognitive sono solo alcune delle problematiche che i ricercatori devono superare.
Sfide Tecnologiche
- Qualità dei Dati: La precisione delle ricostruzioni dipende in larga misura dalla qualità dei dati raccolti. Migliorare le tecnologie di imaging cerebrale e ridurre il rumore nei dati è essenziale per avanzamenti futuri.
- Interfacce e Algoritmi: Sviluppare interfacce cervello-computer più efficienti e algoritmi che possano interpretare meglio i segnali cerebrali è cruciale. Gli attuali modelli necessitano di ulteriori ottimizzazioni per diventare pratici e applicabili su larga scala.
Prospettive Applicative
Le potenziali applicazioni di questa tecnologia sono vaste e rivoluzionarie:
- Medicina e Riabilitazione: La decodifica dei pensieri potrebbe trasformare le pratiche mediche, consentendo la comunicazione con pazienti affetti da sindromi locked-in o da altre gravi disabilità motorie.
- Interfacce Uomo-Macchina: Sviluppare interfacce più intuitive e dirette potrebbe rivoluzionare il modo in cui interagiamo con i dispositivi tecnologici, aprendo nuove frontiere per l’intrattenimento, l’educazione e il lavoro.
- Ricerca Neuroscientifica: Queste tecnologie offrono strumenti potenti per esplorare e comprendere meglio il cervello umano, fornendo nuove conoscenze sui processi cognitivi e percettivi.
Dispositivi di Interfaccia Cervello-Computer


- Caschetti EEG
- Descrizione: Caschetti dotati di elettrodi per la registrazione dell’attività elettrica cerebrale.
- Uso: Utilizzati per raccogliere dati EEG in tempo reale da soggetti umani.
- Sensori di MEG
- Descrizione: Dispositivi sensibili ai campi magnetici prodotti dall’attività cerebrale.
- Uso: Utilizzati per acquisire dati MEG ad alta risoluzione.
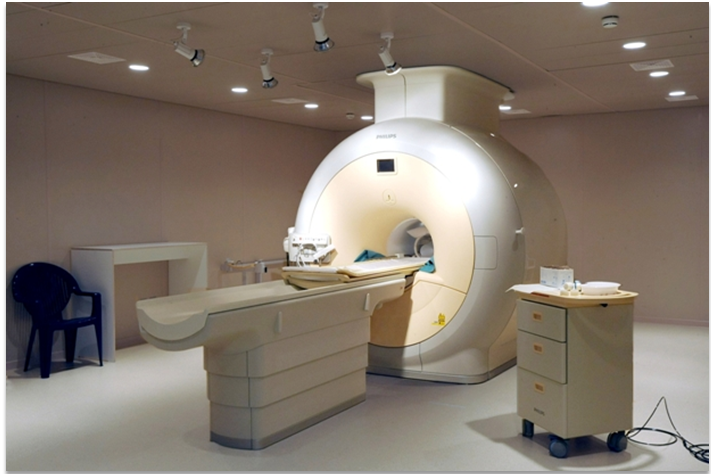
- Scanner fMRI
- Descrizione: Grandi macchine che utilizzano campi magnetici e onde radio per creare immagini dettagliate del cervello.
- Uso: Utilizzati per studi approfonditi della funzione cerebrale e per raccogliere dati per l’addestramento dei modelli di IA.
Conclusione
La decodifica dell’attività cerebrale per la ricostruzione delle immagini rappresenta uno degli sviluppi più affascinanti e promettenti nell’era dell’intelligenza artificiale. Con l’impiego di modelli come Stable Diffusion, GANs e i sistemi avanzati sviluppati all’Università di Osaka, siamo sempre più vicini a comprendere e replicare i processi visivi del cervello umano. Sebbene ci siano ancora molte sfide da affrontare, i progressi compiuti finora indicano un futuro in cui la mente e la macchina potrebbero lavorare in perfetta armonia, aprendo nuove possibilità per la medicina, la tecnologia e la comprensione scientifica.
Lascia un commento
Devi essere connesso per inviare un commento.