
La necessità di un Modello di Fondazione nella Previsione delle Serie Temporali
La previsione delle serie temporali gioca un ruolo cruciale in numerosi ambiti, dal piano della domanda nel retail e la previsione dei mercati finanziari fino alla meteorologia e alla gestione del traffico.
Mentre i modelli di deep learning hanno mostrato promesse in questo campo, spesso richiedono un addestramento esteso e una personalizzazione per ciascun compito specifico. TimesFM, sviluppato da Google Research, emerge come una soluzione interessante introducendo un approccio di modello di fondazione per la previsione delle serie temporali.
I modelli tradizionali di deep learning per la previsione delle serie temporali affrontano diverse sfide:
Addestramento Esteso: Ogni modello deve essere addestrato su un dataset specifico, richiedendo tempo e risorse computazionali significative.
Limitata Generalizzabilità: I modelli spesso faticano a generalizzare bene su dati non visti o su diverse attività di previsione.
Sforzo di Personalizzazione: Adattare i modelli a casi d’uso specifici comporta spesso un laborioso sintonizzazione degli iperparametri e modifiche all’architettura.
TimesFM affronta queste sfide adottando un approccio di modello di fondazione, simile al paradigma di successo dei grandi modelli linguistici (LLM) nel processamento del linguaggio naturale. Invece di addestrare modelli individuali per ciascun compito, TimesFM è pre-addestrato su un vasto dataset di dati temporali diversificati. Ciò gli consente di apprendere modelli temporali fondamentali e relazioni, consentendo la previsione senza addestramento aggiuntivo, ossia la capacità di generare previsioni accurate su dati non visti.
Architettura di TimesFM: Un Approccio Esclusivamente Decoder con Adattamenti Unici
L’architettura di TimesFM si ispira ai LLM mentre incorpora modifiche chiave per affrontare le sfide specifiche della previsione delle serie temporali:
Elaborazione Basata su Patch
Invece di elaborare singoli punti dati, TimesFM suddivide la serie temporale in patch (gruppi di punti temporali consecutivi).
Questo approccio, analogo alla tokenizzazione nei LLM, consente al modello di catturare dipendenze e tendenze a lungo termine all’interno dei dati.
La dimensione delle patch rappresenta un compromesso: le patch più grandi catturano più contesto ma potrebbero trascurare dettagli fini, mentre le patch più piccole conservano i dettagli ma potrebbero trascurare tendenze più ampie. Il design di TimesFM bilancia attentamente questi fattori.
Modello Esclusivamente Decoder
Come nei LLM, TimesFM adotta un’architettura esclusivamente decoder. Ciò significa che il modello predice valori futuri (l’orizzonte) basandosi solo sulle osservazioni passate (il contesto).
Questa scelta di progettazione facilita il processamento parallelo e consente al modello di gestire efficacemente lunghezze di contesto variabili.
Patch di Output più Lunghe
TimesFM consente patch di output più lunghe rispetto alla lunghezza delle patch di input. Ciò significa che il modello può prevedere simultaneamente più punti temporali futuri, rendendolo particolarmente efficiente per compiti di previsione a lungo termine.
Questa scelta di progettazione bilancia la necessità di accuratezza con la capacità di gestire serie temporali più brevi, dove prevedere orizzonti eccessivamente lunghi potrebbe non essere pratico.
Mascheramento delle Patch
Per impedire al modello di adattarsi troppo a lunghezze di contesto specifiche che sono multipli della lunghezza della patch di input, TimesFM utilizza una strategia casuale di mascheramento durante l’addestramento.
Questa tecnica garantisce che il modello sia esposto a varie lunghezze di contesto e impari a generalizzare efficacemente in diversi scenari di previsione.
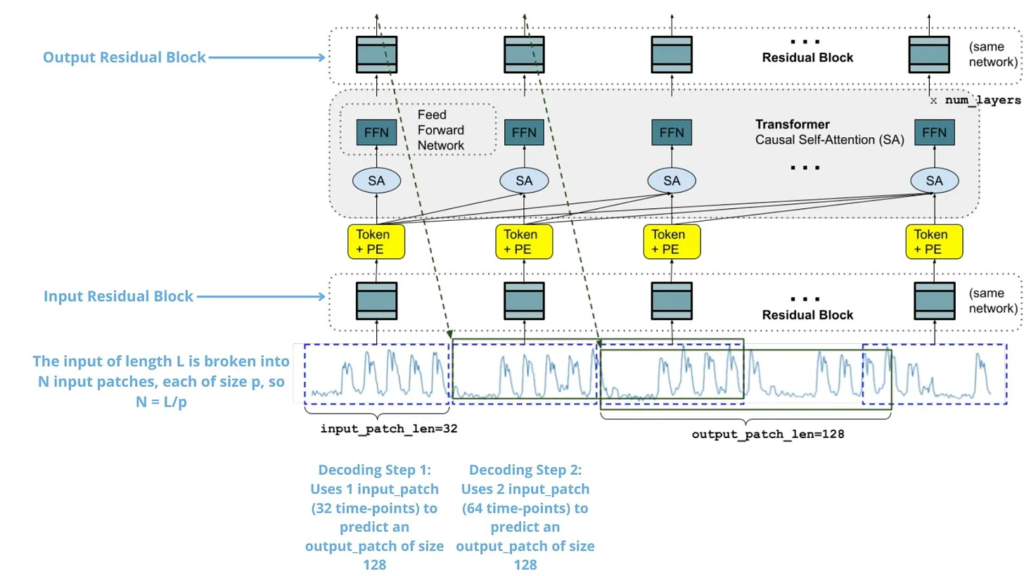
L’architettura complessiva è mostrata nella seguente immagine. In essa, possiamo vedere come una serie temporale di input viene suddivisa in patch, elaborate e alimentate attraverso i livelli del trasformatore per generare previsioni per i punti temporali futuri.
Architettura di TimesFM
In pratica, la serie temporale di input viene prima suddivisa in patch non sovrapposte. Ogni patch viene quindi elaborata attraverso un blocco residuale, essenzialmente un perceptron multistrato (MLP) con una connessione di salto. Questo trasforma la patch in una rappresentazione vettoriale adatta per i livelli del trasformatore. Inoltre, vengono aggiunte codifiche posizionali (PE) per fornire informazioni sull’ordine temporale delle patch all’interno della serie.
Queste patch elaborate vengono quindi alimentate in una serie di livelli del trasformatore, ognuno dei quali consiste in autoattenzione causale a più teste e reti feed-forward. Il meccanismo di attenzione causale garantisce che ciascun token di output si riferisca solo ai token precedenti nella sequenza, preservando l’ordine temporale dei dati.
Infine, un altro blocco residuale mappa i token di output dai livelli del trasformatore alle previsioni per la prossima patch di output. È importante notare che la lunghezza della patch di output può essere maggiore della lunghezza della patch di input, consentendo previsioni efficienti e accurate a lungo termine.
Dati di Addestramento: Un Mix di Dati Reali e Sintetici
I dati di pretraining di TimesFM comprendono un vasto corpus di 100 miliardi di punti temporali, accuratamente selezionati per garantire diversità e completezza:
Dati Reali: Questi includono dati da fonti come Google Trends (interesse di ricerca nel tempo), visualizzazioni delle pagine di Wikipedia, modelli di traffico, consumo di elettricità e vari altri dataset pubblici. Ciò espone il modello a tendenze reali, stagionalità e rumore.
Dati Sintetici: Per integrare i dati reali e assicurare una copertura di diversi modelli temporali, TimesFM incorpora serie temporali generate sinteticamente. Queste serie vengono create utilizzando modelli statistici e simulazioni, comprendendo tendenze, stagionalità e pattern di rumore.
Il processo di addestramento coinvolge:
Mixaggio dei Dati: TimesFM è addestrato su un mix dell’80% di dati reali e del 20% di dati sintetici, fornendo un ambiente di apprendimento bilanciato.
Bilanciamento della Granularità: I dati reali vengono campionati per garantire una rappresentazione equa di diverse granularità temporali (ad esempio, orari, giornalieri, settimanali, mensili).
Adattamento della Lunghezza del Contesto: La lunghezza massima del contesto durante l’addestramento viene adattata in base alla granularità dei dati, consentendo un apprendimento efficiente su vari scale temporali.
Normalizzazione: I dati vengono normalizzati per standardizzare l’input e migliorare la stabilità dell’addestramento.
Performance Zero-Shot: Impressionanti Risultati su Dati Non Visti
La performance di TimesFM è valutata su vari dataset di benchmark, dimostrando la sua capacità di generalizzare a dati non visti e ottenere risultati competitivi:
Monash Forecasting Archive: TimesFM supera molti modelli di base, inclusi metodi statistici e modelli di deep learning supervisionati, dimostrando le sue superiori capacità di previsione zero-shot.
Libreria Darts: TimesFM si comporta in modo competitivo e è statisticamente all’altezza dei migliori modelli di questa collezione, nonostante il minor numero di serie temporali nel benchmark.
Dataset Informer: TimesFM dimostra una performance eccezionale nei compiti di previsione a lungo termine, prevedendo temperature dei trasformatori elettrici con orizzonti di 96 e 192 punti temporali nel futuro, raggiungendo risultati paragonabili al modello PatchTST supervisionato di stato dell’arte. In particolare, supera le performance di llmtime, un modello basato sul linguaggio GPT-3, mostrando la sua efficacia ed efficienza nella gestione delle sfide di previsione a lungo termine.
Questi risultati evidenziano l’efficacia di TimesFM in diversi domini, granularità e orizzonti di previsione, consolidando la sua posizione come soluzione potente e versatile per la previsione.
Studi di Ablazione: Comprendere le Scelte di Progettazione
Sono stati condotti diversi studi di ablation per analizzare l’impatto delle diverse scelte di progettazione sulla performance di TimesFM:
Scaling: L’aumento delle dimensioni del modello porta a una migliore performance, suggerendo che ulteriori incrementi potrebbero aumentare ulteriormente l’accuratezza.
Decodifica Autoregressiva: Le patch di output più lunghe migliorano la performance, specialmente per la previsione a lungo termine, validando la scelta progettuale di TimesFM.
Lunghezza della Patch di Input: Una lunghezza intermedia della patch bilancia performance ed efficienza, dimostrando l’importanza di considerazioni di progettazione attente.
Ablazione del Dataset: Rimuovere i dati sintetici dal processo di addestramento porta a un calo delle performance, evidenziando il valore dei dati sintetici nell’apprendimento di diversi modelli temporali.
Considerazioni Etiche e AI Responsabile
Gli sviluppatori di TimesFM riconoscono le considerazioni etiche legate ai modelli di fondazione e sottolineano l’importanza delle pratiche di AI responsabile:
Privacy dei Dati: L’uso di dati pubblicamente disponibili e aggregati, insieme a tecniche di privacy differenziale, minimizza le preoccupazioni sulla privacy.
Mitigazione del Bias: L’apertura riguardo ai dati di addestramento e ai pesi del modello consente la scrutinio della comunità e aiuta a identificare e mitigare potenziali bias.
Trasparenza e Accessibilità: L’open-source del modello e la fornitura di documentazione dettagliata promuovono un uso responsabile e consentono ulteriori ricerche e sviluppi.
Utilizzo Pratico: TimesFM su GitHub
Il modello e il codice di TimesFM sono disponibili su GitHub e HuggingFace, consentendo agli utenti di sperimentarne le capacità:
Accesso ai Checkpoint: Il checkpoint iniziale del modello è accessibile attraverso il repository di Hugging Face.
Funzionalità: TimesFM esegue previsioni univariate delle serie temporali per vari contesti e lunghezze dell’orizzonte, concentrandosi sulle previsioni puntuali.
Benchmarks ed Esempi: Il repository fornisce risultati di benchmark ed esempi per guidare gli utenti nell’applicazione del modello a diversi compiti di previsione.
Installazione e Utilizzo: Sono fornite istruzioni chiare per l’installazione e l’utilizzo, facilitando agli utenti l’avvio con TimesFM.
Conclusione
TimesFM rappresenta un notevole avanzamento nella previsione delle serie temporali, offrendo:
Generalizzazione Zero-Shot: Previsioni accurate su dati non visti senza necessità di addestramento estensivo.
Adattabilità: Gestione efficace di lunghezze di contesto e orizzonti di previsione variabili.
Efficienza: Architettura e processo di addestramento ottimizzati per previsioni efficienti.
Apertura e Trasparenza: Codice e dati pubblicamente disponibili promuovono pratiche di AI responsabile.
Google Research: Attualmente non esiste un repository specifico per TimesFM di Google Research come quello di Hugging Face. Le ricerche e i dettagli su TimesFM di solito sono pubblicati come paper accademici su siti come arXiv o sono descritti nei blog di Google AI. Puoi trovare le pubblicazioni recenti e ulteriori informazioni visitando il sito ufficiale di Google Research: Google AI Research.
Hugging Face: Su Hugging Face, puoi trovare il modello TimesFM e il suo codice sorgente, nonché esempi e risorse per iniziare a usarlo. Ecco il link al repository Hugging Face per TimesFM: TimesFM su Hugging Face.
Lascia un commento
Devi essere connesso per inviare un commento.